-
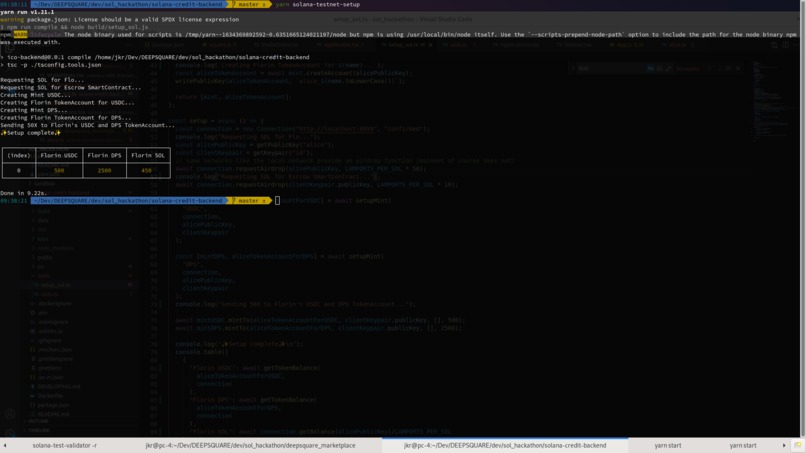
Local solana test network setup. Creating a USDC token, Airdrop some sol
-
Login to the deepsquare market place POC
-
Login to the deepsquare market place POC
-
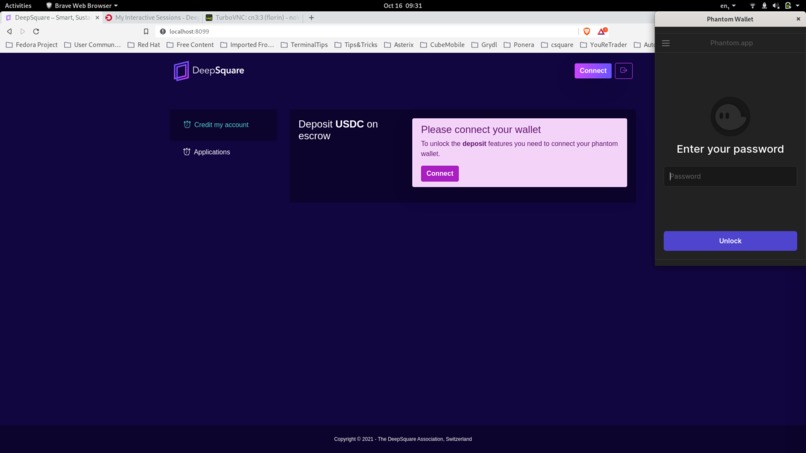
Link phantom wallet to the marketplace
-
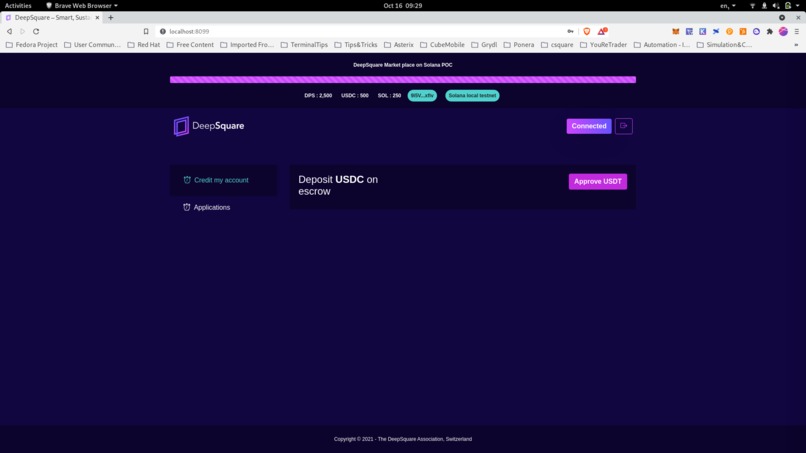
