-
-
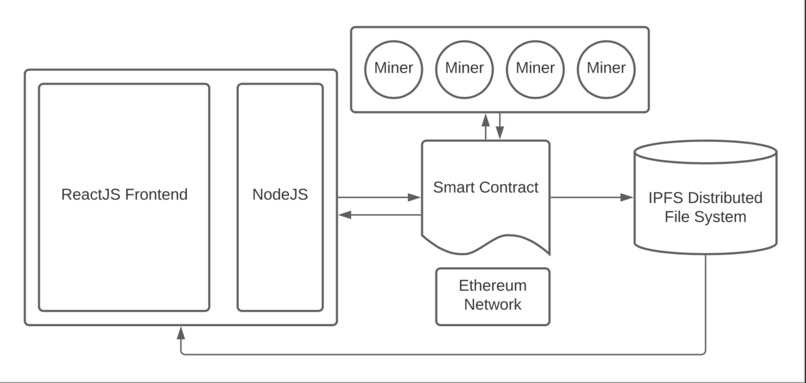
Project Flow and Tech
-
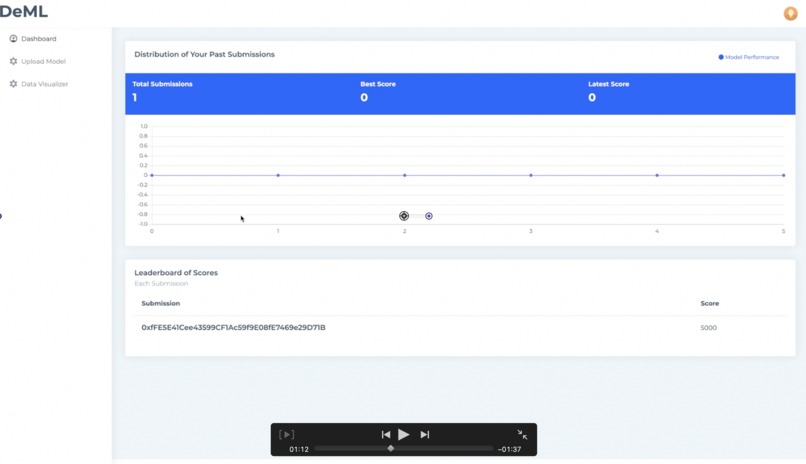
Website
-
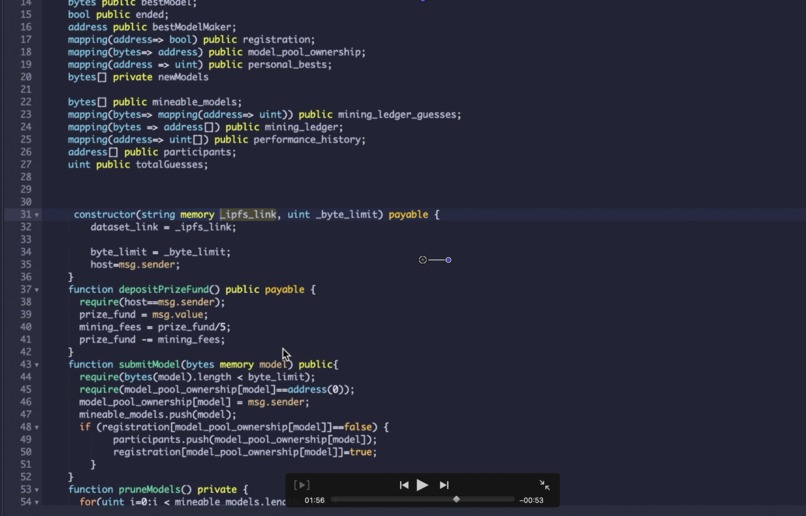
Smart Contract
Inspiration
Independently finding optimal patterns within a dataset is extremely challenging in many cases. The amount of computing necessary to train machine learning models is immense, and in addition, others may be able to find trends that the host did not foresee. In the case of sensitive data, dataset owners may not want to expose their identity and competitors likewise. Moreover, sometimes difficult political circumstances may make it harder for aspiring researchers to be able to find mathematical patterns in their models. We decided to create a platform that allows dataset owners to offload the training process among others on the web.
