-
-
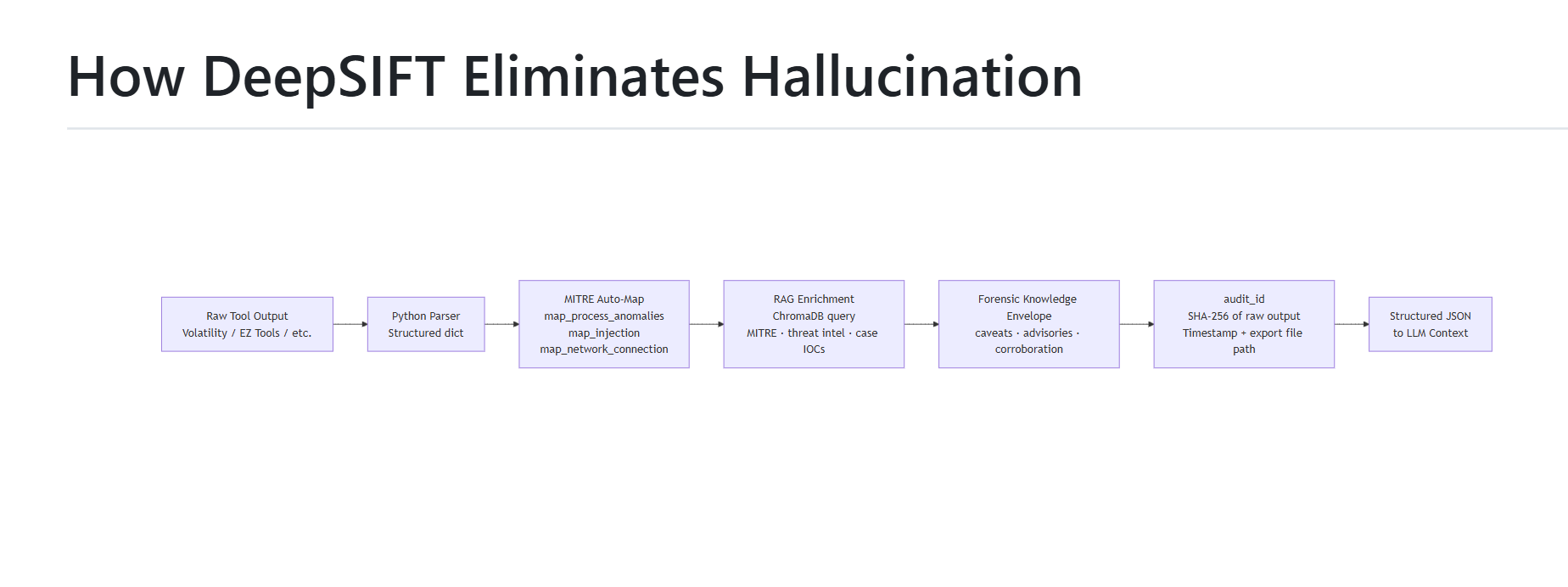
how deepsift eliminates hallucination
-
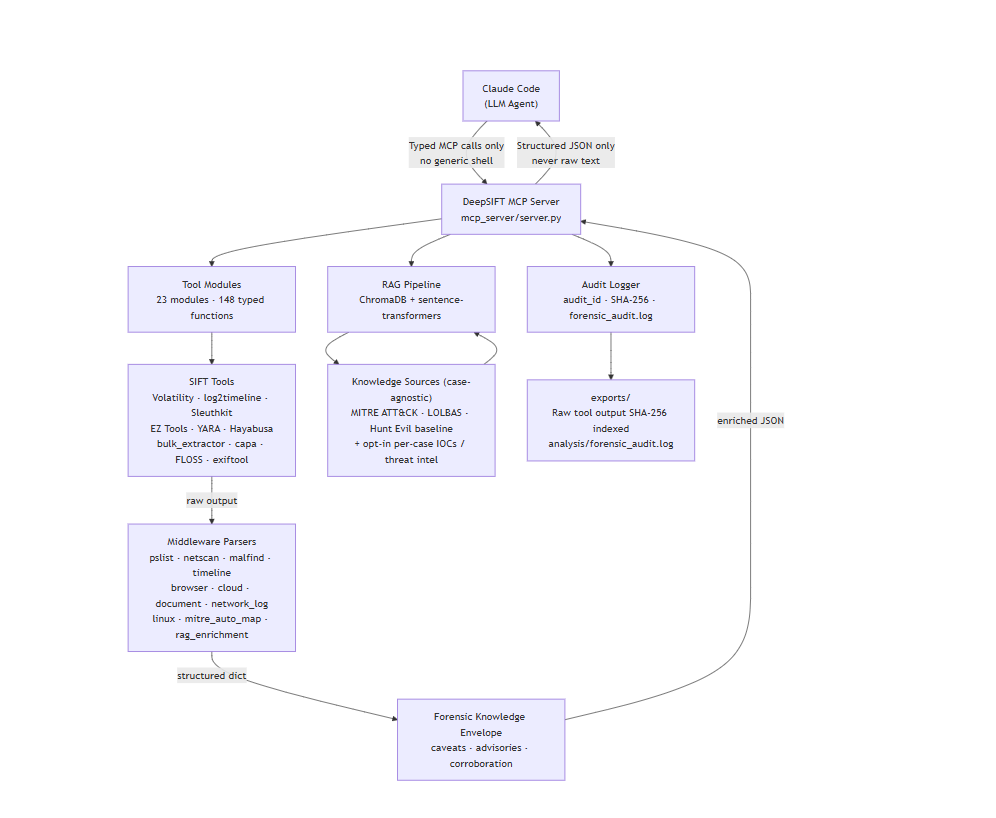
architectural diagram
-
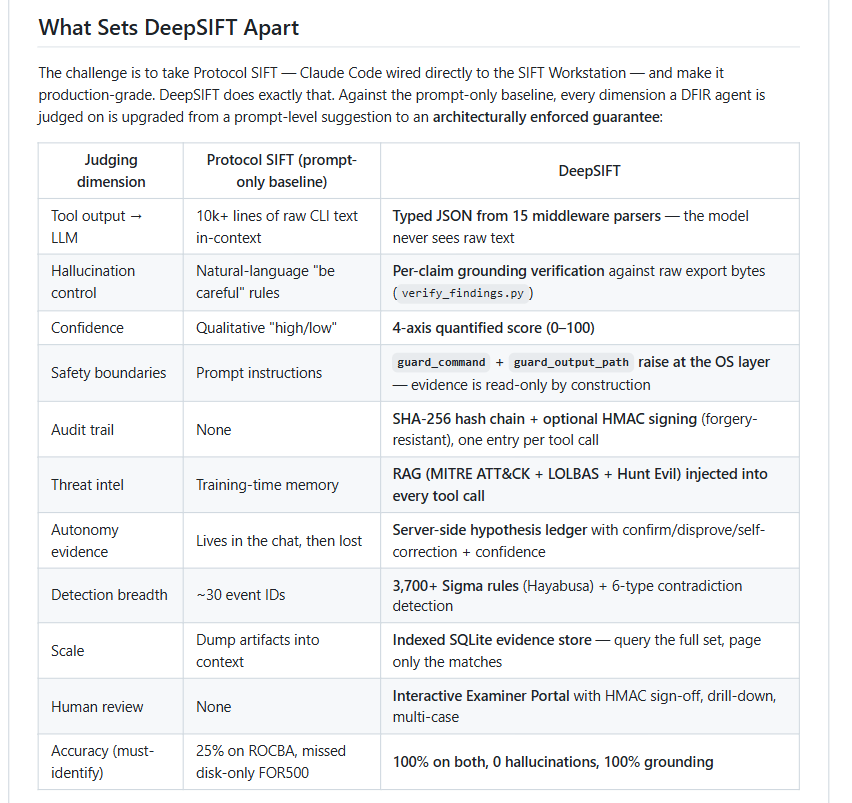
what makes us different