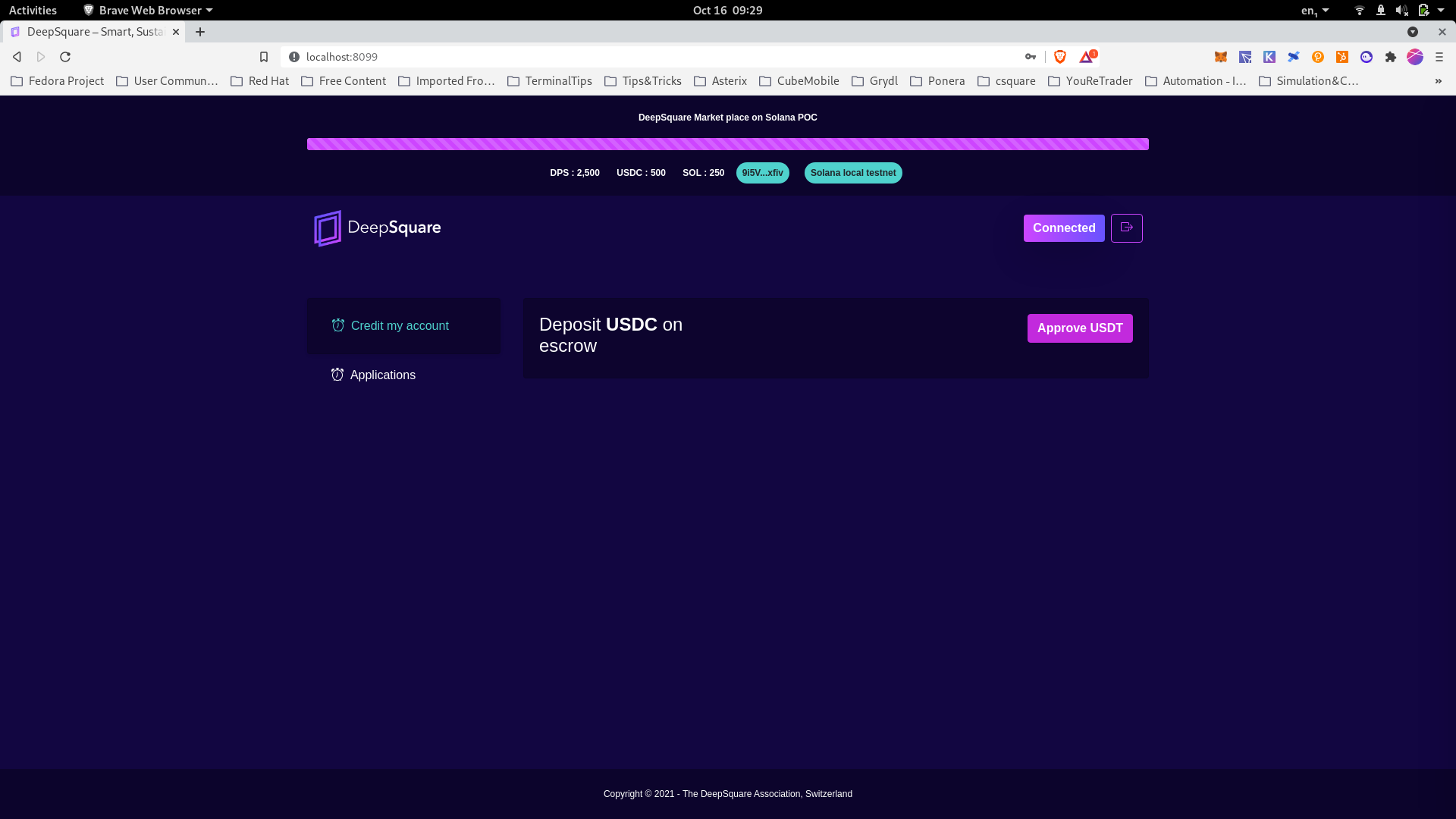
Available USDC / SOL visible. User can credit an application by depositing USDT
-
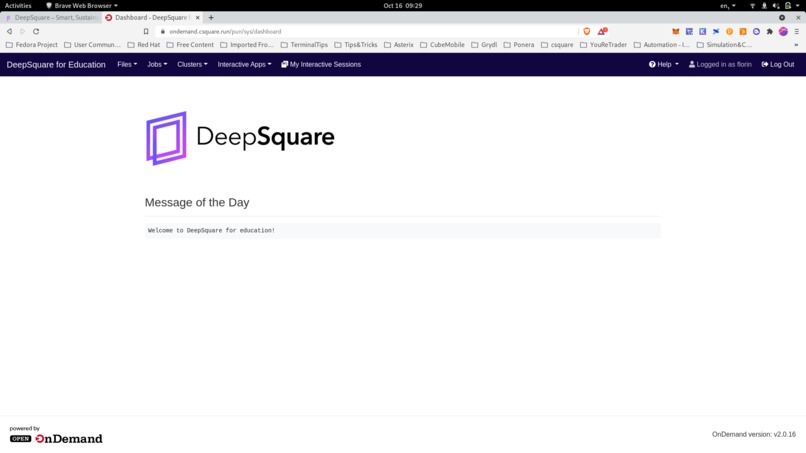
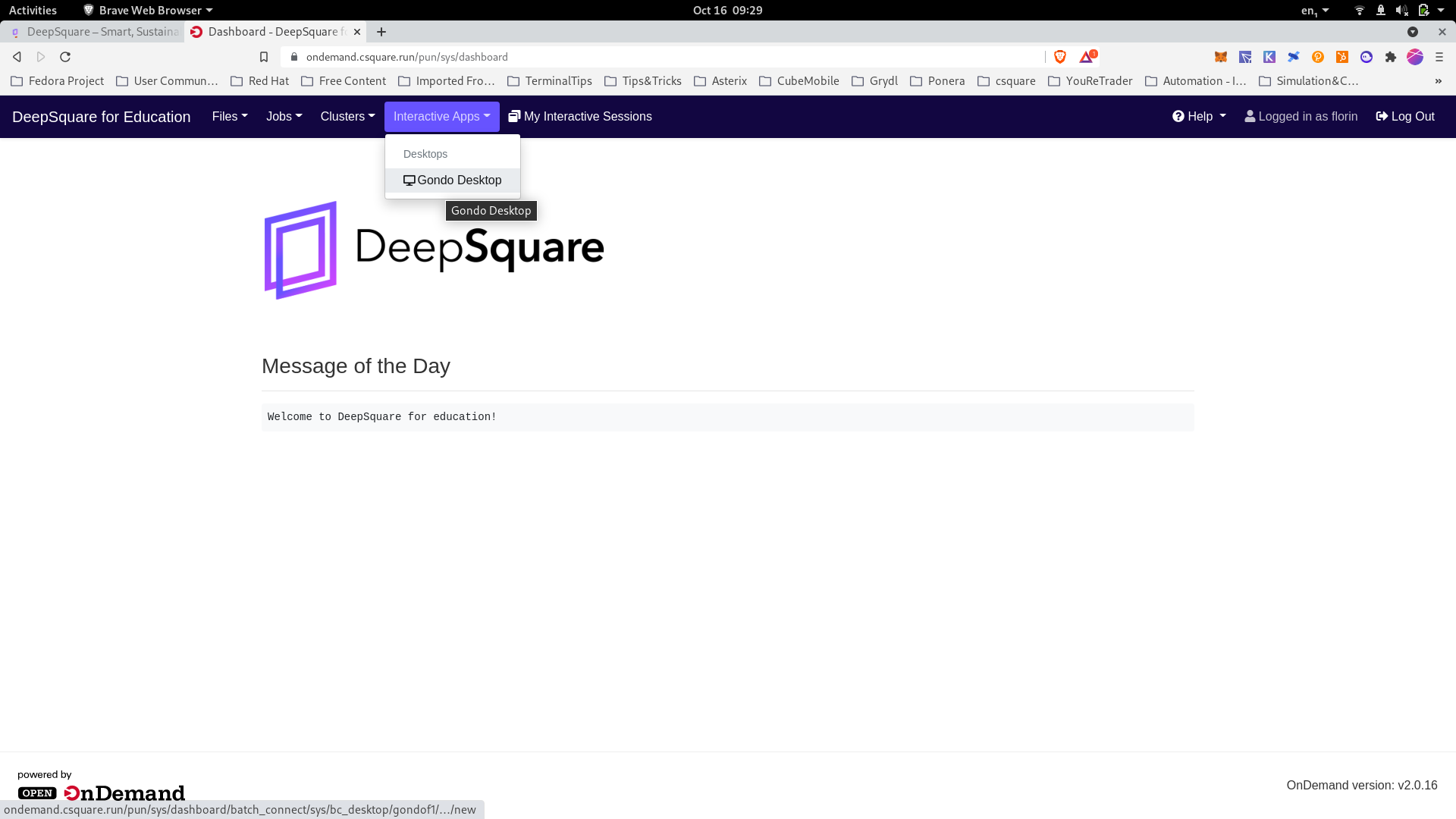
After clicking on the applications the user is moved to the first application made available on the marketplace : openondemand
-
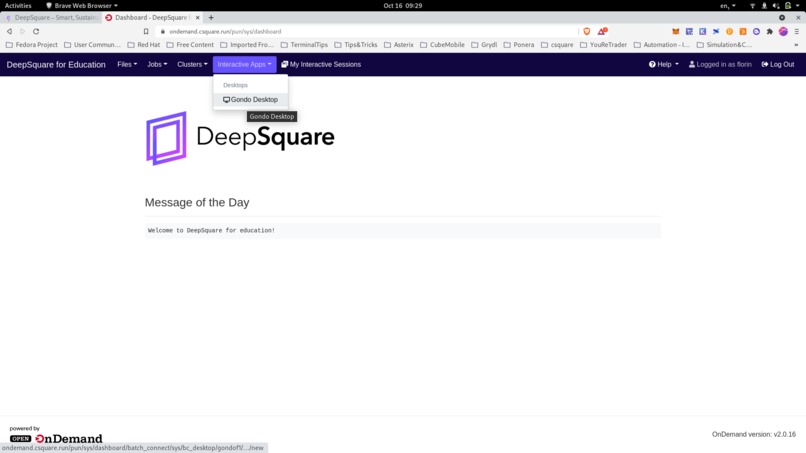
