-
-

REFERENCE_IMAGE
-
CURRENT_IMAGE
-
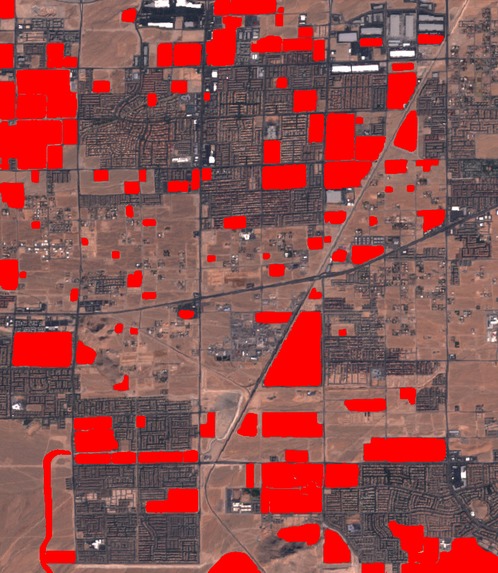
VISUAL_CHANGES

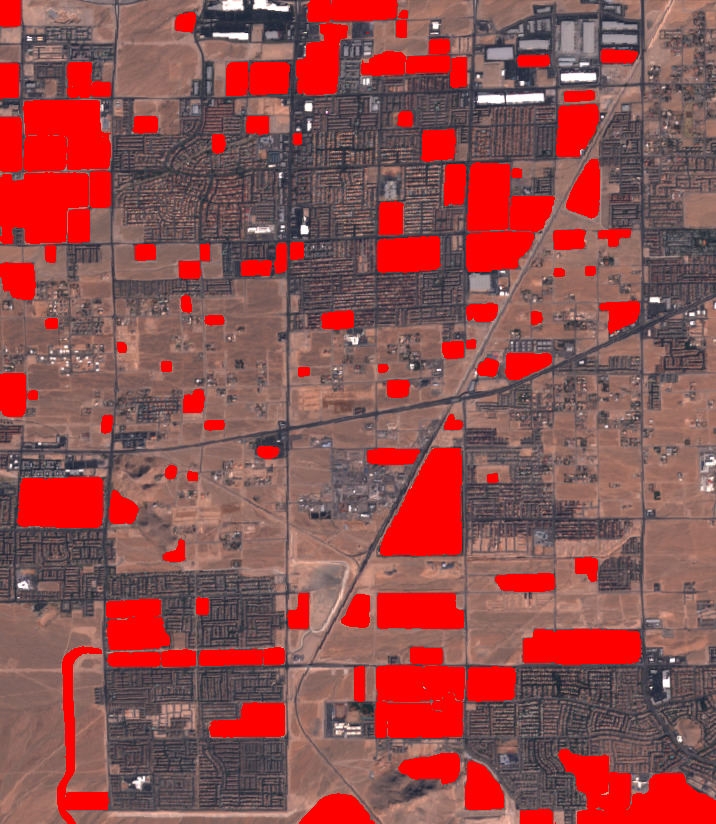
DeltaMind - Visual Change Detection Engine
Hackathon Project | Real-Time Visual Monitoring Pipeline
A general-purpose visual comparison engine that detects, segments, and tracks visual changes across time-series images and video streams. DeltaMind is designed to handle any visual comparison task, from manufacturing inspections to infrastructure monitoring.
Inspiration
Most modern visual inspection systems are brittle and siloed. A model trained to detect scratches on a factory gear cannot detect cracks in a bridge, and a system that can check brand logos cannot monitor infrastructure.
We were inspired by the need for a single, general-purpose engine that could handle any visual comparison task, regardless of the domain. Our goal was to build a universal translator for visual change.
What It Does
DeltaMind is a modular, three-stage pipeline that analyzes video streams or image sequences to find and isolate changes as they evolve over time. Instead of comparing only two static images, it continuously monitors a process, comparing each new frame against a "normal" reference state.
Stage 1: Align (The Foundation)
It first performs digital registration of every new frame in the sequence. Considering real-world monitoring applications, this step is necessary to get rid of camera jitter, slight variations in camera angle or zoom, and even changes in illumination conditions. Geometric registration (using SIFT/ORB) followed by photometric normalization ensures that every frame is compared "apples-to-apples" against the reference, whether it is the previous frame or an initial "golden" state.
