-

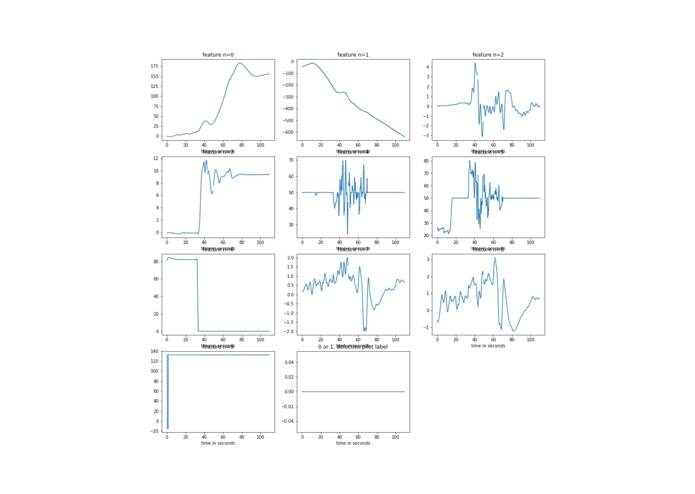
Sample of Original Data (Not Defective -- Labelled as 0)
-
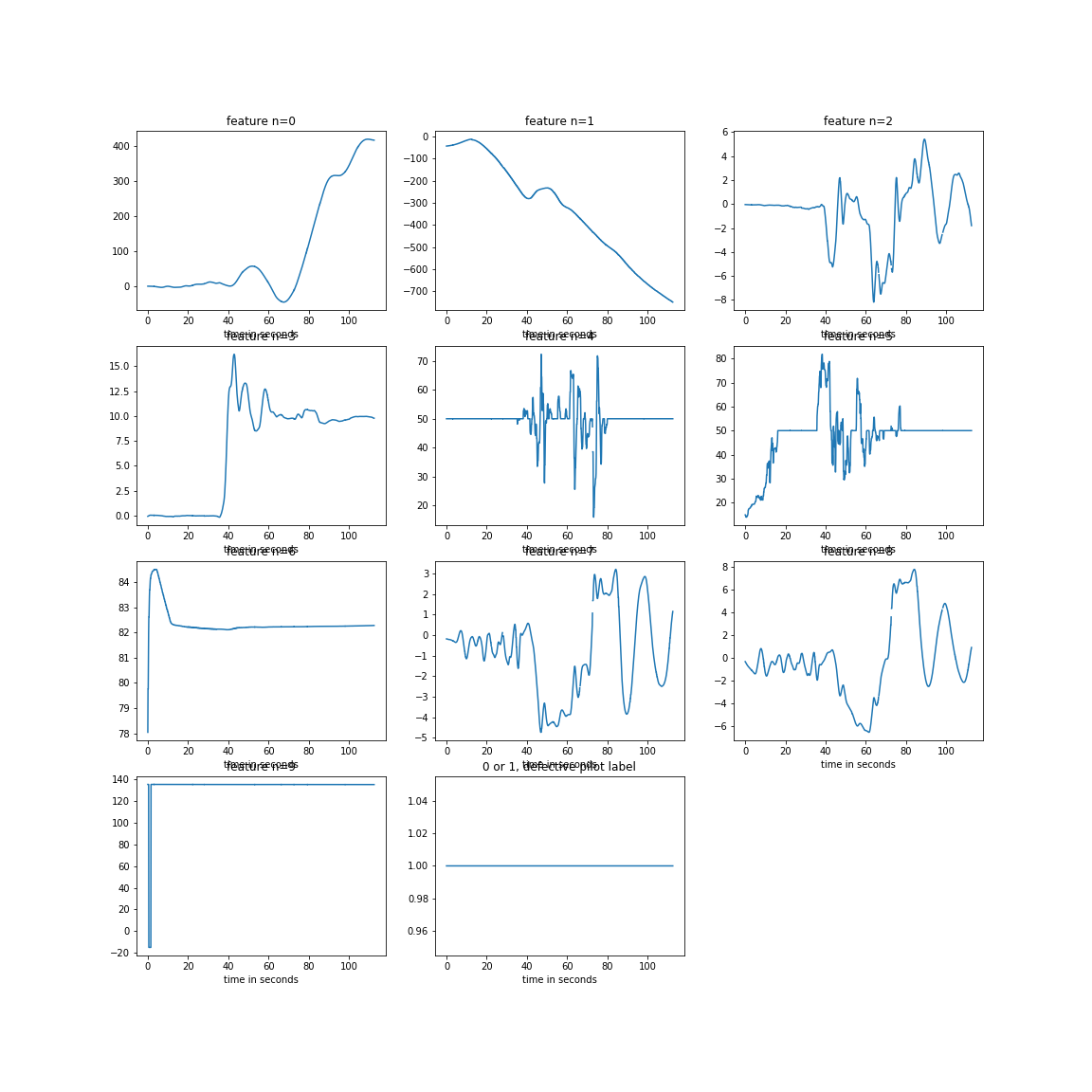
Sample of Original Data (Defective -- Labelled as 1)
-
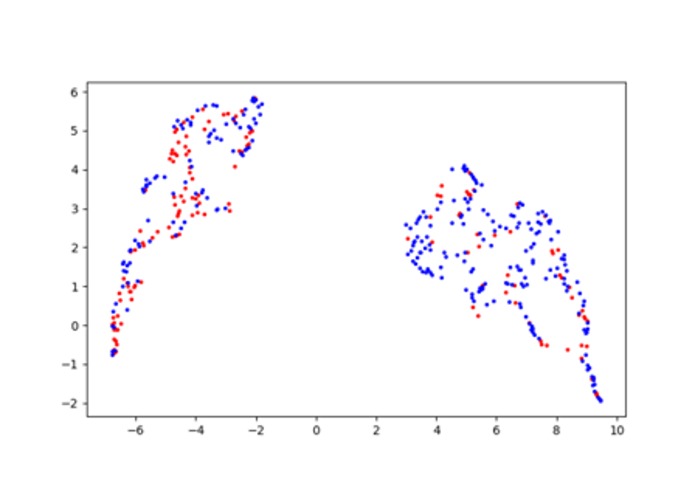
Diagram of Representing U-Map (Uniform Manifold Approximation and Projection) Clustering


