-
-
-
-
-
-
-
-
-
-
-
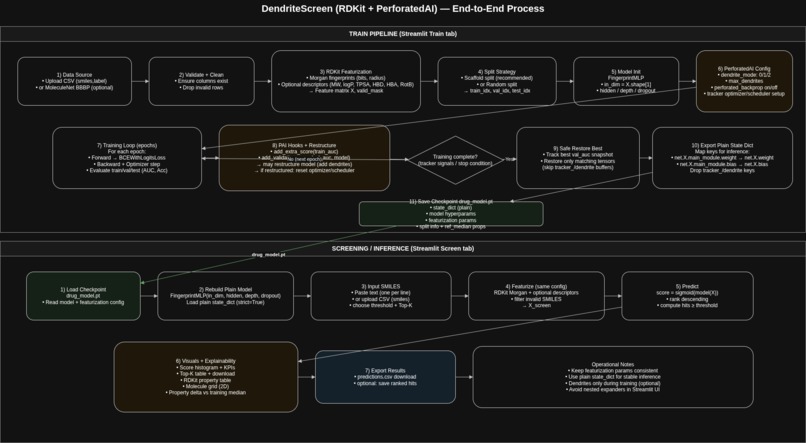
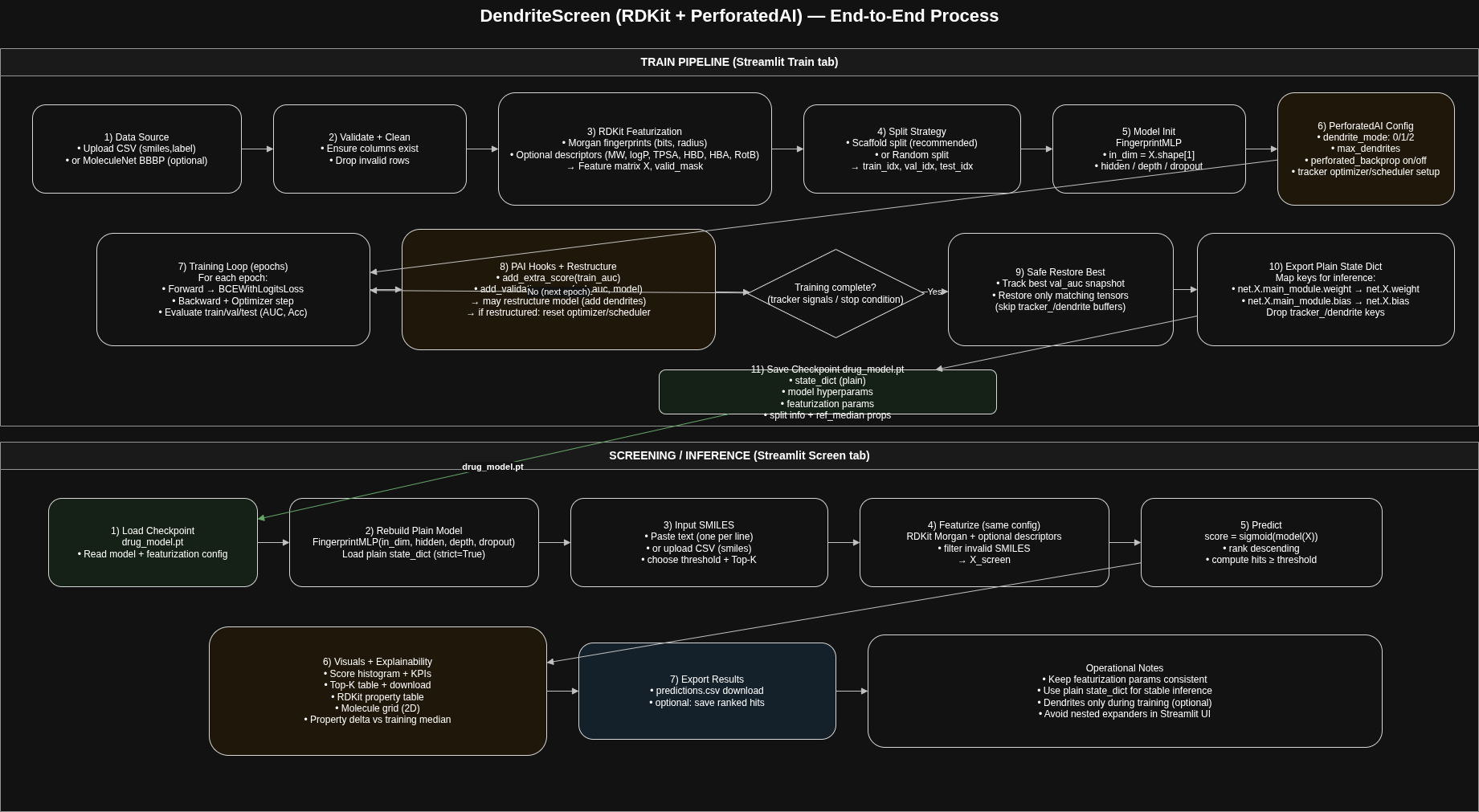
Flow diagram of the app
Inspiration
Most molecular screening demos stop at “predict a score,” but real users need trust, evaluation rigor, and interpretability signals. We were inspired to build a complete workflow: scaffold splitting, visual analytics of chemical space, and “why this hit” chemistry snapshots. PerforatedAI’s dendrites added a unique angle—dynamic architecture restructuring—to push performance and robustness without turning the app into a heavyweight platform.
