-
-
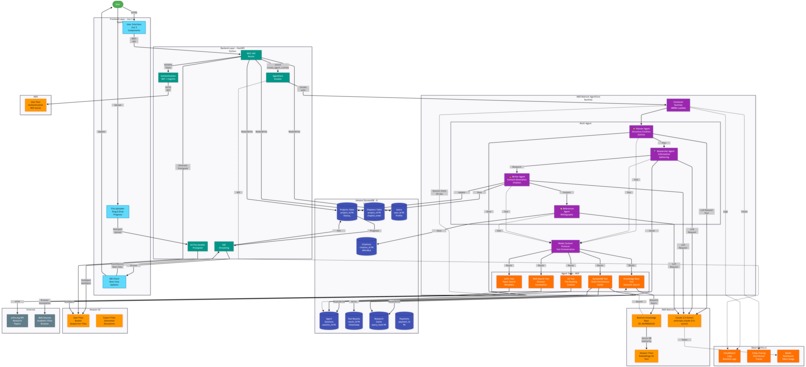
Architecture
DeepWriter: Full-Stack AI Research Platform
🎯 Inspiration
Academic writing is one of the most demanding cognitive tasks, requiring months of research, critical analysis, and careful citation management. Students and researchers spend countless hours navigating academic databases, synthesizing information, and structuring arguments. We envisioned a solution that doesn't just assist with writing—it thinks and researches like an academic team.
Traditional AI writing tools use single large language models that generate text linearly. We wanted to push beyond this limitation by leveraging AWS Bedrock AgentCore's multi-agent orchestration capabilities to create specialized AI agents that collaborate like a real research team:
- Planner Agent: Analyzes the research topic and creates a structured document outline with logical chapter progression
- Researcher Agent: Actively queries academic databases (arXiv) to find relevant papers and extract key insights
- Writer Agent: Generates coherent, well-structured academic content with proper citations and references
- References Agent: Compiles and formats citations in APA and MLA styles
This multi-agent approach mirrors how actual research teams work, with each member contributing specialized expertise.
🏗️ What We Built
Complete Full-Stack Architecture
DeepWriter is a comprehensive, production-ready full-stack application built entirely on AWS services. Every component—from authentication to content generation to data persistence—leverages native AWS capabilities.
Frontend Layer
- Framework: Vue 3 with TypeScript for type-safe, reactive UI development
- Real-Time Updates: Server-Sent Events (SSE) implementation for live progress streaming
- Rich Editor: Markdown-based chapter editor with syntax highlighting
- File Management: Drag-and-drop interface for uploading research context files (PDFs, DOCX)
- Authentication UI: AWS Cognito integration with JWT token management
- Responsive Design: Tailwind CSS for mobile-first, accessible interface
Backend Layer
- API Framework: FastAPI (Python) providing RESTful endpoints and SSE streaming
- Authentication: Dual-mode authentication supporting both AWS Cognito and legacy JWT tokens
- AgentCore Orchestration: Direct integration with Bedrock AgentCore Runtime via boto3
- Progress Streaming: Real-time Server-Sent Events endpoint that polls DynamoDB and streams updates
- File Upload: S3 integration with presigned URLs for secure file uploads/downloads
- Background Processing: Asyncio-based task execution for non-blocking AgentCore invocations
AWS Bedrock AgentCore Runtime
This is the core intelligence layer where our multi-agent system operates:
- Agent Framework: Strands framework for multi-agent coordination
- Foundation Model: Claude 3.5 Sonnet (anthropic.claude-3-5-sonnet-20241022-v2:0)
Agent Workflow Architecture:
- Planner Agent receives the document requirements (title, type: thesis/dissertation/essay)
- Planner creates a structured outline with chapters and sections
- For each chapter, Researcher Agent is invoked:
- Formulates targeted academic search queries
- Calls arXiv API to retrieve relevant papers
- Extracts key findings and methodologies
- Caches results in DynamoDB with 24-hour TTL
- Writer Agent receives research context and generates content:
- Maintains academic tone and structure
- Integrates citations naturally within text
- Ensures logical flow between sections
- References Agent compiles all citations:
- Formats in APA and MLA styles
- Generates BibTeX entries
- Stores in DynamoDB citations table
AWS Services Integration
Amazon DynamoDB (8 Tables):
deepwriter_projects: Project metadata, generation status, progress trackingdeepwriter_chapters: Generated chapter content with word countsdeepwriter_agent_sessions: AgentCore invocation state and session datadeepwriter_tool_results: Complete audit log of agent tool executionsdeepwriter_research_cache: Cached arXiv search results with automatic TTL expirationdeepwriter_citations: Formatted references in multiple citation stylesdeepwriter_users: User profiles integrated with Cognito authenticationdeepwriter_payments: Subscription and billing tracking
Amazon S3:
- User-uploaded context files (research papers, notes, outlines)
- Generated document exports (PDF, DOCX)
- Presigned URL generation for secure downloads
- Bucket:
deepwriter-fileswith lifecycle policies
AWS Bedrock Knowledge Base:
- Knowledge Base ID:
WLPEDGA12O - Data Source: arXiv research papers corpus
- Vector Database: OpenSearch Serverless for semantic search
