

Inspiration
Sea turtles and dolphins are really cute. Thousands of them are also needlessly killed every day.
Commercial fishermen often end up catching marine animals they didn't intend to catch, such as sea turtles, dolphins, seals, sharks, and juvenile fish, discarding them after catching them. This is bycatch. A prominent issue, bycatch, threatens endangered species and destroys marine ecosystems. Currently, there are organizations that are helping fisheries manage unwanted catch, but our machine learning approach assesses risk levels of bycatch for anyone with just a click of a button.
What it does
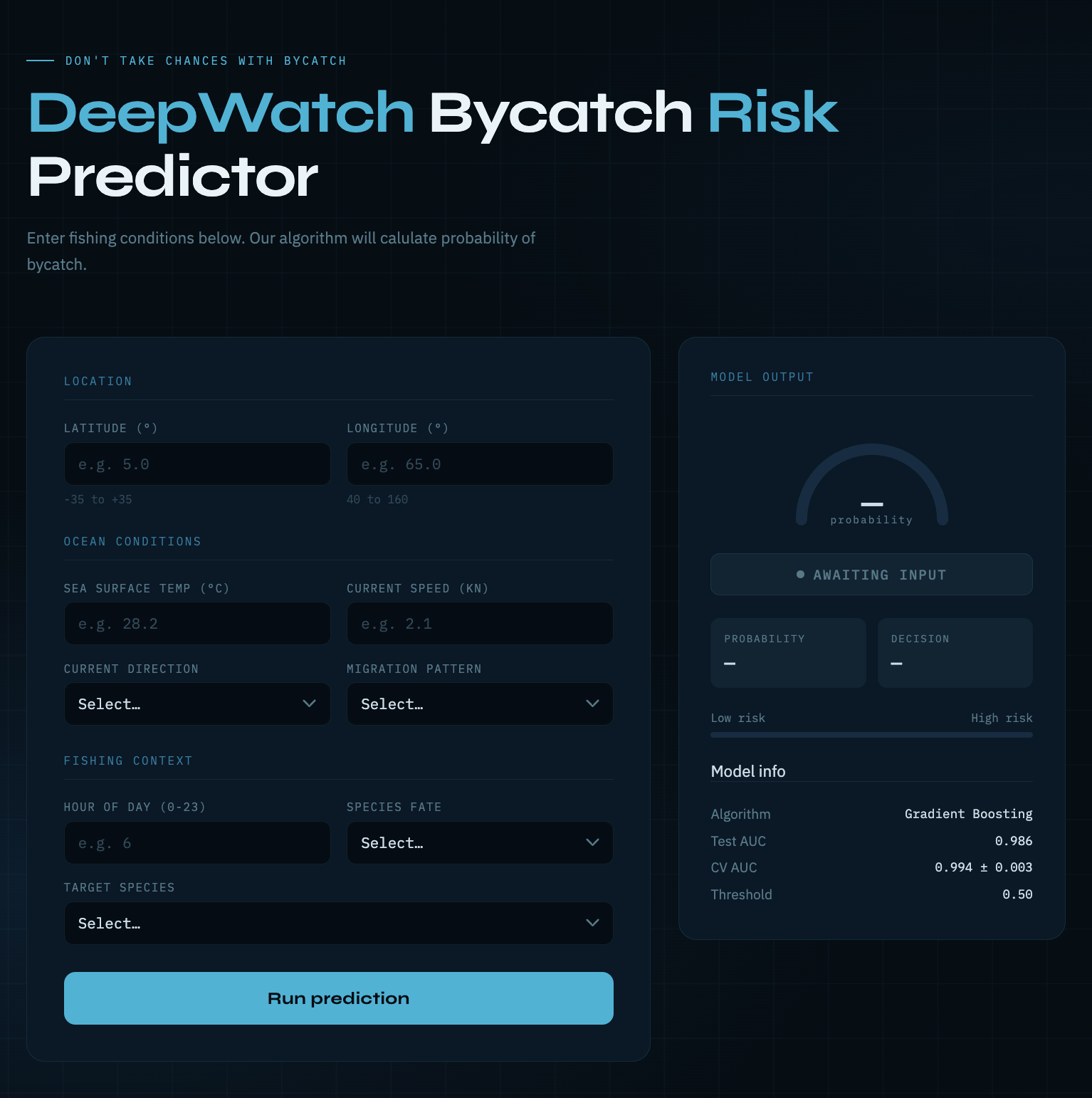
We created an XGBoost model to predict the likelihood of bycatch being present at a given location, such as sea turtles, dolphins, seals, sharks, and juvenile fish. Based on the latitude, longitude, sea surface temperature, current speed, current direction, hour of day, migration pattern, target species, and the species' fate (whether it was kept on the ship or discarded back into the ocean), the model decides whether bycatch is a risk to fishermen or not.