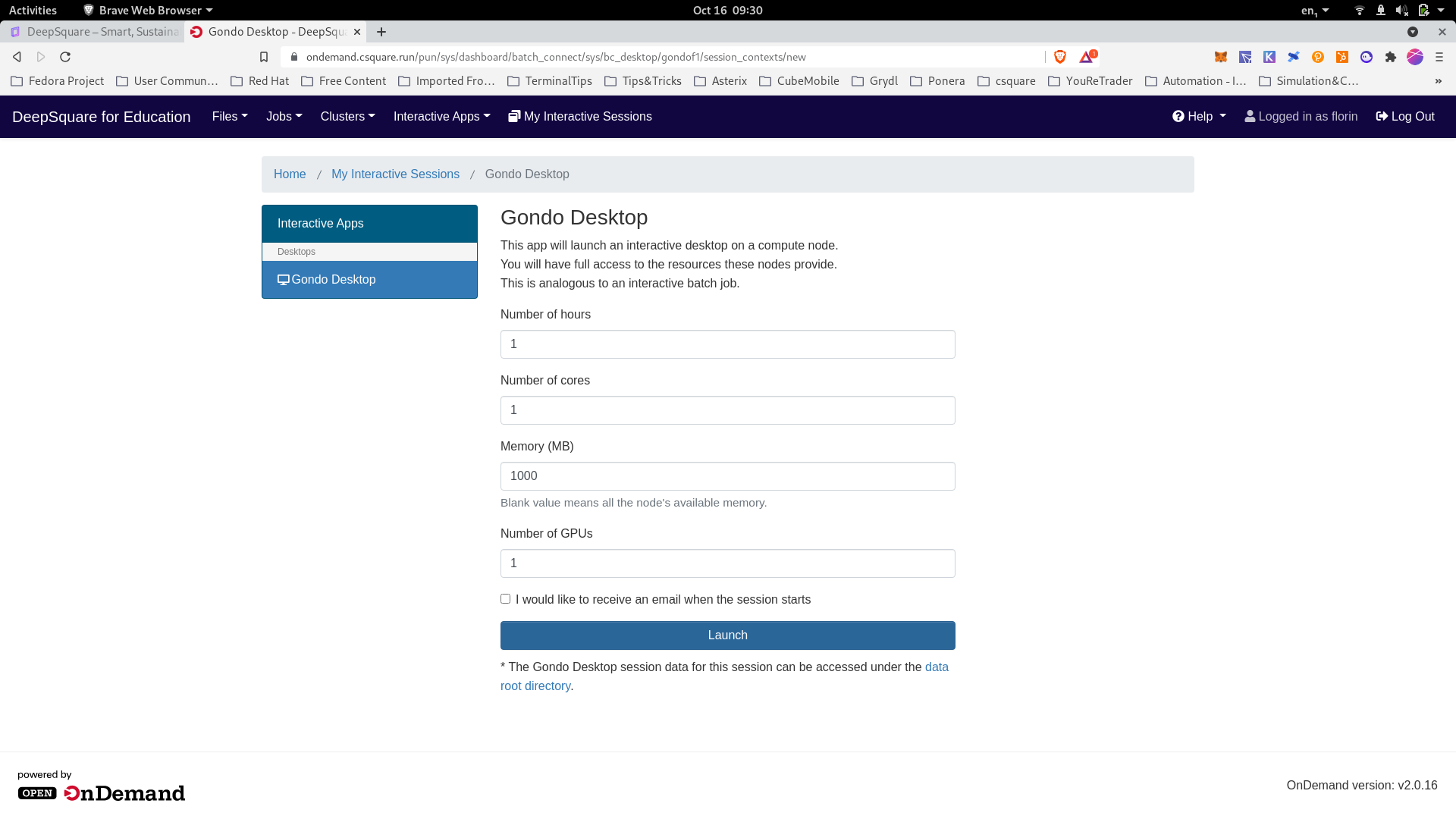
Setting up a distant graphical interface
-
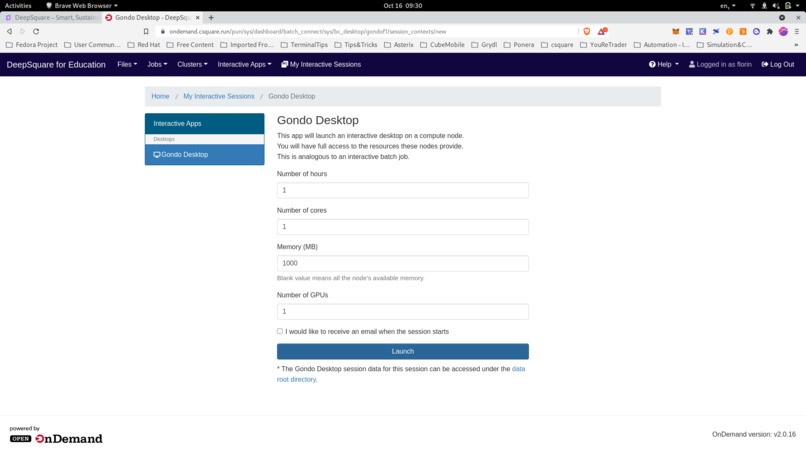
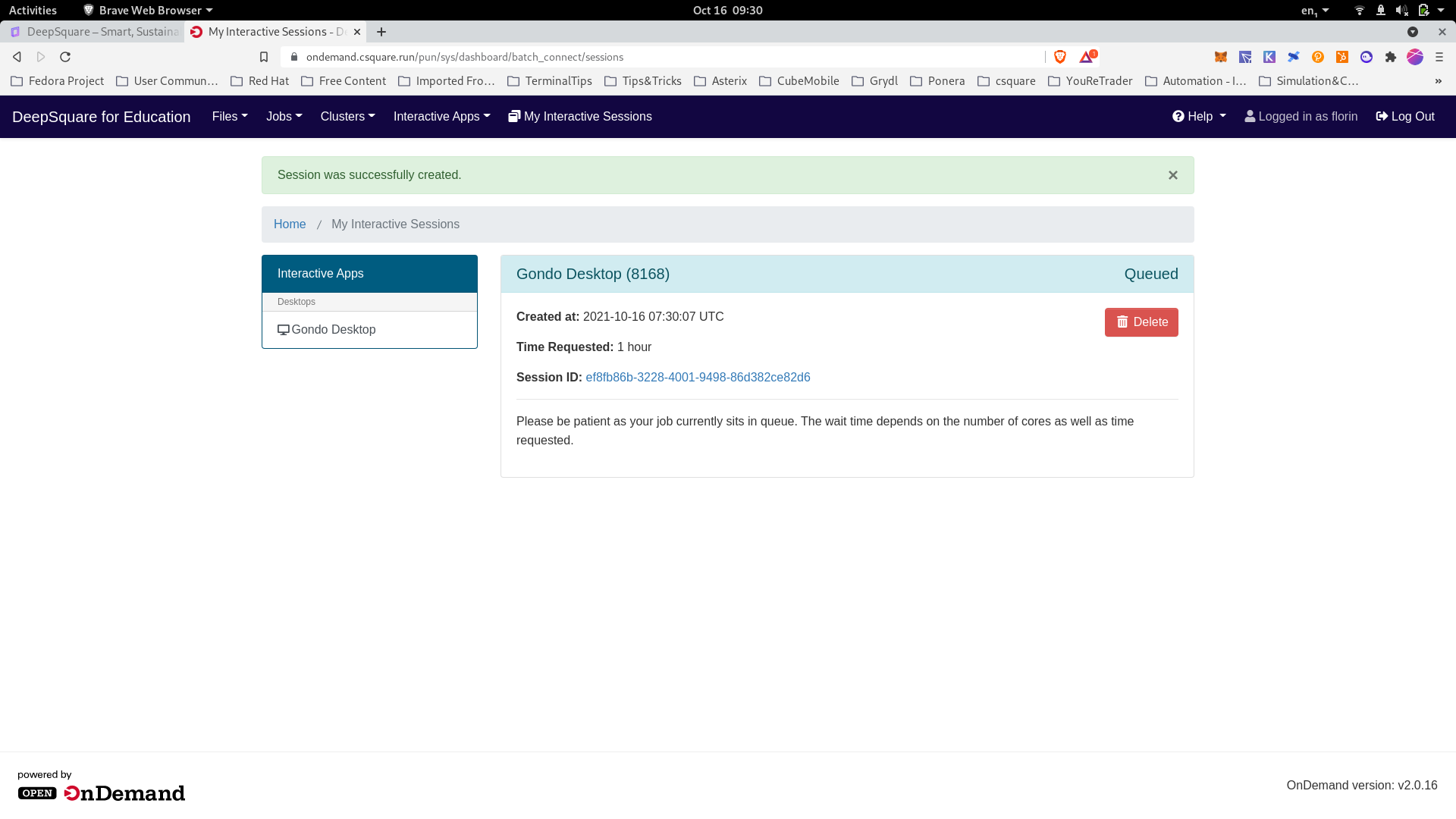
Launching a distant graphical interface
-
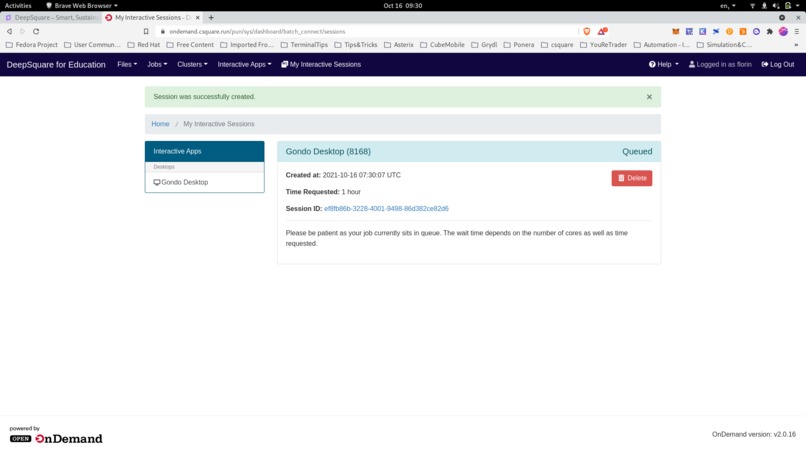
Connecting to the distant graphical interface
-
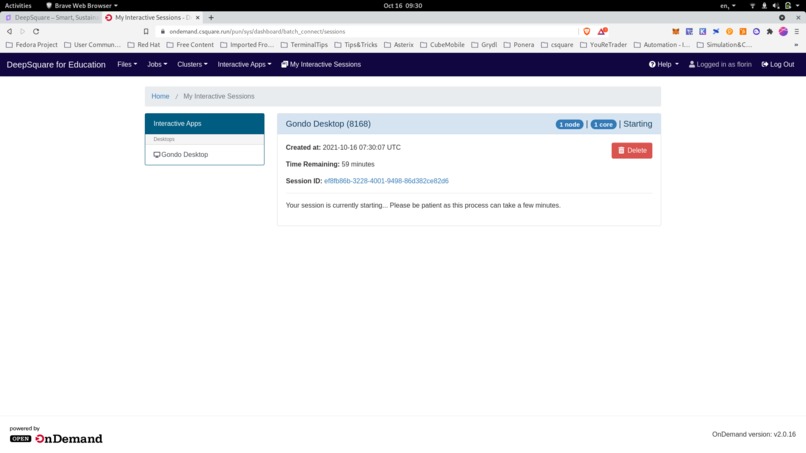