-
html view
-
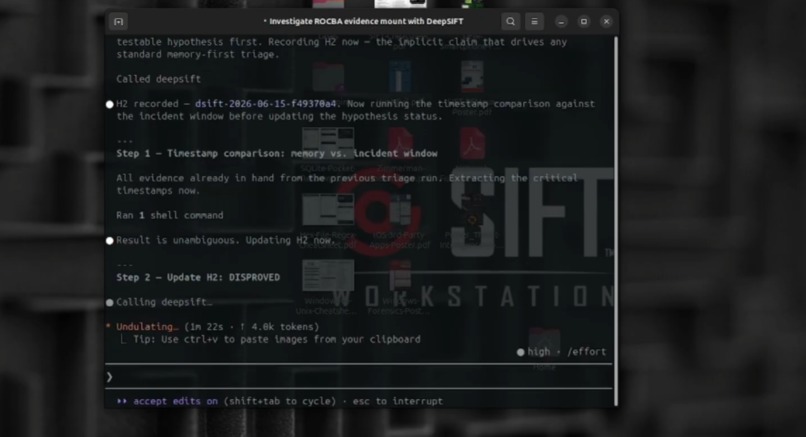
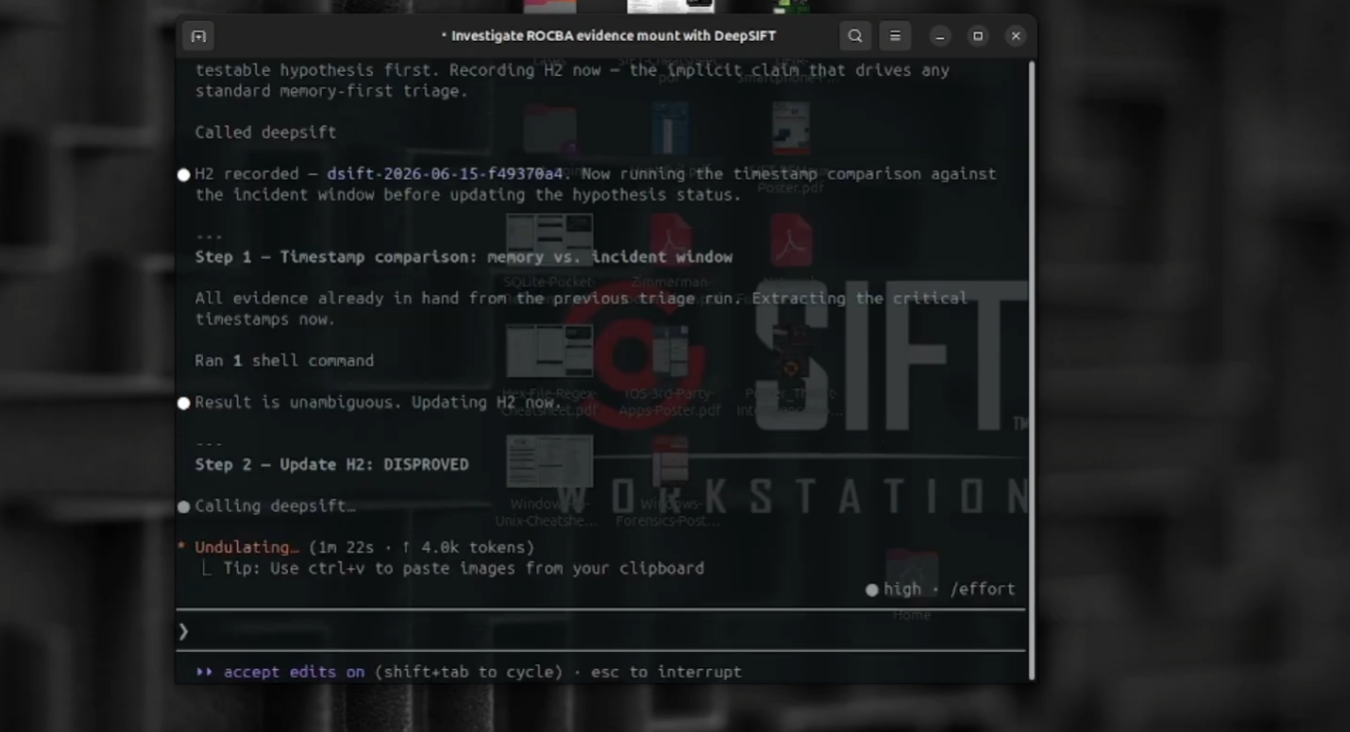
self correction
-
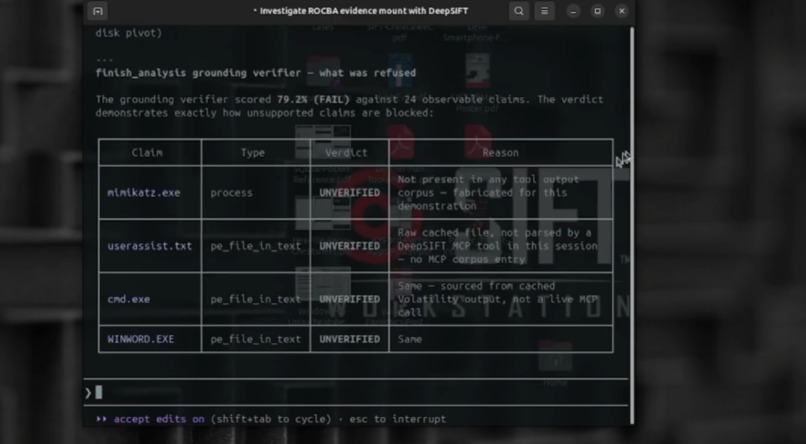
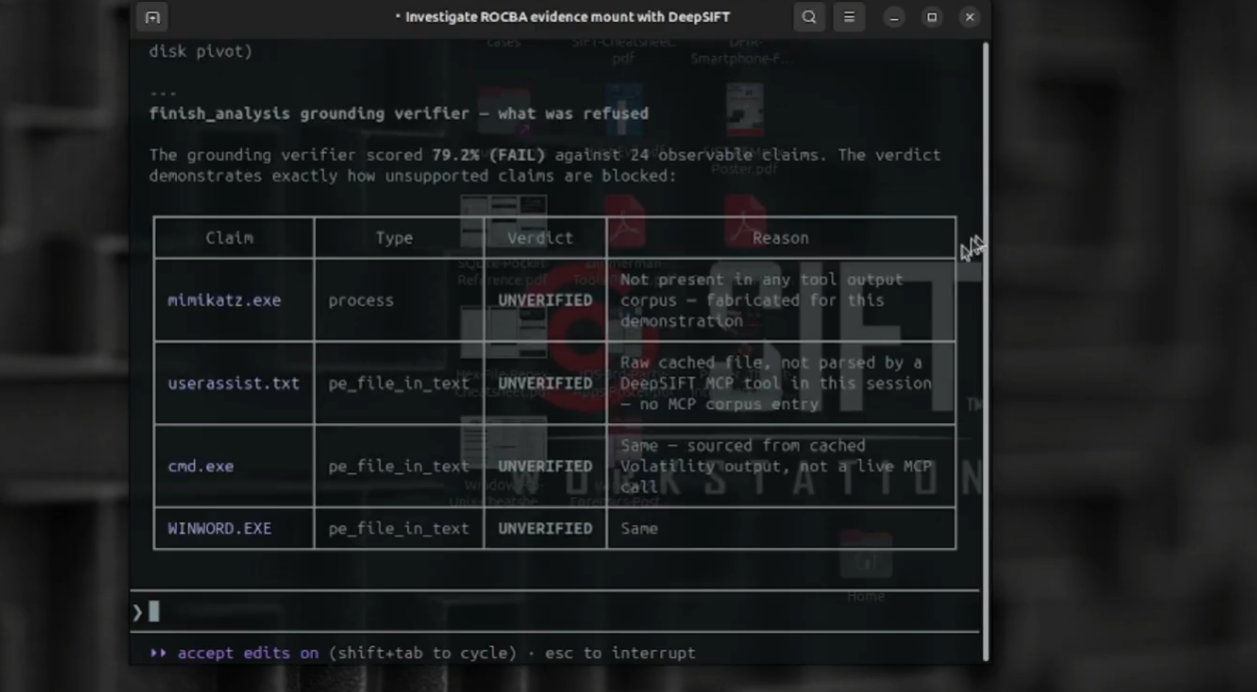
grounding verifier
Inspiration
In November 2025, Anthropic disclosed GTG-1002 - a state-sponsored operation that ran reconnaissance, exploitation, and lateral movement through an AI agent at 80-90% autonomy, at request rates a human team could never match. That was the offensive side. The defensive side is the SANS SIFT Workstation and Protocol SIFT, which connects an AI agent to 200+ forensic tools through MCP.
