-
-
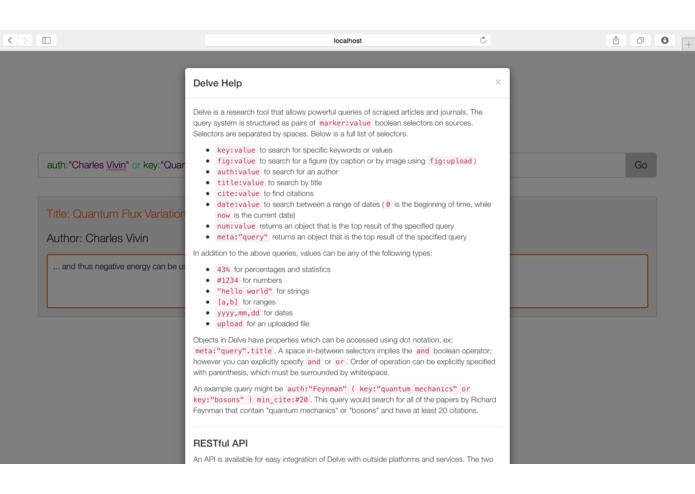
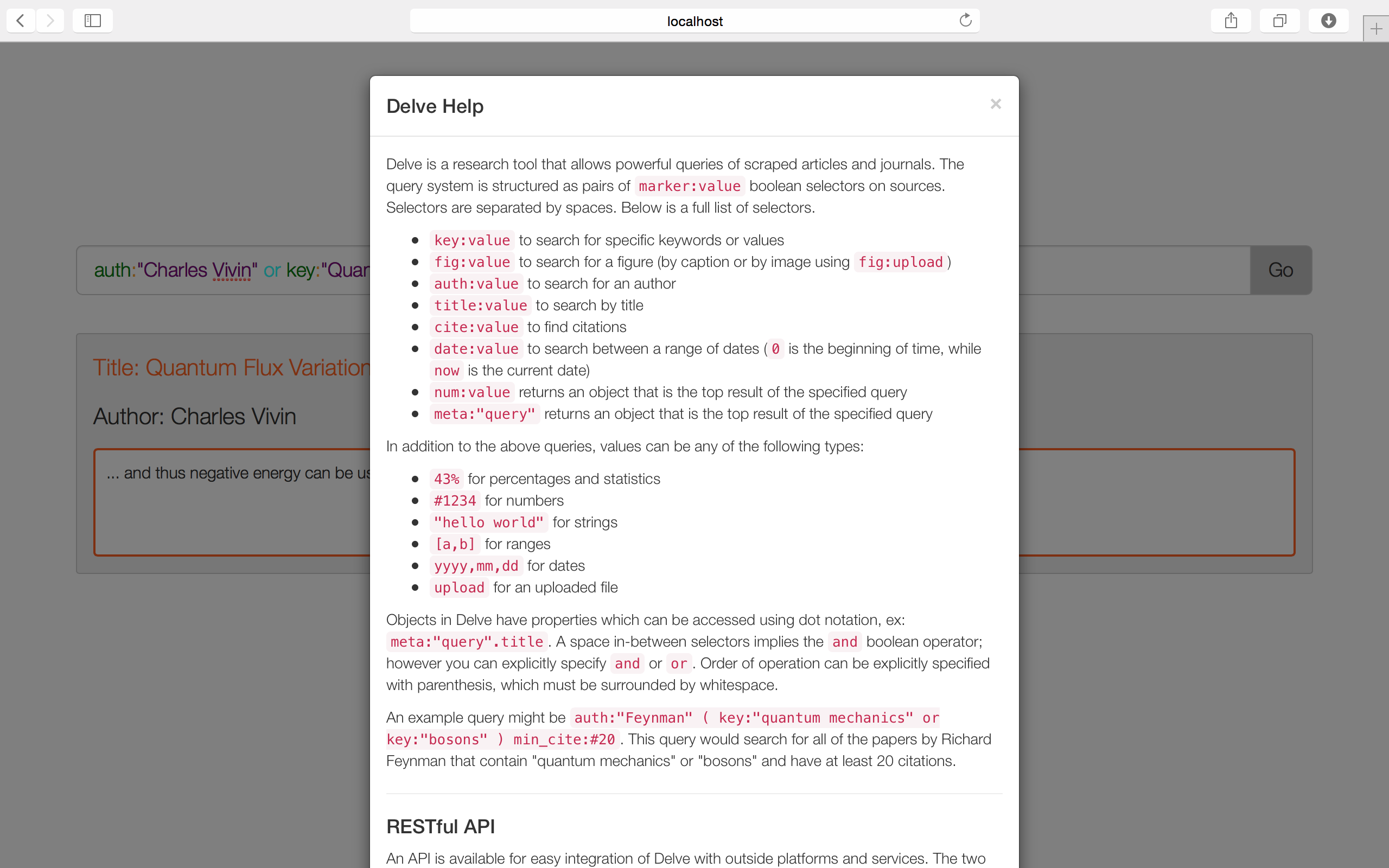
The help modal
Inspiration
As a group of debaters as well as programmers, we often found ourselves spending hours pouring over research pages, looking for studies relevant to the debate topics, and often settling for lesser sources than we would have liked, simply because research is such a time-consuming activity. We thought, "There has to be a better way," and upon failing to find a better way, decided to build it ourselves.
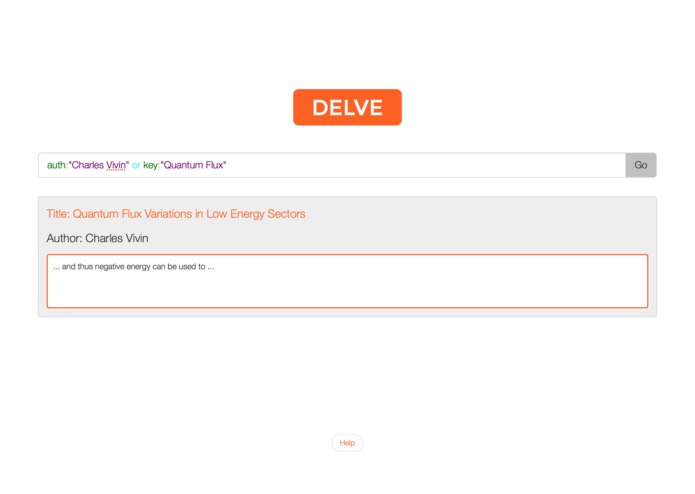
What it does
Delve.ninja browses, downloads, and indexes tens of thousands of academic articles. We provide a powerful language (specified on the site) for searching these articles for precisely what you desire to find.
How we built it
We use python to automatically download PDFs, and ElasticSearch, combined with some custom-built software for indexing PDFs. We use Perl and Parscite for parsing citations, and PHP for interacting with the mySQL database and parsing input. We used DigitalOcean for Ubuntu hosting.
Challenges we ran into
Many of the libraries we used required complex setup, and storing enormous quantities of files on an VPS turned out to be a huge headache.
Accomplishments that we're proud of
We're proud of getting a functional product!
What we learned
We learned that organization is incredibly important in building products, as is making deadlines and sticking to them.
What's next for Delve.ninja
We have some bug-fixes to run through, and we'd like to index additional archives (beyond arxiv) in the future.



Log in or sign up for Devpost to join the conversation.