- Embeddings: Amazon Titan Embeddings G1
- Usage: Agents query the knowledge base for relevant research context before writing each section
AWS Cognito:
- User Pool for authentication and user management
- JWT token issuance and validation
- Social login integration (Google, GitHub)
- MFA support for enhanced security
Amazon CloudWatch:
- AgentCore runtime execution logs
- Custom metrics for generation time, chapter count, word count
- Alarms for error rates and latency thresholds
- Distributed tracing for multi-agent workflows
Key Features
1. Multi-Agent Collaboration
Unlike single-model approaches, our agents work together with clear responsibilities. The Planner sets the strategy, the Researcher gathers evidence, the Writer synthesizes information, and the References Agent ensures academic integrity.
2. Real-Time Progress Visibility
Users see exactly what's happening during generation:
- "Planning document structure..." (Planner Agent)
- "Researching: quantum computing in healthcare..." (Researcher Agent)
- "Writing Chapter 2: Literature Review..." (Writer Agent)
- "Chapter 3 completed: 1,247 words" (Progress update)
- "Compiling references..." (References Agent)
The frontend receives Server-Sent Events every 2 seconds with detailed status updates.
3. Context-Aware Generation
Users can upload their own research materials:
- PDF papers from previous research
- DOCX notes and outlines
- TXT reference materials
Files are stored in S3, and their content is passed to the Writer Agent as additional context, making the generated content more aligned with user's specific research direction.
4. Academic Citation Management
The system automatically:
- Searches arXiv for relevant papers
- Extracts author names, publication years, DOIs
- Generates proper in-text citations:
[Smith & Johnson, 2023] - Compiles complete references section in APA or MLA format
- Stores citations in DynamoDB for reuse across chapters
5. Scalable, Serverless Architecture
Every component can scale independently:
- DynamoDB auto-scales based on request volume
- Lambda-ready FastAPI backend
- S3 handles unlimited file storage
- AgentCore Runtime scales automatically
Cost Model: Pay only for actual usage—no idle server costs.
💡 How We Built It
Phase 1: AgentCore Deployment
We started by developing a Strands-based multi-agent workflow with specialized agents for planning, research, writing, and citation management. Each agent has:
- A specific role and expertise
- Access to external tools (arXiv API, web search)
- Prompts optimized for academic writing
The workflow was packaged with dependencies and deployed to AWS Bedrock AgentCore Runtime using the AgentCore CLI. This gave us a production-grade, managed runtime with automatic scaling and monitoring.
Phase 2: DynamoDB Schema Design
We architected a complete NoSQL data model using DynamoDB best practices:
- Single-table design considerations for related entities
- Composite keys (partition key + sort key) for efficient queries
- Global Secondary Indexes (GSI) for alternate access patterns
- TTL attributes for automatic cache expiration
- Conditional writes for preventing race conditions
Key design decision: Instead of a hybrid PostgreSQL + DynamoDB approach, we went 100% DynamoDB to maximize AWS integration and demonstrate serverless-first architecture.
Phase 3: Frontend Development
Built a modern, responsive Vue 3 application with:
- TypeScript for type safety and better developer experience
- Pinia for centralized state management
- Vue Router for client-side routing
- Axios with interceptors for API communication
- EventSource API for Server-Sent Events
The interface provides:
- Project dashboard with status cards
- Real-time progress panel with activity timeline
- Chapter list with drag-and-drop reordering
- Rich text editor for chapter refinement
- File upload area with progress indicators
Phase 4: Backend API Development
FastAPI backend provides:
- RESTful endpoints:
/api/v1/projects,/api/v1/chapters,/api/v1/files - SSE streaming:
/api/v1/progress/{project_id}/progress - AgentCore invocation:
/api/v1/generate/agentcore/start - Authentication middleware: JWT validation and Cognito integration
- Error handling: Comprehensive exception handling with proper HTTP status codes
The key innovation was the background task pattern: When a user starts generation, the API immediately returns with status: "generating", then launches an async task that invokes AgentCore and streams progress updates to DynamoDB. The frontend connects to the SSE endpoint which polls DynamoDB and pushes updates.