Result: Two images that are perfectly lined up, as if taken from the exact same spot at the same time.
Stage 2: Detect (The "Dual-Check Brain")
It performs a "Dual-Check" on each aligned frame for the detection of anomalies with high confidence.
- Fast Check (Temporal-Level): Utilizes
SSIM+ absolute-difference to immediately flag all possible areas of motion or pixel-level change between successive frames. - Deep Check (Feature-Level): Uses a
PatchCoredeep learning model. The magic is that this model is trained only on 'normal' video sequences of the process. It learns the "texture and motion of normal" and flags any new, developing defect (a crack forming, a component wearing down, a misprint) which it may have never seen before, simply as an "abnormal" deviation.
By fusing these two checks, we get high-confidence anomalies, filtering out "noise" such as shadows or benign, expected movements.
Stage 3: Segment (The "Precise Cut")
The bounding box locations for high-confidence anomalies from each frame are fed as prompts into a Segment Anything Model 2 (SAM 2). This model, in turn, generates a very precise, pixel-level mask of the shape of the change at that particular frame.
By stringing these masks together, DeltaMind does not only find a change but rather tracks its evolution, enabling analysis of size, shape, and rate of progression over time.
How We Built It
We designed DeltaMind as a Python-based system and prototyped the core pipeline to handle video streams.
- Alignment: We employed
OpenCVto implementSIFT/ORBfor keypoint matching andcv2.warpPerspective. This aligns each new frame to a reference, thus enabling the compensation of camera vibration or drift. Histogram matching was performed for photometric normalization against changing light. - Detection: We implemented the temporal check (
SSIM+difference) usingOpenCV. As for the deep check, we used theAnomaliblibrary to implement and train aPatchCoremodel. Most importantly, this was trained on video sequences of 'normal' operation, so it learned the "texture and motion of normal." - Segmentation & Tracking: We used the Hugging Face
transformerslibrary to load a pre-trainedSAM 2model. By feeding it prompts from our detection stage, it generates a precise pixel mask for the anomaly in each frame, thus tracking its progress. - Captioning (Optional): Alternatively, the sequence of anomaly masks and frames can be sent to a pre-trained Vision-Language Model (VLM). This model translates the visual input into a text description of the event, such as "A linear crack is appearing on the left strut."
- Demo Interface: We wrapped this entire pipeline in a
Streamlitapplication. Our interactive demo allows a user to upload a video file or connect a live webcam feed for real-time analysis, with a toggle to enable or disable the optional captioning.
Challenges We Ran Into
The real world is messy. Real-time video is even messier. By far the most significant challenge was a flood of False Positives. An approach based on frame-to-frame difference (SSIM) alone was a disaster, flagging everything from shadows to light flicker to camera jitter and even the normal, expected movements of machinery.
We solved this with our "Dual-Check" fusion. Because an anomaly needed to be flagged by both the fast temporal check via SSIM and the deep feature check via PatchCore, the vast majority of environmental and operational noise was filtered out. This fusion forms the crux of the reliability of our system.
Proving the "general-purpose" claim was another challenge for video. The answer was this "normal-only" training paradigm. We don't need to search for rare "defect" videos but only an easy-to-get video of "normal operation" for each new use case. The model learns the "texture and motion of normal," and hence, it is super fast to adapt.
Accomplishments We Are Proud Of
- We are incredibly proud of the modularity within our 3-stage pipeline. The "Detect" stage is plug-and-play. We built it with
PatchCore, but we've designed the architecture so that it could be swapped out for aVideo Autoencoder (VAE)or even a foundation model such asDINOv3, without having to re-architect the whole system. - We also pride ourselves on the real-time robustness of the Align stage. Our demo can handle a live webcam feed successfully, correcting for jitter and movement, showing that this core concept is sound for real-world scenarios when cameras are never still.
- Finally, we are proud that we don't just find change—we track it. By passing prompts to
SAM 2on every frame, we generate a live, evolving mask of the anomaly, showing its precise shape as it grows or moves.