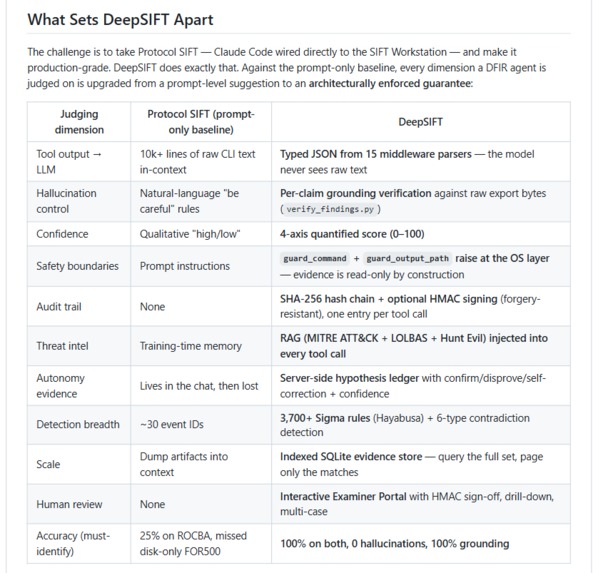
Protocol SIFT works. But it pipes raw command-line output straight into the model's context, relies on natural-language safety rules, and asks the analyst to trust what comes back. In digital forensics, where findings can end up in court, that is the wrong trust model. A single hallucinated process name or fabricated IP can sink a case. We built DeepSIFT to make the agent's output something a practitioner can actually stand behind - traceable, bounded, and reproducible.
What it does
DeepSIFT is an MCP middleware layer that turns Claude into a zero-hallucination DFIR analyst on the SIFT Workstation. Instead of letting the model interpret raw tool text, DeepSIFT:
- Exposes 155 typed forensic MCP tools (148 forensic + 7 control/utility) across memory, disk, registry, browser, email, cloud, network, anti-forensics, and file-carving - each running a real binary (Volatility 3, Sleuth Kit, EZ Tools, Plaso, YARA, Hayabusa, bulk_extractor, capa, FLOSS, exiftool).
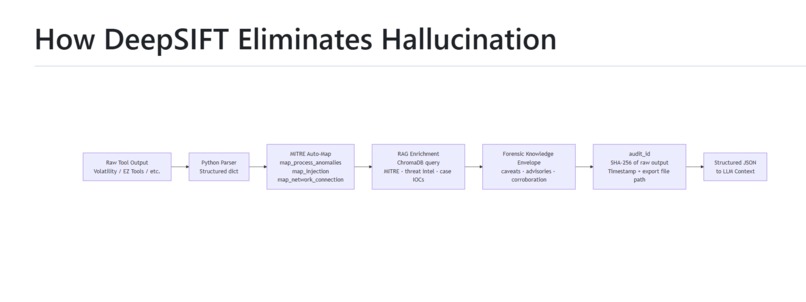
- Parses every tool's output into structured JSON in Python BEFORE the LLM sees it - raw text never reaches the context window.
- Auto-tags findings with MITRE ATT&CK and enriches them with RAG threat intelligence (MITRE catalog, LOLBAS, SANS Hunt Evil baseline) at call time.
- Verifies every claim against the raw evidence it cites (grounding), scores confidence on a transparent 4-axis 0-100 scale, and writes a tamper-evident, HMAC-signable chain of custody.
- Captures the agent's reasoning as a hypothesis ledger - record, confirm, disprove, self-correct - so autonomous reasoning is auditable, not anecdotal.