What it does
The app trains and deploys a molecular screening model that predicts a target drug-development property (starting with BBB permeability) and uniquely supports PerforatedAI’s Dendritic Optimization during training.
RDKit featurization: Converts SMILES into Morgan fingerprints plus optional physicochemical descriptors (MW, logP, TPSA, HBD/HBA, RotB).
Two training modes:
Baseline MLP (fixed architecture), and
PerforatedAI Dendrites Mode where the network can add dendritic branches / restructure itself during training (GD dendrites or Perforated Backprop) to adapt capacity and improve learning under small/heterogeneous chemical datasets.
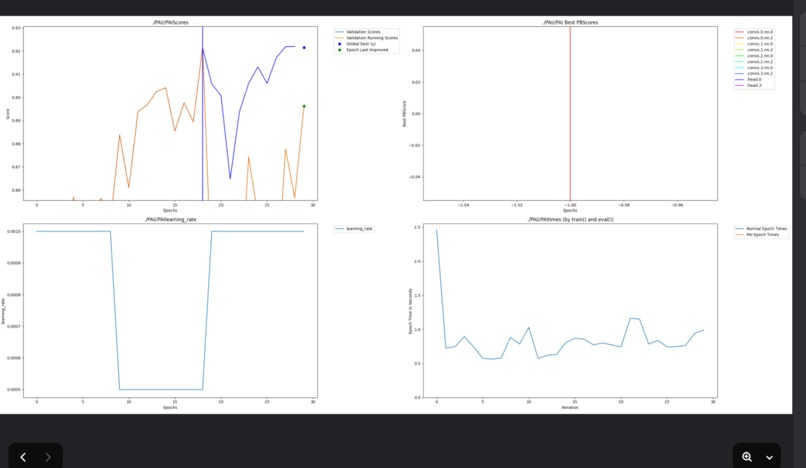
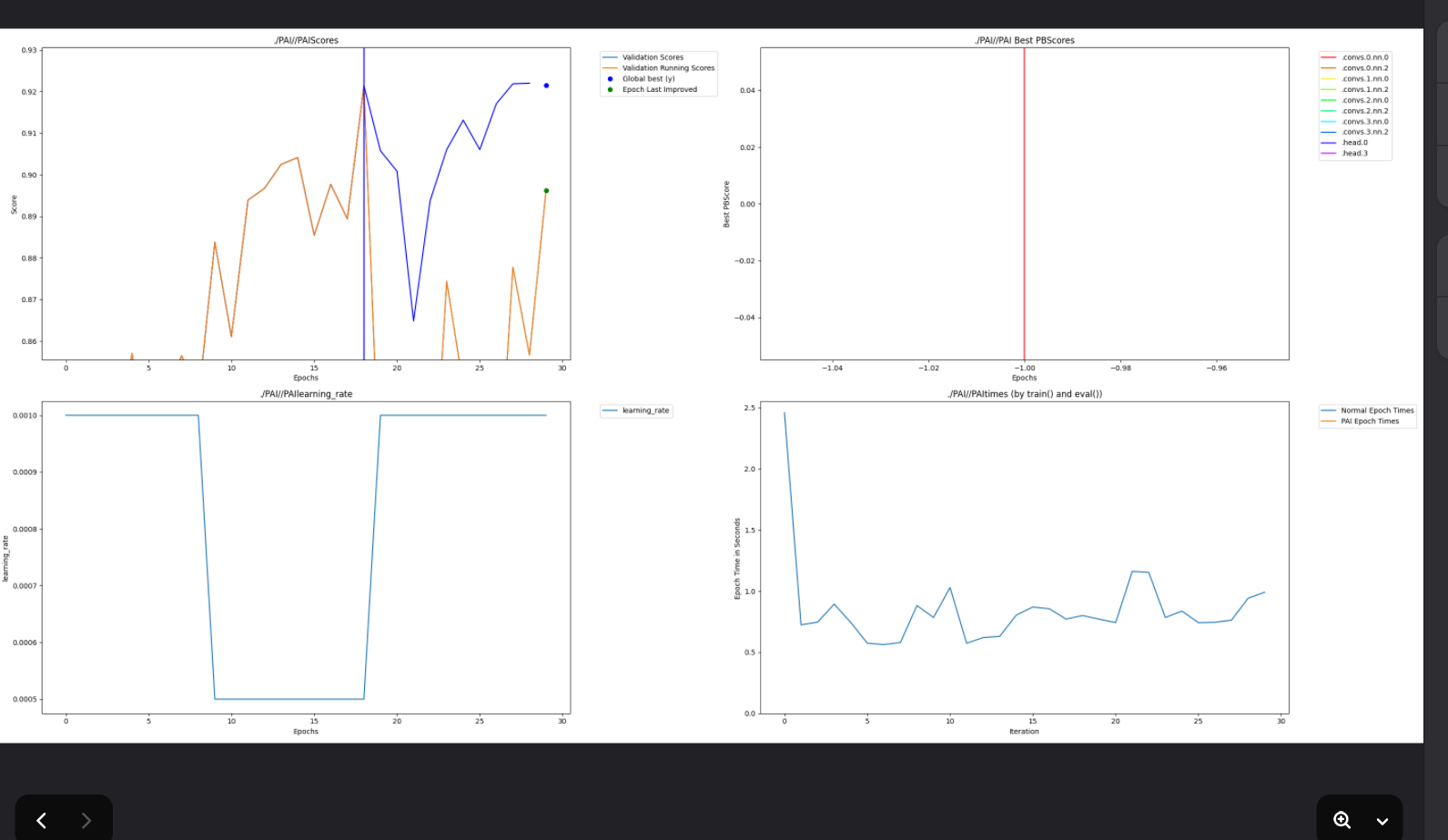
Tracker-driven optimization: Uses PerforatedAI’s training tracker to monitor validation improvements and trigger dendrite additions when beneficial—reducing manual architecture tuning.