How we built it
Machine Learning Model
Data
Simulated Data - Due to limitations of features within open-source datasets, a dataset was simulated with slight noise to train a model for future use in actual datasets.
Features Used (9 total)
- Latitude
- Longitude
- Sea Surface Temperature
- Current Speed
- Current Direction (encoded)
- Hour of Day
- Migration Pattern (encoded)
- Target Species (encoded)
- Species Fate (encoded)
Algorithm
Gradient Boosting Classifier - An ensemble method that builds multiple decision trees sequentially, with each tree correcting errors from previous ones. An efficient and fast algorithm that provides high accuracy, as opposed to some more complex algorithms that have a boot time greater than what is allowed for the Render free plan.
Model Configuration
n_estimators=200 # 200 decision trees
learning_rate=0.1 # Step size for corrections
max_depth=4 # Maximum tree depth
min_samples_split=10 # Minimum samples to split a node
subsample=0.8 # 80% data sampling per tree
random_state=42 # Reproducible results
Training Process
- Data Loading: Reads Excel file
- Label Creation: Converts "Present"/"Absent" to 1/0
- Encoding: Transforms categorical variables (direction, species, etc.) to numeric
- Train/Test Split: 80% training, 20% testing (stratified)
- Model Training: Fits Gradient Boosting model
- Persistence: Stores model and encoders in memory
Risk Classification
- High Risk: Probability ≥ 65%
- Low Risk: Probability < 65%
Tech Stack
All hosted on Render (free version leads to slight loading issue with long periods of inactivity)
Backend
FastAPI Backend
- Getting values from input fields in the frontend
- Applying the machine learning algorithm to get the probability
- Providing this output to the frontend
Frontend
Simple HTML/CSS/JS frontend
- Landing page with information about the DepepWatch initiative
- Risk Predictor page with all input fields and submission field that outputs percentage on bars and metrics from the model
Challenges we ran into
Finding a real-world dataset with the combination of features we needed was genuinely difficult. Most publicly available bycatch datasets are either poorly formatted, heavily aggregated, or restricted to categorical variables that cannot support numerical model training. We simulated our training data from known IOTC catch patterns, which gave us clean numerical inputs but introduced overfitting risk, since validation was performed on data drawn from the same distribution. We were deliberate about acknowledging this limitation and structured the model to be straightforwardly retrained once real observational data becomes available. Also, as we used the free version of Render to host our webpage, after a period of inactivity, it restarts the building process, which makes the webpage take some time to load before redirecting the user to it.
Accomplishments we are proud of
Within a single day, we built a functioning end-to-end system: a trained machine learning model, a REST API backend, and an interactive frontend, all connected and deployed to the web. The fact that a fisherman can open a browser, enter their fishing conditions, and receive a data-driven risk assessment in under a second felt like a genuine proof of concept for what accessible, practical environmental intelligence could look like in the real world.
What we learned
We learned how to architect a full-stack machine learning application from scratch, covering data simulation, model training, API design with FastAPI, frontend integration, and cloud deployment on Render. We also developed a clearer understanding of the real-world constraints around environmental datasets and why domain-specific data collection is often the hardest part of any conservation-focused machine learning project. Working under time pressure using GitHub reinforced the value of clean separation between system components so teammates could build in parallel without blocking each other.
What's next for DeepWatch
We plan to grow DeepWatch in three directions. First, we will expand species coverage beyond the current five to include the full range of commercially targeted species in North Carolina and broader Atlantic waters. Second, we will integrate real-time ocean data feeds for sea surface temperature, current conditions, and migration tracking so that fishermen no longer need to manually input environmental parameters. Third, we will build spatial visualizations showing where at-risk marine animal populations are currently located relative to a vessel's planned fishing route, transforming DeepWatch from a risk calculator into a genuine navigation tool for sustainable fishing.
Built With
- css
- fastapi
- html
- javascript
- pydantic
- python
- render
- scikit-learn
- uvicorn





Log in or sign up for Devpost to join the conversation.