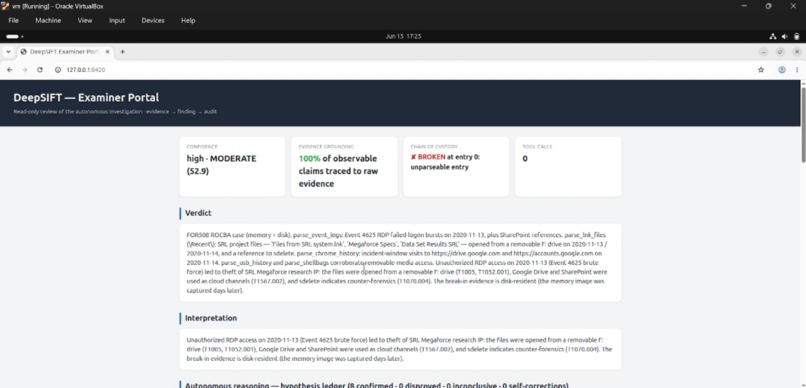
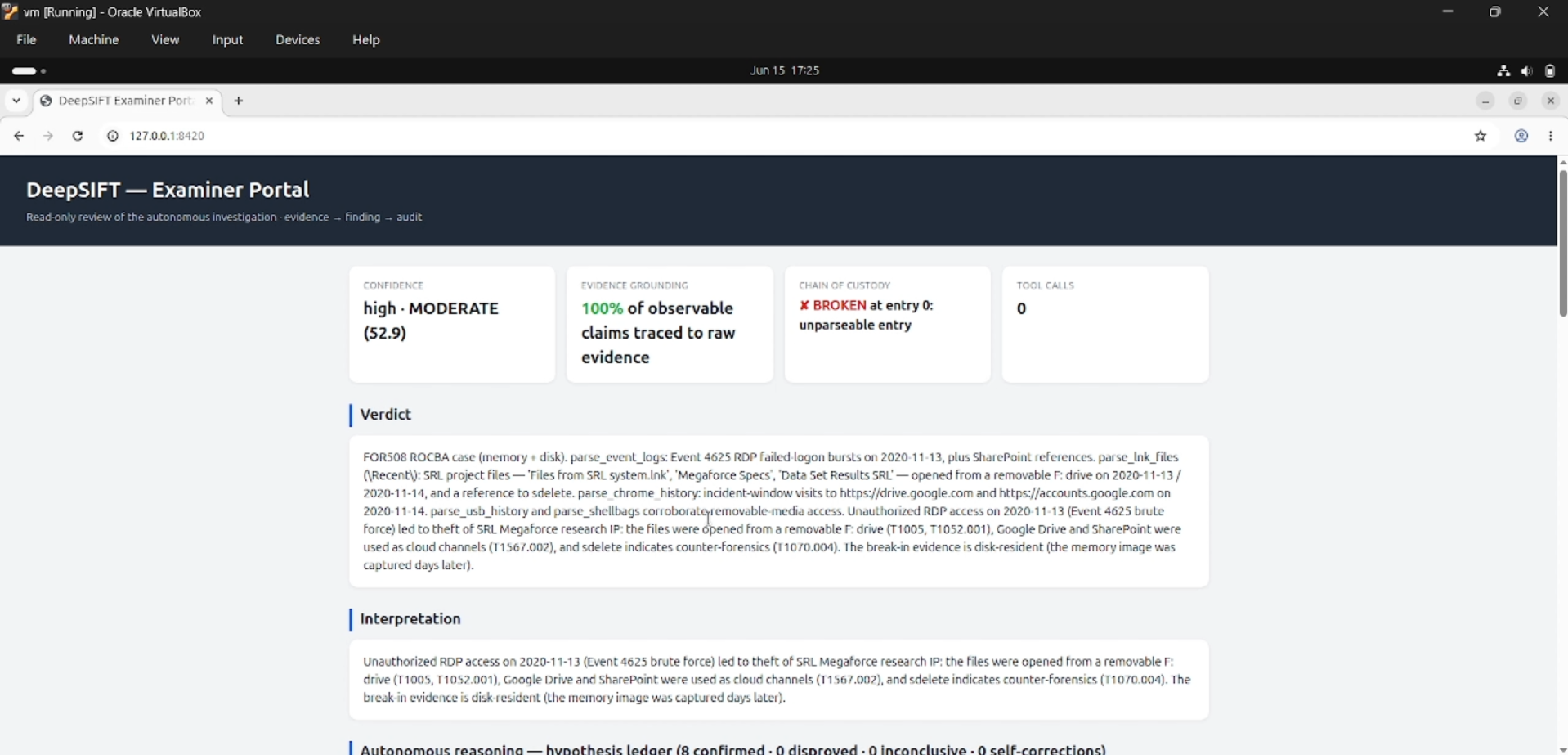
- Ships an Examiner Portal (Python standard library, zero installs) for human review, drill-down to raw evidence, and examiner sign-off.