Scientific evaluation: Scaffold/random split, ROC/AUC, confusion matrix, and learning curves to quantify gains from dendritic optimization.
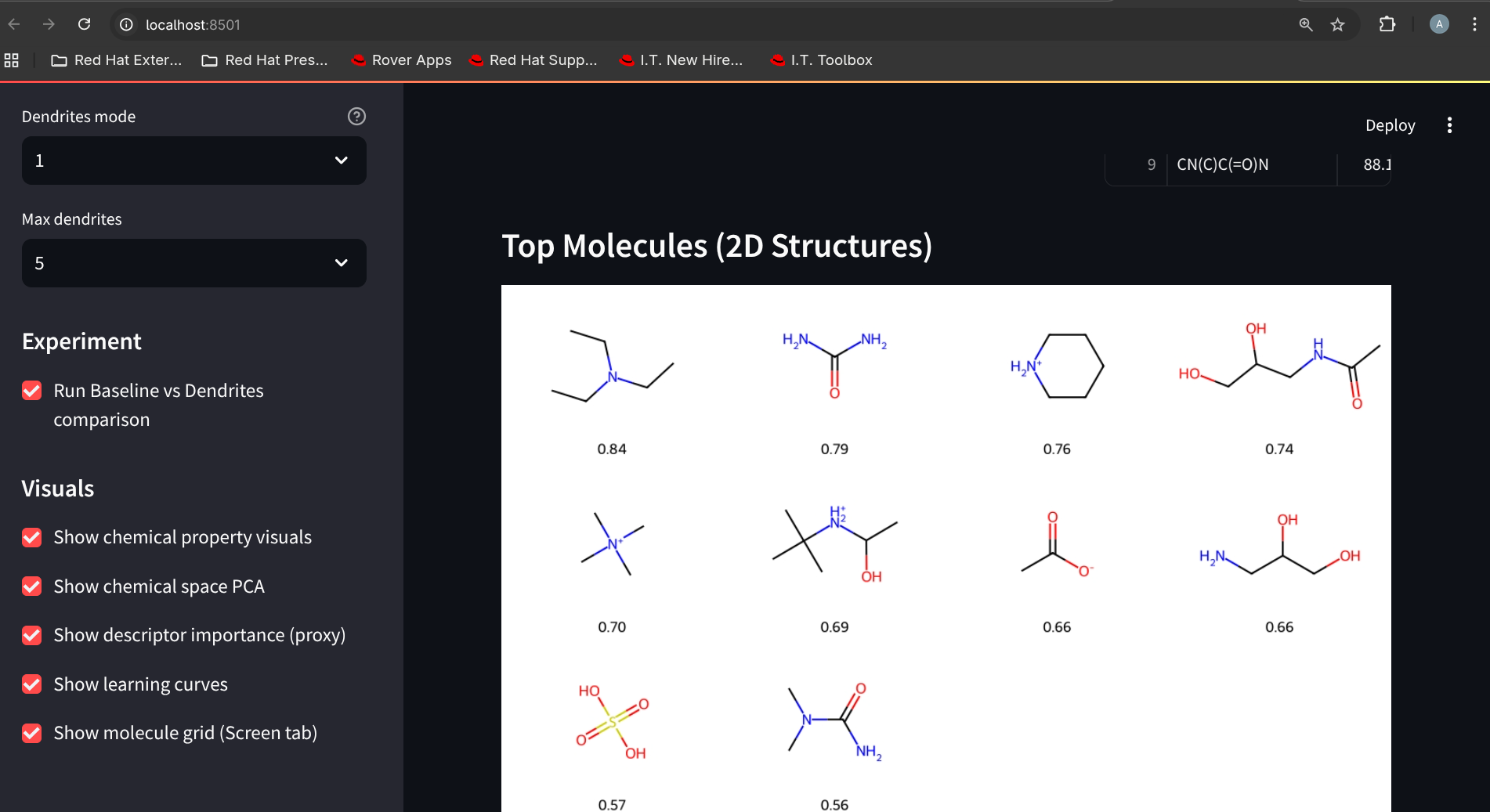
Practical screening workflow: Paste/upload SMILES → score and rank compounds → apply hit threshold → export predictions, with chemistry visuals and “why this hit” property snapshots for faster go/no-go decisions.