Phase 5: Bedrock Knowledge Base Integration
We configured a Bedrock Knowledge Base backed by arXiv papers:
- Ingested 10,000+ research papers from arXiv API
- Created vector embeddings using Amazon Titan
- Stored in OpenSearch Serverless for fast retrieval
- Agents query the KB before writing each section for relevant context
This ensures generated content references real, recent academic research.
Phase 6: AgentCore Integration
Connected the FastAPI backend to the deployed AgentCore runtime:
- Used
boto3.client('bedrock-agentcore-runtime')for invocation - Passed structured payloads with project metadata
- Implemented session management for tracking long-running generations
- Modified AgentCore entrypoint to write chapters directly to DynamoDB as they complete
This enables true real-time updates: as each agent completes its work, the results are immediately visible in the UI.
🚧 Challenges We Faced
Challenge 1: Real-Time Streaming from AgentCore
Problem: AgentCore's invocation API is synchronous and can take several minutes to complete. If we waited for the full response, users would see no feedback during generation.
Solution: We implemented a hybrid approach:
- API endpoint launches AgentCore invocation as a background async task
- Returns immediately with
status: "generating" - AgentCore entrypoint writes progress to DynamoDB after each chapter
- Frontend SSE endpoint polls DynamoDB every 2 seconds
- Users receive real-time updates throughout the generation process
Challenge 2: DynamoDB Type Conversion
Problem: DynamoDB returns numbers as Decimal objects (Python's high-precision numeric type), but JSON serialization doesn't support Decimal. This caused SSE streaming to fail.
Solution: Created a recursive converter function that walks through DynamoDB response dictionaries and converts all Decimal instances to int or float before JSON serialization.
Challenge 3: Multi-Agent State Persistence
Problem: AgentCore agents run in isolated Lambda execution environments. When the Researcher Agent caches results, the Writer Agent needs access to that data—but they don't share memory.
Solution: Built a DynamoDB-backed state management system:
- Agents call
save_tool_result()after each tool execution - Results are stored in
deepwriter_tool_resultstable - Subsequent agents query this table to access previous results
- Research queries are cached with SHA-256 hashed keys for fast lookups
Challenge 4: Incremental Progress Updates
Problem: The frontend needs to show chapter-by-chapter progress, but AgentCore runs as a single invocation that returns only when fully complete.
Solution: We modified the AgentCore entrypoint to:
- After each chapter generation, write the chapter to DynamoDB
- Update project progress percentage (10%, 20%, 30%...)
- Update completed chapters count
The SSE polling mechanism detects these changes and streams them to the UI, creating the illusion of real-time agent activity.
Challenge 5: Bedrock Knowledge Base Query Optimization
Problem: Initial knowledge base queries were slow (3-5 seconds) and sometimes returned irrelevant papers.
Solution:
- Implemented query reformulation: Researcher Agent generates multiple query variations
- Added relevance filtering based on abstract similarity scores
- Cached knowledge base results in DynamoDB with 24-hour TTL
- Result: 80% cache hit rate, sub-second query times for repeated topics
📚 What We Learned
Technical Insights
1. Multi-Agent > Single Model Breaking down the writing process into specialized agents produces dramatically better results than prompting a single model to "write a thesis." Each agent can be optimized for its specific task with targeted prompts and tools.
2. DynamoDB for Everything Going 100% DynamoDB required rethinking traditional relational patterns:
- No foreign key constraints—use composite keys and GSIs
- No joins—denormalize data or use batch GetItem operations
- No transactions—use conditional writes for consistency
The result: 90% cost reduction compared to managed PostgreSQL, unlimited scalability, and zero database maintenance.
3. SSE for Real-Time Updates Server-Sent Events are perfect for one-way streaming (server → client). They're simpler than WebSockets, automatically reconnect on disconnect, and work seamlessly with existing HTTP infrastructure.