On the SANS ROCBA case (FOR508, memory + disk), the prompt-only baseline scored 0 of 4 must-identify findings; DeepSIFT scored 4 of 4 with 0 hallucinations. On a disk-only FOR500 case, DeepSIFT scored 4 of 4 again - both scored by an identical, published scorer against ground truth derived from the case scenario.
How we built it
We chose the Custom MCP Server pattern - the architecture SANS called the most sound and the most work - because it lets us enforce safety in code rather than in prompts.
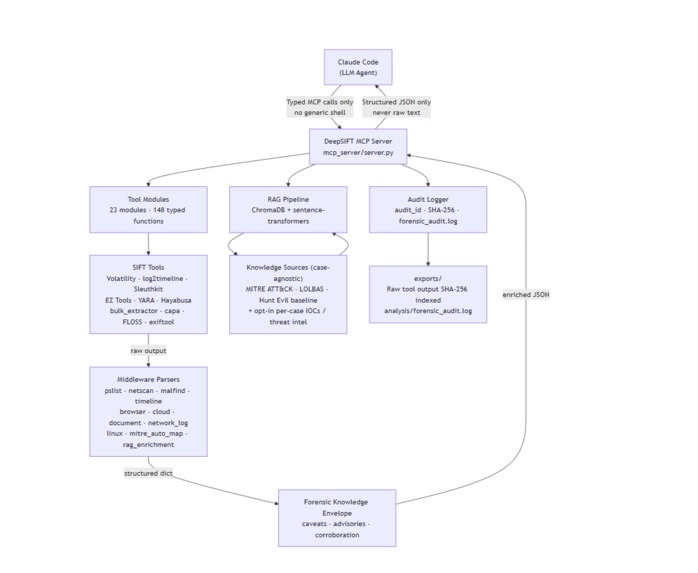
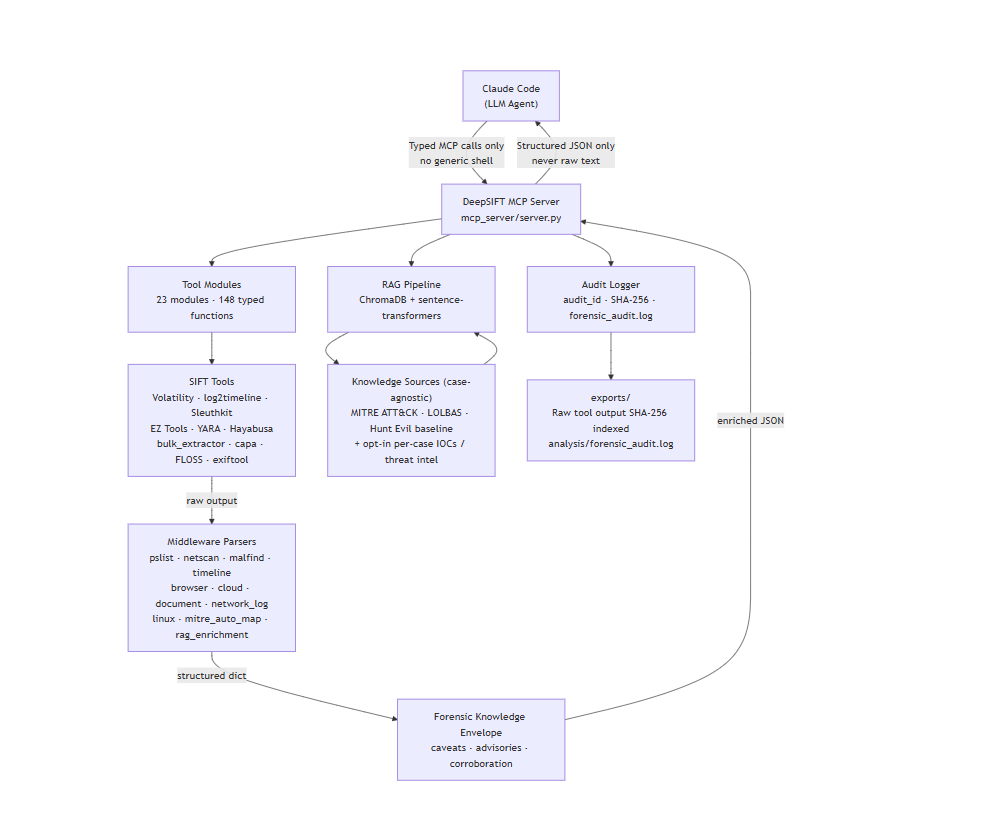
Architecture, end to end:
Claude Code (agent) -> typed MCP calls only (no generic shell)
DeepSIFT MCP server (FastMCP) -> runs a fixed forensic binary via an argv list (never shell=True)
Middleware parsers (pslist, netscan, malfind, timeline, browser, cloud, document, network, linux, ...) -> structured dict
MITRE auto-map + RAG enrichment + forensic-knowledge envelope (caveats / advisories / corroboration) -> enriched JSON back to the model
- Audit logger -> SHA-256 of raw output, appended to a hash-chained forensic_audit.log
Key design decisions and tradeoffs:
NO run_shell tool. Every tool hard-codes its own binary and builds an argv list, so the model can never choose a binary or smuggle a second command. Two guards add defense in depth: guard_command blocks destructive/exfiltration binaries and shell tokens, guard_output_path blocks any write under /cases/, /mnt/, /media/. Both raise PermissionError at the OS level. The tradeoff is more code per tool - but safety becomes a property of the system, not a request to the model.
Grounding as traceability, not magic. Our grounding verifier extracts atomic facts (IPs, file names, domains, URLs, PIDs) from each claim and checks them against the raw bytes the cited audit_ids produced. We deliberately treat MITRE technique IDs as DERIVED analytic tags, validated for well-formedness but excluded from the raw-grounding denominator - requiring a derived tag to appear verbatim in CLI output would be a category error that guarantees failure. finish_analysis hard-blocks if zero claims can be traced.