What it does
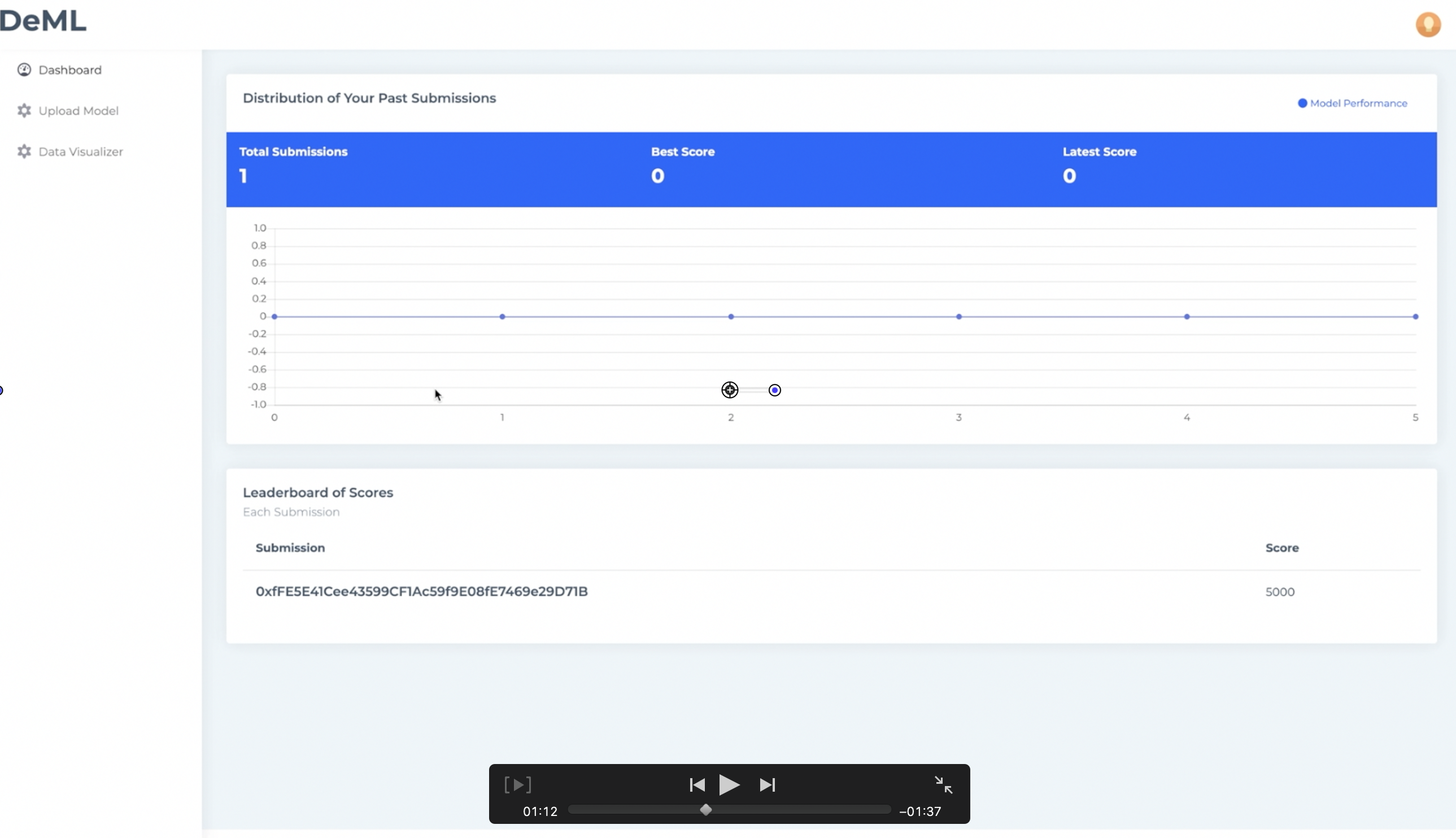
Our platform allows anonymous users to train models on a host-provided dataset and submit compressed model parameters to the blockchain to compete for the top test accuracy. The prize pool consists of an initial prize offered by the host in addition to buy-ins supplied by the individual competitors. The individual with the highest train accuracy wins 90% of the prize pool, with the remaining 10% of the prize pool being awarded to miners who work on validating the model accuracies.