How we built it
1) Data ingestion
Built a Streamlit “Train” workflow that accepts:
CSV upload with smiles,label, and
optional MoleculeNet BBBP loader for a known benchmark dataset.
Standardized the dataset (column checks, label casting, invalid row handling).
2) Chemistry feature engineering (RDKit)
Converted SMILES → RDKit molecules and computed:
Morgan fingerprints (configurable bits/radius) as the primary representation.
Optional physicochemical descriptors (MW, logP, TPSA, HBD/HBA, rotatable bonds) to improve signal and enable interpretability visuals.
Filtered invalid SMILES and kept a validity mask so labels and features remain aligned.
3) Scientifically robust splitting
Implemented scaffold split (preferred for chemistry tasks) to avoid overly optimistic results from random splits.
Kept a fallback random split for quick demos.
4) Predictive model
Built a compact PyTorch MLP (FingerprintMLP) tuned for fingerprint vectors:
configurable hidden size, depth, dropout
binary classification using BCEWithLogitsLoss
Added a “comparison mode” to run:
Baseline training vs
Dendrites training on the same split/config.
5) PerforatedAI integration (the core novelty)
Wrapped the model using PerforatedAI utilities (initializePB or initialize_pai).
Enabled dendritic optimization via GPA.pc configuration:
dendrites off / GD dendrites / Perforated Backprop (PB)
