-

Main Page
-
Analyze New Passage
-

Passage Definition
-
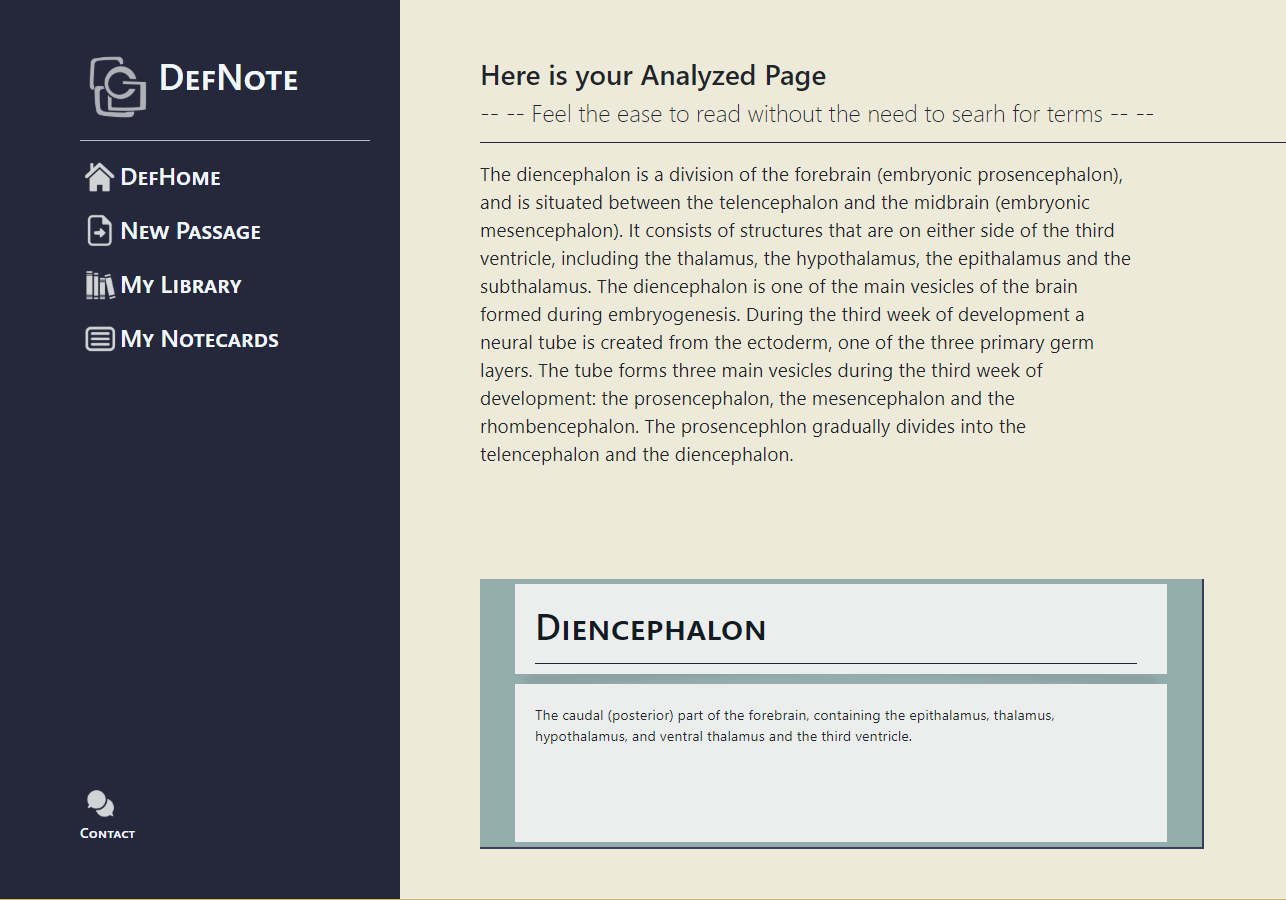
Note cards for review

HACKXX_DefNote
Inspiration
Looking up terms in an academic article can be a tedious and time consuming process. With no on demand explanation of terms students will often have to look up and juggle multiple definitions of certain terms. Students end up spending a large amount of time searching for definitions, whic can be a tedious and tiring process for studying. Our application was designed to create a more streamlined process to help women and men everywhere be able to quickly analyze and read difficult passages.
What it does
We created a web application that allows users to input passages from class, and auto identifies and defines the terms that most needed to be explained using Natural Language Processing API and python wiki package. After processing with our built database, the user could view the text at ease: for terms needed explanation, they would hover their mouse over the word, and the definition would be displayed in the definition box. After reading the text, users could also create a set of notecards by one click.
How we built it
We built the backend through:
1. convert data
In order to train the machine learning the subject-specific vocabulary, we need to distinguish words between academical word and daily used word. Thus, we integrate several Biological textbook into a big txt file. And we also integrate several novels into another big txt file.
2. prepare data
By using nltk(Natural Language Toolkit), we break text into single words. Then by using corpus from nltk, we filtered the word list by kicking out of stopwords and non-English words. Thus, every word in the list is meaning ful.
3. train the data
We loop through different database and generate a word_frequency txt file by counting the number of times a word has appeared in the database. So a biology-terminalogy will only appear in biology database, and a none-biology-terminology will appear in both of the databases. Then, by removing word appeared in both of the database, and the remaining will be biology terminology.
4. output the data
We output the biology terminalogy, and analyze whether there is word in user's input that is part of the biology terminology word list. Then, the word that satisfies the requirment will be the word that needs to be defined.
After completing the algorithm, we created a website to host the application using HTML5, CSS, and JavaScript. The website includes the structure of the application on the left, and perform the text intake, reading with definition, and notecard functions on the right hand side. Through this web app, users learn termiologies from text that are hard to understand with ease.
Challenges we ran into
Making our first webapp was very challenging. Most of us were unfamiliar with the tools needed to create a webpage like Node.js and Natural Language Toolkits used to create our application. We ended up having to split our time between trying to new languages and API's and programming. We also spent a few hours trying to get google cloud API's to work as well, but the output was not useful for the purposes of our application so we discarded it.
Accomplishments that we're proud of
We're proud of the skills that we learned while programming the application. The Hackathon turned out to be an intensive crashcourse in new programming languages and APIs.
What we learned
We learned, machine learning for Natural Language Processing, Node.js, and html.
What's next for DefNote
Our original idea was to have this application be able to convert handwritten notes and text files into flashcards. What we ended up doing an application that could be trained to highlight and define certain words that were deemed important and define them using oxford api. Ideally in the future the input we expanded to accept handwritten notes and powerpoints, that would then be converted into flashcards with online or custom definitions.





Log in or sign up for Devpost to join the conversation.