We restrict the size of model parameters submitted to the blockchain to ensure that competitors cannot overfit their models to the dataset. As an individual can act as both a miner and a competitor, this prevents people from abusing access to both train and test datasets. Miners are responsible for retrieving submissions from the blockchain and ensuring that the test accuracies are indeed what was submitted to the network.
How we built it
There are three main components to our project: the smart contract + blockchain, miner pipeline + model API retrieval, and the frontend dashboard.
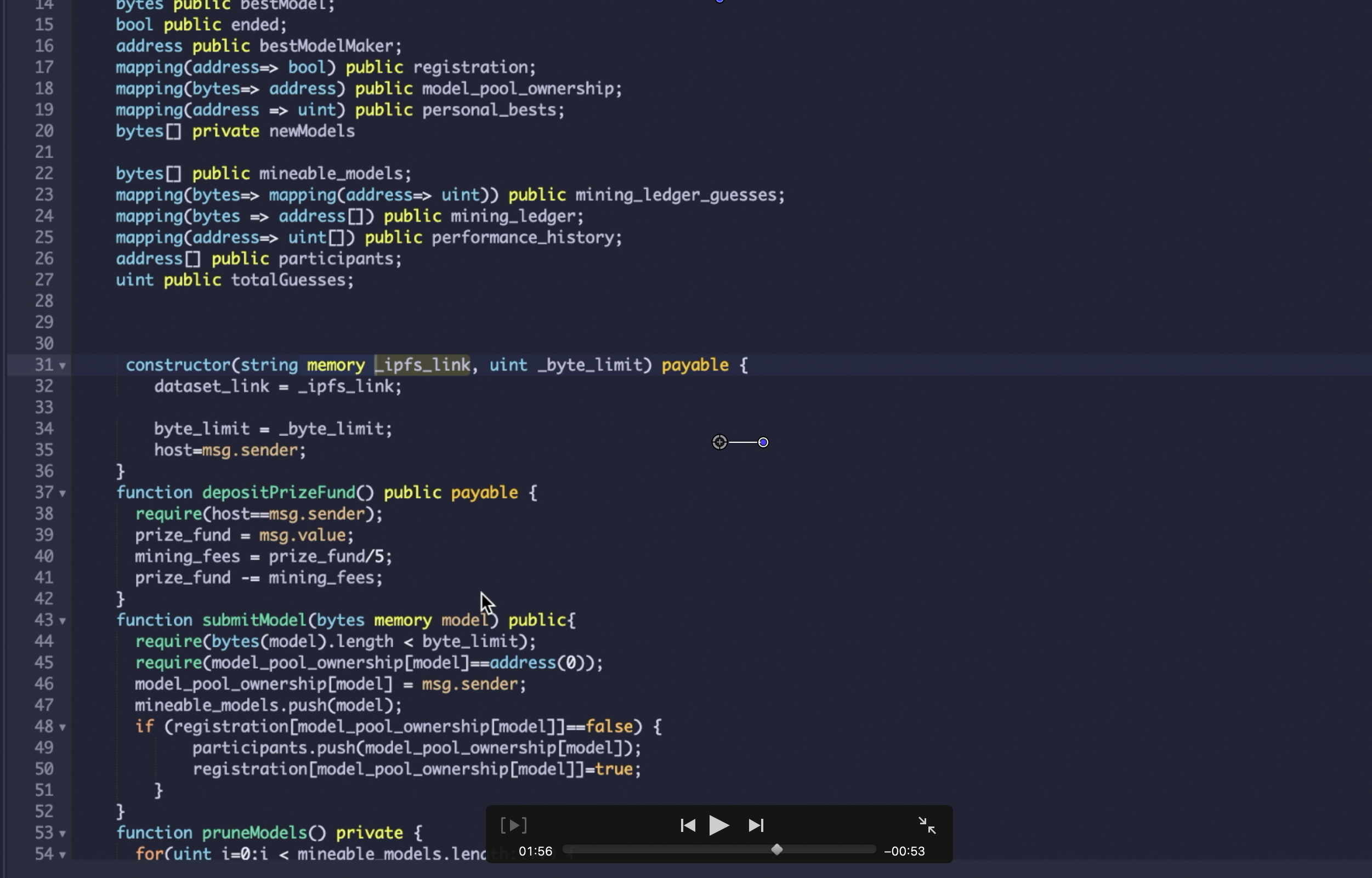
The first component of our project deals with the compression and submission of a competitors model parameters. We allow for the submission of models made with either PyTorch or Tensorflow. With both types of models, we provide a library for users to convert models into json files (in the case of Tensorflow) and then to a sequence of bytes. The decompression function utilizes the zlib library and decoding the byte string to a base 64 binary object file. The smart contract was built with solidity. More information about this on the video, however, the contract contains functions and variables which allow us to store and distribute machine learning models across miners.
For miners we provide a Python API to interact with the smart contract. Miners are able to retrieve a set of compressed models which are ready for evaluation and the dataset to evaluate on. The miner can pick any one of these models to evaluate but must use our compression and decompression schemes to retrieve the model and send its accuracy to the smart contract via our API. The accuracy of a model is considered validated if 51% of the miners who evaluated that model agree upon its accuracy.
Our dashboard visualization was made with React.js. To access our platform, competitors must provide an address that corresponds to the specific dataset of the competition. Once authenticated, users are able to see a graph of their past submissions, a current leaderboard,
Challenges we ran into
We ran into a large number of challenges during each step of our project.