configurable max dendrites and graph mode
During training each epoch:
reported training score using GPA.pai_tracker.add_extra_score(...)
reported validation score using GPA.pai_tracker.add_validation_score(...)
if the tracker restructured the model, we re-initialized optimizer/scheduler safely.
6) Robust checkpointing (handling restructuring)
Because PerforatedAI may add dendrite modules and tracker buffers (changing state_dict keys/shapes), we implemented:
safe restore of the best checkpoint (load only matching keys/shapes)
export of a plain state_dict (mapping main_module.weight → weight, dropping dendrite/tracker tensors) so the Screen tab can always reload a stable “vanilla” model for inference.
7) Streamlit UX + visualization
Built two main tabs:
Train: data preview, featurization settings, split choice, training run, metrics summary.
Screen: paste/upload SMILES, score, rank, threshold hits, download results.
Added visuals to make it decision-friendly:
learning curves (train/val/test AUC, accuracy)
ROC/AUC and confusion matrix
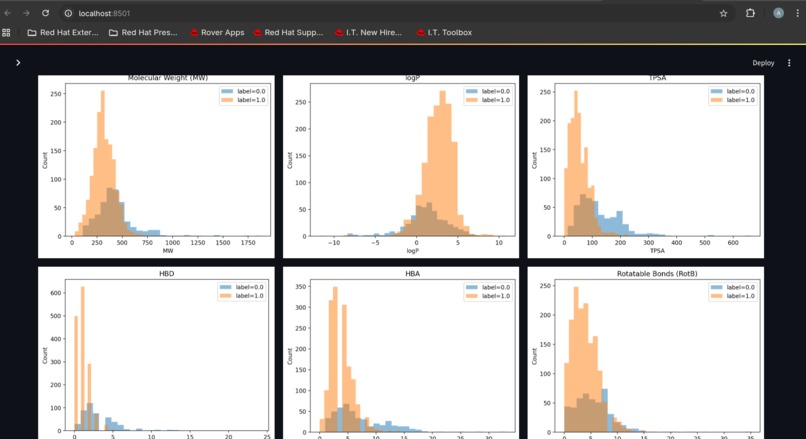
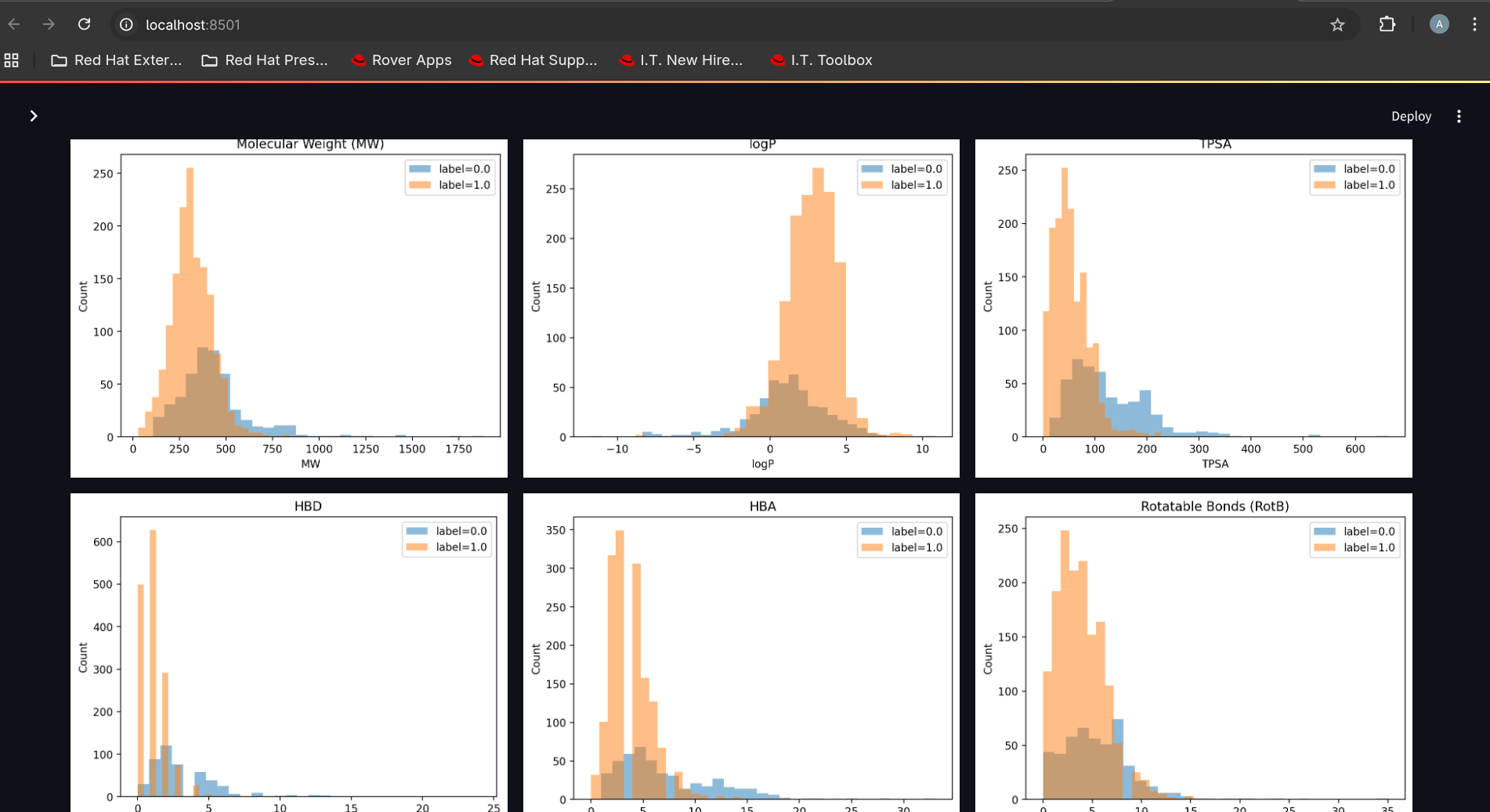
chemistry property distributions (MW/logP/TPSA/HBD/HBA/RotB)
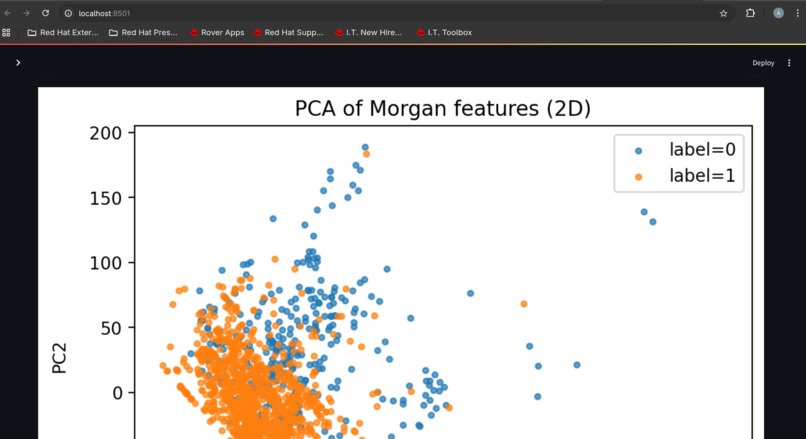
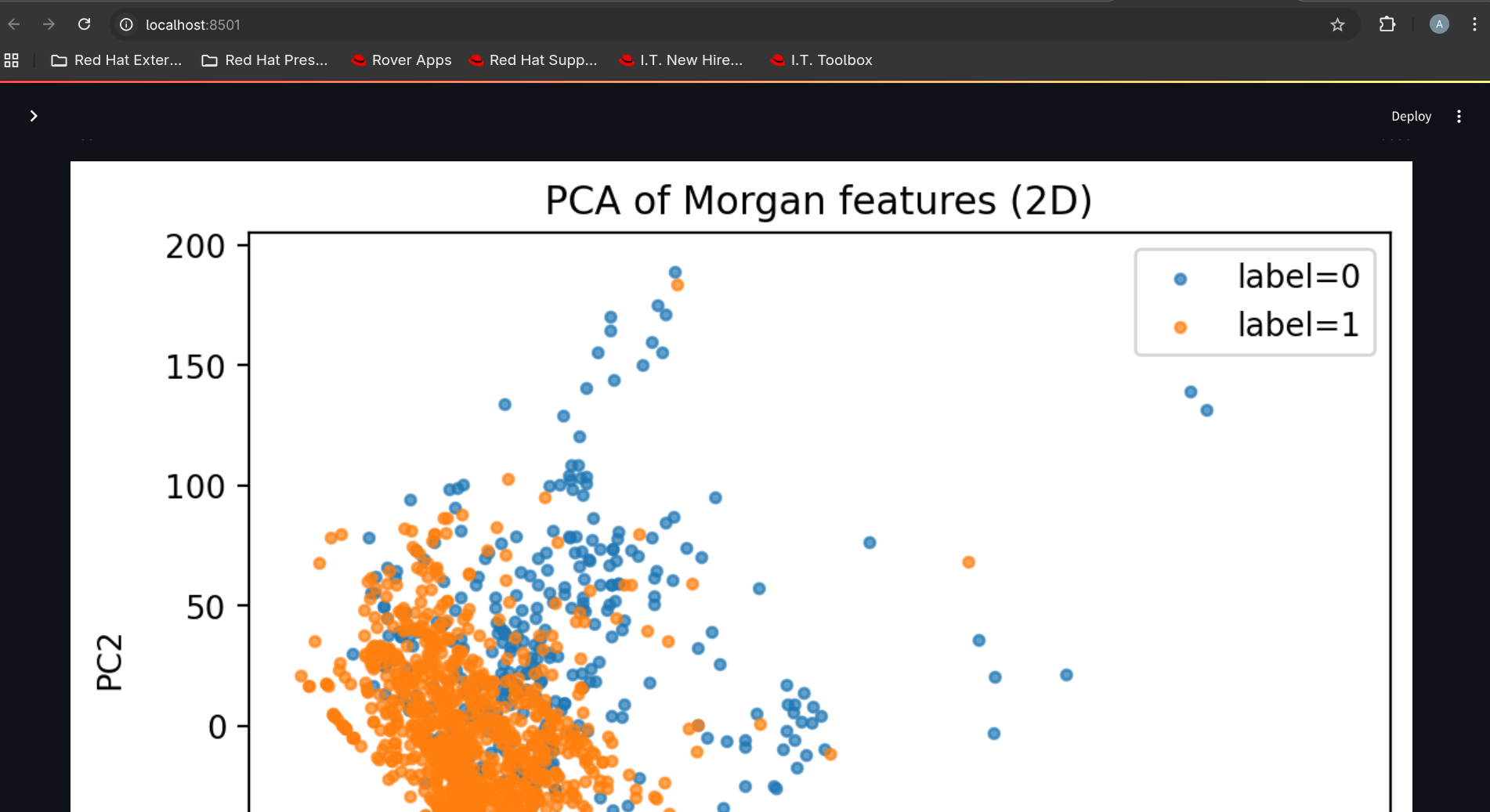
PCA projection for chemical space
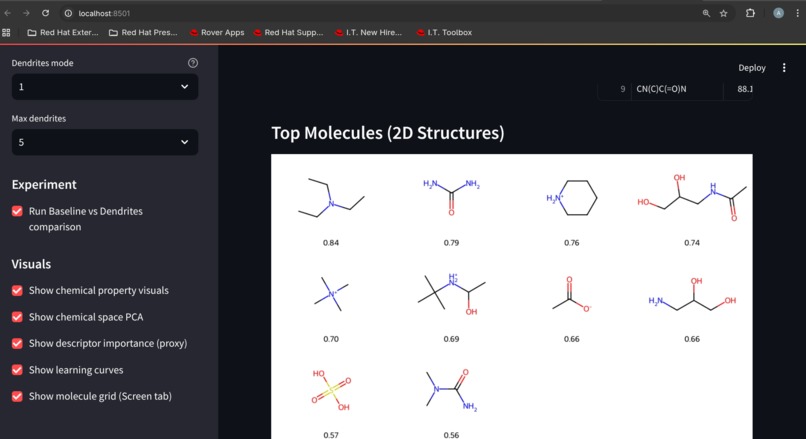