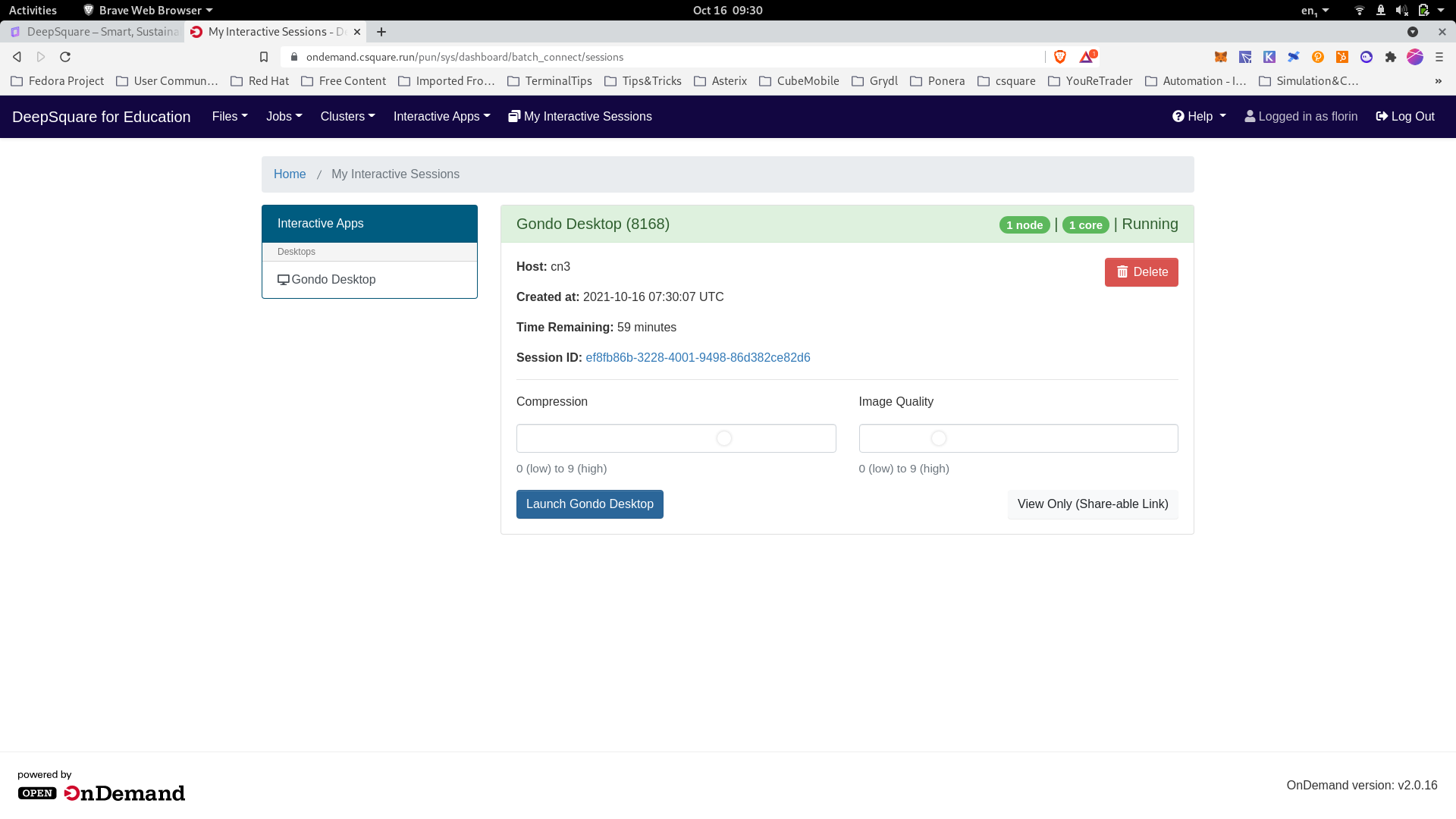
Connecting to the distant graphical interface
-
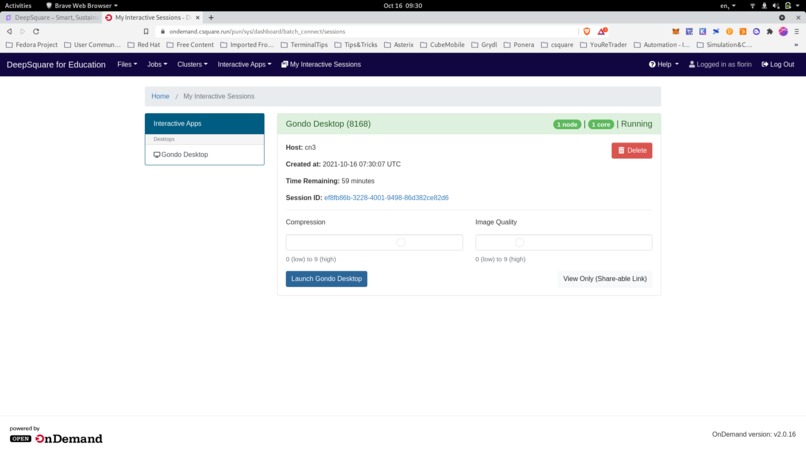
Connecting to the distant graphical interface
-
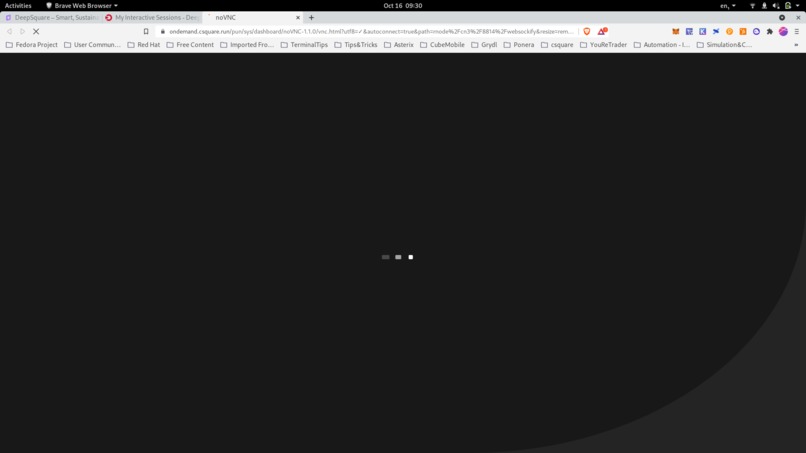
Connecting to the distant graphical interface
-
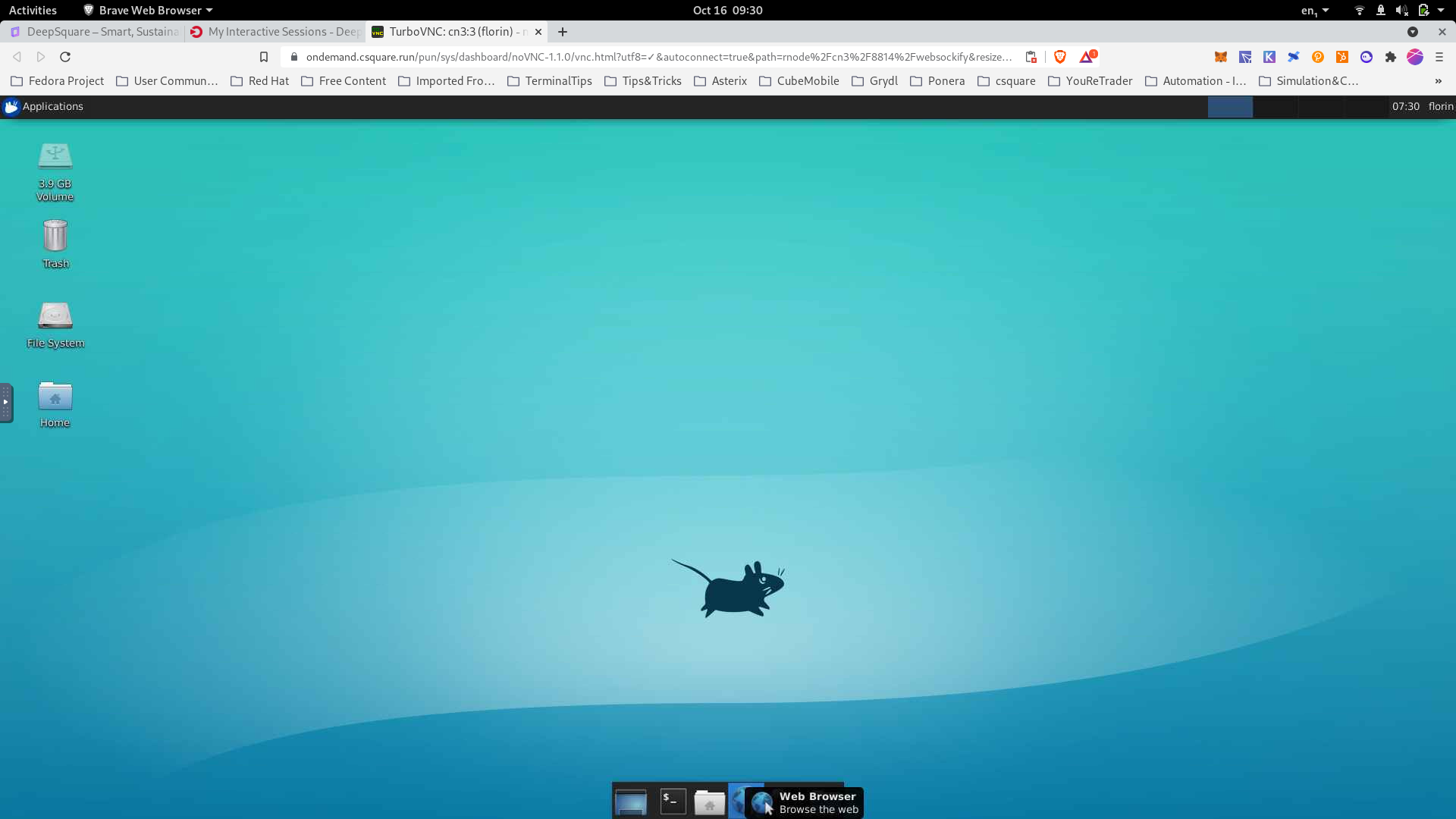
Connected to the distant graphical interface
Inspiration
The internet has undergone a profound consolidation. Through mergers, acquisitions, and market dominance, the hyperscalers continue to take a bigger and bigger share of the datacenter cloud services market. Even natural competitors such as Telcos and Tier 2 Cloud Service Providers have been enticed to reduce their independence and locate their data and compute loads in Azure, Google Cloud, AWS, and IBM. We have not seen this level of industrial-scale market dominance since the Robber-baron era at the turn of the last century. In addition to small and medium-sized enterprises being unable to play in this market, the oligopoly’s control of at scale computing resources has allowed the hyperscalers to enjoy enormous margins with low market pressure to bring pricing to fair value to the users. The benefits of Artificial Intelligence and Machine Learning are too important and the energy consumed is too critical a resource to relinquish to a handful of trillion-dollar enterprises.
