-
-
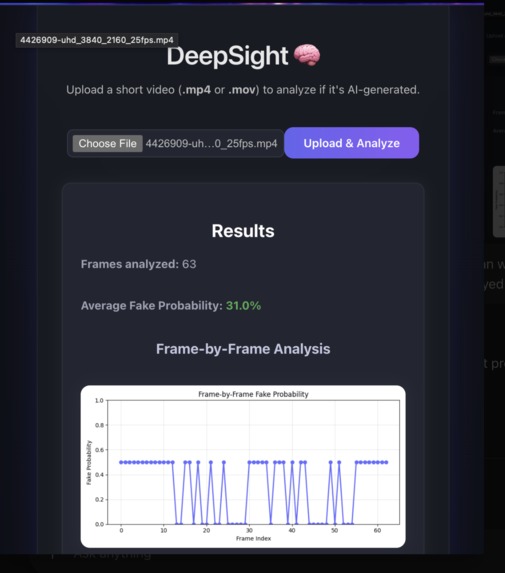
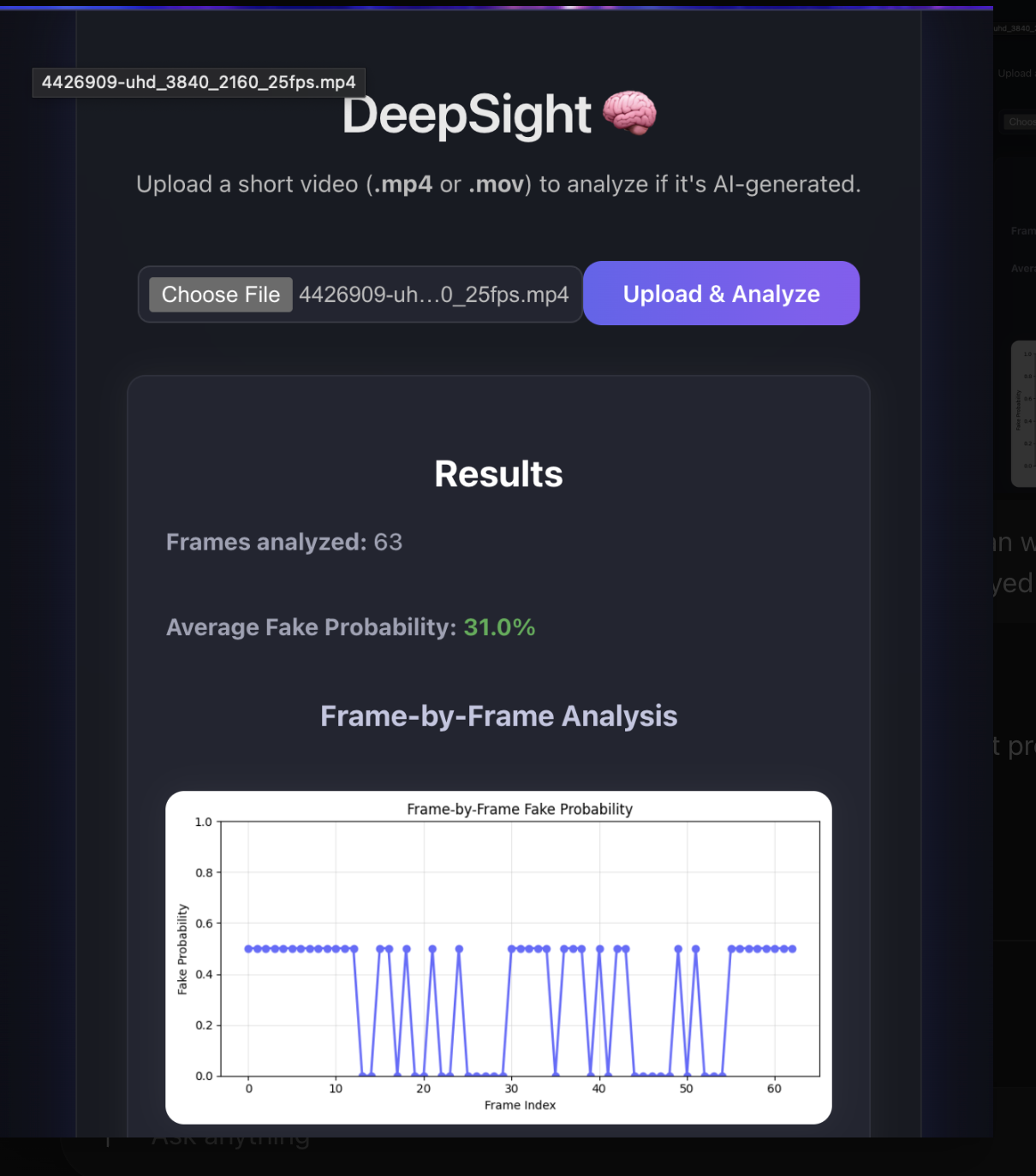
Preview of what the site should look like when you upload a video
Inspiration
Pre-trained Model from the FaceForensics++ 2021 research study utilizing thousands of pictures and videos Model is based on Xception, a deep convolutional neural network, benchmark for deepfake learning and detection Local Application - Deployed using Docker locally
What it does
As deep fake and AI models develop, deep fakes are becoming harder to recognize and easier to generate Our Goal was to develop a lightweight and accessible tool that can analyze short video clips and detect manipulated content
How we built it
PyTorch - Model Implementation Dynamic computation graphs → perfect for experimentation Excellent compatibility with pretrained models Timm (PyTorch Image Models) Gives access to state-of-the-art architectures like Xception, EfficientNet, etc. Integrates seamlessly with PyTorch NumPy and Pandas For post-processing model outputs To calculate frame-wise averages and standard deviations To efficiently handle pixel data coming from OpenCV OpenCV Read frames from uploaded videos Convert color spaces (BGR ↔ RGB ↔ Gray) Detect faces using Haar cascades Crop and align facial regions before sending them to the model React - UI Sleek, Modern UI that could be built and integrated with FastAPI Virtual DOM ensures high performance even with continuous UI updates during video analysis. Strong community support and integration with modern libraries like Chart.js (frame by frame analysis) Vite - Build and Development Engine Launches the dev server in under a second Hot Module Reloading (HMR): Instantly updates UI changes without refreshing the page. Seamless integration: Works out-of-the-box with React, TypeScript, and JSX. FastAPI - API Used for both the frontend and the API, returns .json data from our model to the frontend
Challenges we ran into
At first, coming up with a unique and interesting idea was a challenge Figuring out what our tech stack should look like Difficulty finding and integrating a reliable deepfake detection model that worked with our dataset. Managing compatibility between PyTorch, FastAPI, and OpenCV dependencies. Connecting the FastAPI backend with the React frontend required debugging CORS and fetch errors. Worries about our app being “too simple” Managing environment issues like missing dependencies (transform, preprocessing, np.complex_ errors).
What's next for DeepSight
Expand DeepSight to support longer videos Verified live streaming sources Leverage cloud GPUs for faster inference Also exploring multimodal detection Leverage a combination of audio, visual, and metadata clues to catch synthetic content with even higher accuracy Develop an open-source API for deepfake analysis Potential Follow-Up Train our own model using an expanded dataset Expansive use of GPUs


Log in or sign up for Devpost to join the conversation.