For example, one of the largest ones was gas. Storing any kind of data will inevitably run into this problem, and its an especially annoying bug given that gas prices often fluctuate. However, we were able to deal with this in a few ways:
- Storing an IPFS link for the dataset on the blockchain instead of trying to compress the dataset and store it all on the blockchain. This was an extremely large improvement in gas prices.
- Limiting the byte size of models. In a straightforward way, this limited the total possible gas of the submitModel transaction.
Another major challenge we had was security. Specifically, how do we make sure no party to the contract can exploit any other. We initially thought about simply having one miner for each model, but we realized this was far too prone to manipulation; we needed to require multiple miners to balance it out. In order to further improve security for malicious miners, we also plan to add a system in which miners are only rewarded for their mining if they are within a certain threshold of the median submitted accuracy for a specific model over all miners. This goes some way towards averting Sybil attacks. We also envisioned adding some kind of proof of work algorithm for mining (such that running a model on a dataset could be turned into some easily verifiable proof that you did, indeed, run the model on the dataset), which would also combat Sybil attacks.
Finally, a big challenge we faced, especially near the end, was integration. We were integrating three different languages: Javascript (for the website), Solidity (for the contract), and Python (for miners). We had to deal with datatype and API differences between all 3, all while trying to work within the very strict confines of solidity (the lack of floating point numbers got us multiple times).
However, none of the challenges was ever overwhelming, and in the end, we were able to create a finished product.
What's next for DeML: Decentralized Machine Learning
Our goal is to take this, and bring it to the next level. Decentralize training and make compute a lot cheaper, but we're still a far way away.


Log in or sign up for Devpost to join the conversation.