What We Learned
We realized that such a "general-purpose" monitoring system is not a single magic model, but an intelligent pipeline of specialized modules. Our Alignment module handles the physics of the video feed (jitter and light), whereas our Detection module takes over with the perception of normal versus abnormal motion and texture. This division of labor is the key to making it work reliably in real time.
We also learned that SOTA models, such as SAM 2, are game-changers. Getting precise, pixel-level masks "for free" on each frame makes the output 10x more valuable and actionable than a simple bounding box. You're not just getting an alert; you're watching the precise geometry of a fault evolve.
What's Next for DeltaMind
This prototype, built during a hackathon, proved the core of our real-time monitoring engine. The next steps will involve scaling this into a production-grade MLOps platform.
- Microservices API: Rewrite the processing pipeline using
FastAPIandCelery/Redisas the task queue. This is very important because of the need to asynchronously ingest and process hundreds of concurrent video streams from enterprise clients. - Multi-Tenancy: Develop the full multi-tenancy backend in order to manage and serve the "normal-only" models for different clients and assets (e.g., one model for 'Machine A', another one for 'Bridge Section 4') from a single unified platform.
- Predictive Analytics: Currently, we detect change. The next step is feeding the time-series data of the anomaly's growth (say, mask size, shape complexity) into a forecasting model, such as an
LSTM. This will take DeltaMind from detecting failure to predicting it—e.g., "With the current growth rate, this crack will reach a critical threshold in 72 hours."
Applications
- Manufacturing Inspections - Detect defects and deformations in production lines
- Brand Compliance - Verify packaging and product consistency
- Infrastructure Monitoring - Identify structural changes and damages
- Automated Audits - Quality control and compliance verification
🔬 Experimental Journey
Before arriving at our current video-based pipeline, we explored multiple methodologies to find the most robust and practical solution.
Approaches We Tested
We implemented and compared four distinct detection strategies:
1. Hybrid Difference + SAM
- Combined pixel-level difference (SSIM + Absolute Difference) with SAM for segmentation
- Result: Excellent accuracy for static image pairs, simple and fast
2. Multi-Fusion Ensemble + SAM
- Blended difference maps at multiple weights and thresholds for robustness
- Result: Accurate but unnecessarily complex
3. Ensemble with K-Means Clustering + SAM2
- Used multiple fused maps with K-Means clustering to group anomaly candidates
- Result: Accurate but slow and required significant parameter tuning
4. Semantic Feature Difference (DINOv3 + SAM2)
- Attempted to use deep vision transformer embeddings to detect semantic changes
- Result: Failed to detect small-scale, pixel-level anomalies
Key Insights
Why Static Approaches Were Insufficient:
- Lacked temporal context to track anomaly evolution
- Required manual frame selection for comparison
- Struggled to distinguish environmental noise from true defects
- No ability to monitor continuous processes
Why DINOv3 Semantic Approach Failed: While DINOv3 excels at semantic understanding, it proved unsuitable for detecting subtle texture changes and missing parts. Pre-trained encoders alone, without task-specific decoders, cannot effectively identify pixel-level anomalies.
The Ideal (But Impractical) Solution: An encoder-decoder architecture trained end-to-end for anomaly detection would theoretically be superior—using a vision encoder (DINOv3/CLIP) paired with a custom decoder trained on normal examples. However, this requires large-scale domain-specific datasets, significant computational resources, and training time unavailable in a hackathon setting.
Our Evolution to DeltaMind
The current video-based pipeline emerged from these learnings:
- Continuous monitoring instead of static snapshots
- Temporal + feature-level fusion to reduce false positives dramatically
- "Normal-only" training paradigm for rapid domain adaptation
- Real-time tracking of anomaly evolution and progression
This modular, practical approach delivers production-ready performance without requiring extensive training data or compute resources.
Built With
- celery
- dinov3
- docker
- fastapi
- huggingface
- mlflow
- opencv
- patch-core
- postgresql
- pytorch
- redis
- sam-2
- sam2
- scikit-learn
- sift
- ssim
- timm
- transformers



Log in or sign up for Devpost to join the conversation.