What it does
The DeepSquare Project — a community owned next generation platform for democratizing high performance computing in an environmentally friendly and hyper-efficient manner. It is based on an ecosystem of High Performance Computing (HPC) clusters, a Marketplace and a smart contract Protocol that efficiently match high-density workloads between customers and service providers, and 2 blockchain based tokens, the DeepSquare token (an asset/investment token) and the SQUARE token (a payment/utility token). The DeepSquare Project addresses several of the challenges faced by the cloud industry overall, and by intensive computing loads in particular:
- Energy Consumption & Environmental Impact
- Idle Resource Management
- Monopoly, Oligopoly, and Governance How we built it Given the high level of performance needed by AI workloads and the need for parallelization to scale experiments beyond the resources of one single server, we take the supercomputing approach. A supercomputer is able to abstract or circumvent the boundaries between physical servers, creating a single pool of resources which sums the computing power of all the servers (compute nodes) forming it. Supercomputers use a scheduler to orchestrate workload resource allocations, which are consolidated into jobs, and makes it possible to run parallel/distributed jobs across multiple nodes. This means it allows training a model on an unlimited number of GPUs, across an unlimited number of nodes. But this is not only a matter of choosing and installing the right software stack. To achieve this, the nodes need to be able to communicate between each other at the fastest possible speed — in other words, they need to be equipped by the fastest interconnects. Purpose-built High Performance network fabrics like Infiniband not only give the largest bandwidth and lowest latency, but also allow the nodes to communicate directly by completely bypassing their respective CPUs, thanks to RDMA, keeping them totally available for valuable workloads. This also lays the foundation to create a blazing fast and scalable shared storage which is a crucial point when it comes to AI jobs performances: GPUs are capable of crunching data at multiple hundreds of GB per second — being able to use them fully and efficiently has a lot to do with the infrastructure. With this in mind we built a new breed of supercomputer dedicated to GPU workloads, and especially AI. With the help of our partners, we developed immersion cooling ready custom servers, featuring the fastest Infiniband interconnects and latest generation GPUs and NVMe disks, all this with uncompromised PCIe 4.0 bandwidth (later NVLink or similar). Applications are distributed to nodes in the form of secured and unprivileged High Performance computing containers which makes it virtually compatible with any type of workload. Adding new applications is simple and convenient, as our container runtime is compatible with docker and singularity. Finally, because our scheduler is topology and NUMA aware, it always knows where to run a specific workload most efficiently while keeping track of every job’s resource usage.
Challenges we ran into
Operating a sustainable distributed HPC cluster is not an easy task. Capturing waste heat from an air cooling system is very inefficient and air cooling also consumes ~37% of energy (air conditioner, fans, ...) in addition to the compute. The footprint in m2 for an air cooling solution is at least 5x that of a compact immersion cooling solution. Air cooling also limits the locations we can deploy to either traditional data centers or specially prepared data rooms. High-end HPC hardware is very expensive, a cluster (40 compute nodes and 2 master nodes) costs between $1M and $3.5M.
Accomplishments that we’re proud of
We set up and operated an 8MW 40'000 GPU farm in the north of Sweden which allowed us to gain strong knowledge on what it means to run infrastructure at scale. The DeepSquare project has already raised over $500k in the first private sale phase of our ICO (in 6 weeks, mostly from traditional investors), with substantial additional amounts committed. We are managing to successfully straddle and even bring together the traditional and blockchain worlds. We have designed, ordered and deployed our POC HPC cluster at ÉPFL university in Switzerland with the complete configuration we need to prove our concept (green energy, immersion cooling, heat-reuse) and will complete our testing by the end of October 2021. We have spent over 216 person months in the DeepSquare Cluster Manager, the supercomputing layer (ready for production mid November 2021) and an additional 20 person months on the DeepSquare portal and Marketplace (ready for first applications in mid-October 2021 with first workloads coming from HES, the associated engineering school, ÉPFL, TU-München, University of Montreal, University of Washington) We have developed csquare, a deep learning training platform that runs on DeepSquare with first customers: University of Lausanne - Dead Sea Scrolls project, Alan Analytics - Cave paintings project (in cooperation with resident artist from MIT) We have developed isquare, an inference marketplace that runs on DeepSquare also with first customers What we learned The power of community in this industry and the passion for our project amongst blockchain enthusiasts and traditional business alike We had originally decided to develop our own blockchain, but now would rather like to build on an existing efficient blockchain such as Solana
What’s next for DeepSquare
- Develop the Blockchain applications that will record transactions, manage workloads and handle the relationship between our asset token and the utility token
- Explore options with NFTs to offer Computing Bundles or vouchers
- Attract other HPC applications to the DeepSquare marketplace
- Continue to raise funds via ICO and other means to acquire/fund full production clusters
- Expand the team
- Continue to execute on our roadmap
- Offer compute cycles to non-profit organizations and individual university students
- Fund startups focusing on compatible applications in term of HPC, sustainability and social responsibilities

Log in or sign up for Devpost to join the conversation.