top-hit molecule grid rendering via RDKit
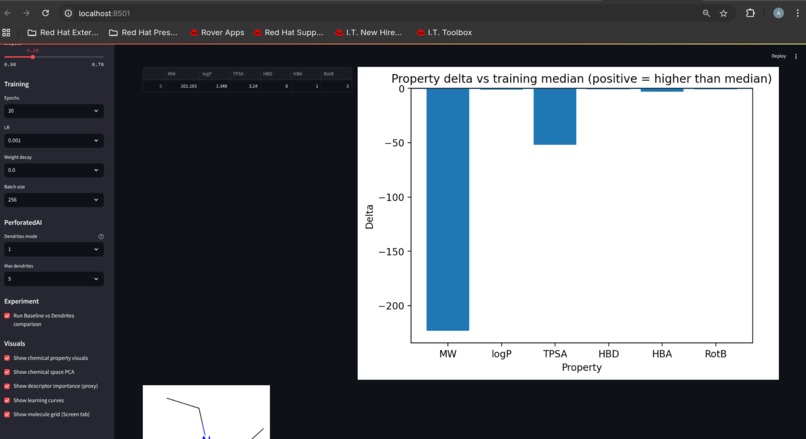
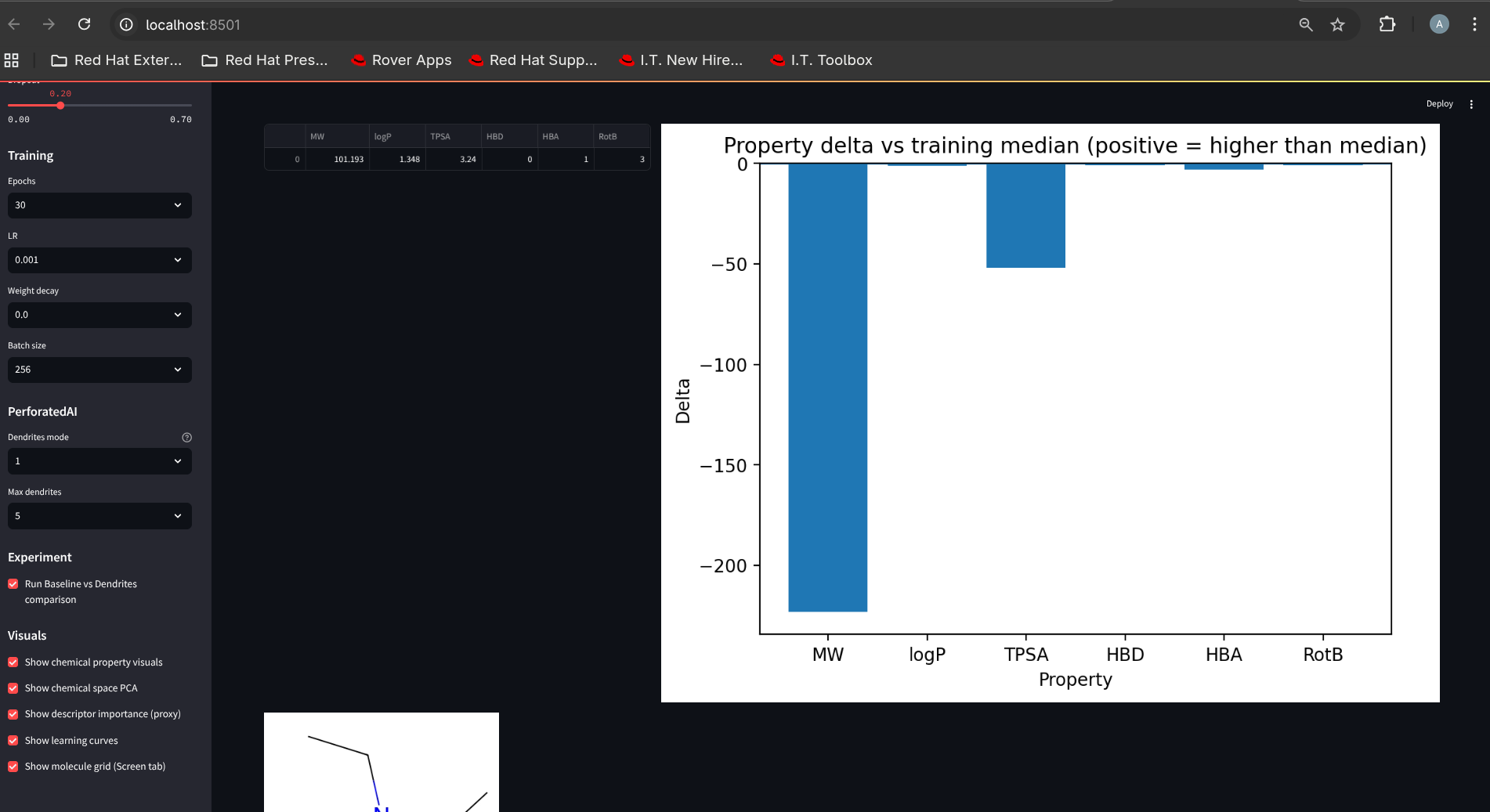
“why this hit” snapshot comparing properties vs training medians
8) Packaging & reproducibility
Organized code into modular files:
data loading, featurization, splitting, model definition, PerforatedAI training loop, and the Streamlit app.
Provided a demo dataset CSV and exportable predictions for easy evaluation and presentation.
Challenges we ran into
Model restructuring breaks checkpoint loading (PerforatedAI-specific) PerforatedAI can dynamically restructure the network during training (adding dendrites / wrapping layers). This changes state_dict keys and tensor shapes (e.g., tracker_, dendrite_, main_module.*), which caused runtime errors when restoring “best model” checkpoints or loading models for inference.
Inference-time compatibility (plain model vs dendrite-wrapped model) For a clean Streamlit “Screen” tab, we wanted inference to run on a stable, vanilla FingerprintMLP. But dendrite-wrapped training creates parameters like net.0.main_module.weight instead of net.0.weight. We solved this by exporting a plain state_dict that maps main-module weights/biases back to standard names and drops tracker/dendrite buffers.
Safe “best checkpoint restore” under dynamic architectures A strict load_state_dict(strict=True) fails when the architecture changes mid-training. We implemented a safe restore routine that only loads tensors where both the key exists and the shape matches, skipping mismatches automatically.
Streamlit UI constraints (nested UI elements) Streamlit does not allow expanders inside other expanders, and some layout patterns (e.g., replacing single elements with multiple elements) can throw exceptions. We refactored the UI into clear sections and ensured expanders were never nested.
Reliable evaluation on small / imbalanced data AUC fails when a split contains only one class. We added guards (NaN handling and safe scoring) and used scaffold split by default to avoid overly optimistic results, while ensuring each split remains usable.
SMILES validity and RDKit edge cases Real-world SMILES often include invalid strings, salts, or uncommon tokens. Invalid molecules can silently break featurization or descriptor computation. We added validity masks, skipped invalid entries, and ensured the app remains stable even with messy input.
Balancing “scientific depth” with usability A drug discovery tool must be credible (scaffold split, ROC/AUC, chemistry visuals), but also fast and easy to demo. We iterated on the UI to keep a clean workflow while still surfacing chemistry context, model metrics, and screening outputs in a decision-friendly way.