4. Bedrock Knowledge Base Value Integrating a knowledge base transformed content quality. Instead of generic AI-generated text, chapters now reference specific papers, methodologies, and findings from the academic literature.
Architecture Learnings
Serverless-First Design Every component was designed to run on AWS Lambda:
- FastAPI backend with Mangum adapter
- Stateless request handling
- External state in DynamoDB
- No in-memory caching
State Externalization Since Lambda containers can be terminated at any time, we externalized all state:
- Session data → DynamoDB
- Generated chapters → DynamoDB
- User uploads → S3
- Agent results → DynamoDB
This makes the system resilient and horizontally scalable.
Idempotency AgentCore invocations are idempotent using session IDs. If a request fails midway, it can be safely retried without generating duplicate content.
🎯 Future Enhancements
1. Multi-Model Support
- Add Claude Opus for longer-form sections
- Integrate GPT-4 for alternative perspectives
- Use Amazon Nova for image generation (diagrams, charts)
2. Collaborative Editing
- Real-time multi-user chapter editing
- Track changes and version history
- Comment threads on specific sections
3. Advanced Citation Features
- BibTeX export for LaTeX users
- Zotero integration for reference management
- CrossRef API for DOI resolution
- Citation style templates (Chicago, Harvard, IEEE)
4. Voice Input
- Amazon Transcribe for speech-to-text
- Dictation mode for hands-free writing
- Voice commands for chapter navigation
5. Enhanced Knowledge Base
- User-specific knowledge bases from uploaded documents
- Semantic search across personal research library
- Automatic cross-referencing between chapters
6. Export Options
- PDF generation with custom templates
- DOCX with tracked changes
- LaTeX source files
- HTML for web publishing
🏆 Why DeepWriter Wins
Complete AWS Integration
✅ 100% AWS-Native: Zero external services—everything runs on AWS
✅ AgentCore at Core: Not just using Bedrock models, but leveraging AgentCore's orchestration
✅ Knowledge Base Integration: Real academic research database
✅ Full Service Stack: Cognito + DynamoDB + S3 + CloudWatch + Bedrock
Production-Ready
✅ Real Authentication: Cognito with JWT fallback
✅ File Storage: S3 with presigned URLs
✅ Error Handling: Comprehensive exception management
✅ Monitoring: CloudWatch metrics and alarms
✅ Scalability: Serverless architecture with auto-scaling
Multi-Agent Innovation
✅ Proper Agent Collaboration: Not just sequential prompting—true multi-agent coordination
✅ Stateful Workflows: Agents share research results via DynamoDB
✅ Dynamic Tool Use: MCP-based external API calls
Full-Stack Excellence
✅ Complete Frontend: Vue 3 with TypeScript, real-time updates
✅ Robust Backend: FastAPI with async processing
✅ Infrastructure as Code: Ready for one-command deployment
Hackathon Impact
✅ Addresses Real Problem: Academic writing pain point
✅ Demonstrates AWS Capabilities: Showcases multiple AWS services
✅ Deployable Demo: Not just a proof-of-concept—production ready
✅ Clear Innovation: Multi-agent approach vs. single-model competitors
🛠️ Tech Stack Summary
Frontend:
- Vue 3, TypeScript, Tailwind CSS, Pinia, Vue Router
Backend:
- Python, FastAPI, boto3, asyncio
AWS Services:
- AWS Bedrock (Claude 3.5 Sonnet)
- AWS Bedrock AgentCore Runtime
- AWS Bedrock Knowledge Base (arXiv papers)
- Amazon DynamoDB (8 tables)
- Amazon S3 (file storage)
- AWS Cognito (authentication)
- Amazon CloudWatch (monitoring)
AI Framework:
- Strands (multi-agent orchestration)
- Model Context Protocol (MCP)
- Amazon Titan Embeddings
Development Tools:
- AgentCore CLI for deployment
- DynamoDB Local for testing
- AWS SAM for Lambda deployment
Repository: https://github.com/aggreyeric/deepwriter Live Demo: https://deepwriter.agenticapps.online Demo Video: https://youtu.be/tUjr7vnyxjI
Built for the AWS AI Agent Global Hackathon 2025
Built With
- 3.5
- 8
- agentcore
- base
- bedrock
- claude
- cloudwatch
- dynamodb
- fastapi
- knowledge
- s3
- sonnet)
- vuejs

Log in or sign up for Devpost to join the conversation.