defective_pilot
Outline of the problem
After a tragic incident where a pilot commited suicide on the job, we want to detect psychologically unstable / defective pilots. The data-set we are working with is as follows: pilots need training every 6 months. To do this they do a flight simulation and data is gathered on them during the test flight (acceleration, velocity, etc.), we are not told exactly what the data is, only that this data is collected at a rate of 10Hz; a supervisor watches the pilot and writes 0 if the pilot is doing fine, writes 1 if the pilot is stressed or worried or something. We are sure that the 1's are defective. However, we are unsure of the accuracy of the 0's, as the instructor could have forgotten to label it as a 1.
We want to use the data to see if the pilot is defective (aka, label = 1), and identify the ones that are suspicious (labelled as 0's but could be in fact 1's).
Preprocessing
We cleaned up the data so it would easier to process. For instance, some of the test runs in the CSV files were too quite short compared to the others, and so we decided to drop all the runs with under 600 data points, which corresponds to one minute of flight simulation. Moreover, we normalized the data and got rid of outliers. This amounts to roughtly 13% of the data. Note that we decided to chop off the data to 60 seconds length because of the time limit that we had, we tried to keep it as simple as possible to spend more time on the architecture of our model. However, in real life, it would be better to keep as much information as possible to process, so we get higher accuracy.
Our approach
Weeding out the bad data
Extracting some features
The first approach taken was to construct an LSTM looking at rolling non-overlapping sequences of 5 seconds, for the first 60 seconds of every pilot. After cleaning up the data, we had 410 usable pilots' data's, each of 600 datapoints (for 60 seconds). The structure of the LSTM was simple, only one layer, 1 batch corresponding to the entire 60s of each pilot. Since we were aware that the 1's have a higher confidence score, if it was a non-defective pilot, we would have 2 epochs of training, otherwise we would keep it at 1 epoch. The reason for such a choice is that it would give us a baseline with which we could compare the performance of our other models. Furthermore, if using a unsupervised model, we could identify the pilots that are 'suspicious', we could lower the confidence level of their labels in the training of the supervised LSTM, which should be able to give a good accuracy and F1 score. The best results we've got from that LSTM was a F1 score of 0.675 and accuracy of 70.7%. However, this score is not stable and thus is not reliable. We think the reason for this is the small size of the dataset provided as well as the mislabelled data.
Since we know that the data is mislabelled with an unknown probability, we decided to try unsupervised learning to find a pattern in the data, using machine learning, without the use of the wrong labels. This way, we also have the potential to identify the pilots that were wrongly labelled. To do so, we first produced statistical data from the original data so it would give us more insights to work with and map the pilots to higher dimensional spaces. The extra parameters we created were (on every one or some of the 10 parameters given, depending on the specific parameter): mean, standard deviation, maximum, minimum, double derivative absolute value mean, absolute mean gradient, number of non-zero gradients 3D (4,5,6), mean absolute gradient when gradient is non-zero 2D for (4,5), frequency of the change in sign of the gradient, arima best fit coefficients. After that, we combined two different approaches to increase our accuracy and F1 score. To solve the problem of wrongly labelled data points, we used K-Means to form a cluster of non-defective 0's. To identify the pilots that should have been labelled as 1's, we used the Euclidean distance in an 81-dimensional space. Since we heard that around 15% of this data is wrongly labelled, we decided to remove 15% of the furthest points (non-defective pilots) so that we can make sure that most of our data is well labelled. Using that fresh more reliable data, we inputed it in a logistic regression model to output the label, which was empirically tested to demonstrate superior performance over other competitive algorithms for supervised classification such as discriminant analyis, kernel-based support vector machines,
We haven't have time to try the LSTM with that data, but that would be interesting to look at to compare performances.
AI
For the artificial intelligence part, we used LSTM, K-Mean clustering, and logistic regression models.
SOCIAL GOOD
Our model has the potential to replace the instructor, and as we have seen in the dataset, the errors in the identification of lack of soft skills in the pilots. This will contribute to our society's safety, accountability, as well as the population's overall well-being.
OTHER IDEAS
An idea that we haven't had the chance to try is instead of clustering the non-defective ones, we could cluster the ones that are actually defective. This way, we could draw spheres around the centroid to identify the pilots that are identified as zeros but are close to the centroid so they could be considered suspicious.
Also, we would have liked to train the LSTM on a correctly labelled dataset if we had the time to do so.
One more thing we could have tried is the enbox another LSTM or add another layer to see if the performance would have been better.

Log in or sign up for Devpost to join the conversation.