Accomplishments that we're proud of
PerforatedAI dendrites working end-to-end in a drug discovery workflow We successfully integrated PerforatedAI’s dendritic optimization into a chemistry ML pipeline so the model can dynamically restructure during training and still produce stable, usable results.
Solved the “dynamic architecture checkpoint” problem We implemented a robust checkpoint strategy:
safe restore of the best epoch even when the model structure changes, and
export of a plain inference state_dict so screening works reliably without PerforatedAI internals.
A complete “Train → Evaluate → Screen” product experience The Streamlit app isn’t just a notebook demo. It supports:
dataset upload, featurization controls, scaffold/random split, training runs, and
real screening with ranked outputs, hit thresholds, and downloadable predictions.
Chemistry-aware evaluation and visuals We included drug discovery–relevant outputs beyond accuracy:
ROC/AUC, confusion matrix, learning curves,
RDKit property distributions, PCA chemical space plots, and
molecule structure grids for top hits.
Decision support, not just prediction We added “why this hit” style context by comparing top hits’ physicochemical properties against training medians—helping users interpret results quickly and prioritize compounds for follow-up.
Designed for real-world messy inputs We handled invalid SMILES and edge cases gracefully, keeping the app stable even when users paste imperfect chemical strings or upload noisy CSVs.
Comparison mode for measurable impact We enabled a baseline vs dendrites comparison path so we can quantify whether dendritic optimization improves validation performance and stability for a given dataset and split.
What we learned
Dynamic architectures require “dynamic checkpointing” PerforatedAI’s dendrites can change the network structure during training, so standard load_state_dict(strict=True) workflows break. We learned to implement safe restore logic (key + shape matching) and to export a plain inference checkpoint.
Training-time wrappers and inference-time stability are different problems A dendrite-wrapped model is great for optimization, but a production-like screening app benefits from a stable, minimal inference graph. We learned to separate concerns: train with dendrites, deploy with plain weights.
Scaffold split is essential for credible chemistry ML Random splits can inflate performance because near-duplicate scaffolds leak across splits. Scaffold splitting gives a more realistic measure of generalization in drug discovery settings.
AUC is fragile on small/imbalanced splits AUC cannot be computed if a split contains a single class. We learned to add guards, report “NA” when appropriate, and monitor class distribution during splits.
RDKit pipelines must be defensive SMILES validity, salts, and unusual strings are common in real datasets. We learned to build robust featurization with validity masks and to keep the app stable even when inputs are messy.
Interpretability needs to be practical, not perfect True neural attributions can be heavy for an MVP. A fast proxy (descriptor-based logistic regression + chemistry property deltas) still provides meaningful insights and improves user trust and usability.
Streamlit UI design impacts reliability as much as code Certain UI patterns (nested expanders, replacing elements incorrectly) can crash the app. We learned to design sections cleanly, avoid unsupported nesting, and structure the interface to be maintainable.
Product framing matters for adoption Users don’t want “a model”—they want a workflow: upload → train → compare → screen → export. Building the end-to-end flow and visuals made the project substantially more compelling and usable.
What's next for DendriteScreen –PerforatedAI
Expand beyond BBBP to multi-task endpoints
Add common early discovery tasks: solubility, toxicity (e.g., hERG, Ames), CYP inhibition, clearance, bioavailability.
Support multi-task learning (one model predicting multiple properties) and per-task evaluation dashboards.
Upgrade the molecular representation
Offer alternatives to fingerprints:
Graph Neural Networks (GIN/GCN/MPNN) for structure-aware learning,
optional pretrained chemical embeddings (ChemBERTa / MolFormer) for better generalization.
Keep fingerprints as a fast baseline for CPU-friendly screening.
Make PerforatedAI the central differentiator
Add an “Architecture timeline” view: dendrites added per epoch, parameter growth, and validation jumps.
Provide a “Dendrites vs Baseline” automated report: best epochs, stability, compute cost, and gains.
Add recommended dendrite settings based on dataset size/imbalance (an “auto-tune” mode).
Richer interpretability and chemistry filters
Add substructure alerts (PAINS, Brenk filters) and Lipinski / Veber checks.
Provide counterfactual suggestions (e.g., “reduce logP / TPSA”) and similarity search to known actives.
Integrate fragment highlights or SHAP-style explanations for descriptor channels (lightweight MVP version first).
Library-scale screening features
Batch screening for 10K–1M SMILES with chunked inference, progress tracking, and caching.
Upload larger libraries, de-duplicate by canonical SMILES, and export ranked hit lists with metadata.
Data & MLOps readiness
Add experiment tracking (optional Weights & Biases) and reproducible configs.
Version datasets and models, store artifacts, and enable model cards (dataset provenance, split strategy, metrics).
Add CI tests for featurization, splitting, and checkpoint compatibility (especially across PerforatedAI restructuring).
Deployment pathway
Package as:
a Docker image with pinned RDKit/torch/perforatedai versions,
a lightweight API (FastAPI) + Streamlit UI, and
optional on-prem mode for sensitive pharma datasets.
Built With
- perforatedai
- pytorch
- rdkit
- scikitlearn

Log in or sign up for Devpost to join the conversation.