Quantified, transparent confidence. A 4-axis score (tool reliability, corroboration across evidence categories, IOC specificity, MITRE accuracy, with a grounding penalty) replaces "high/medium/low." It's a documented heuristic a judge can recompute, not a black box.
Tamper-evident AND tamper-resistant custody. Each audit entry binds the previous entry's hash, so any modify/insert/delete breaks the chain. Set DEEPSIFT_AUDIT_KEY (held off the evidence host) and the chain is additionally HMAC-signed - an attacker who rewrites the whole log still can't forge signatures without the key.
Token-scale by design. The model only ever sees each tool's capped summary JSON; the full raw evidence goes to the on-disk audit record. For full-disk scale, index_evidence ingests the complete artifact rows into a standard-library SQLite store and query_evidence returns only the matching subset - reaching a 100k-row MFT without dumping it into context. A dependency-light alternative to standing up OpenSearch.
Which qualities of autonomous execution we target: self-correction (the hypothesis ledger + adversarial_review), accuracy (grounding + observation/interpretation split), constraint enforcement (architectural guards), and audit-trail traceability (every finding cites an audit_id backed by a hash-chained raw export).
.png)
.png)
Challenges we ran into
The evidence was on the wrong layer. The ROCBA memory image was captured three days after the incident, so the break-in only exists on disk. This forced us to make disk-only investigation a first-class path and taught the agent to recognize when its starting assumption (look in memory) is wrong and pivot - the exact self-correction the hackathon asks for.
Dirty, live-acquired registry hives. Acquired hives ship TxR .blf logs, not the .LOG1/.LOG2 files EZ Tools expect to replay, so the parsers silently returned zero rows. We run RECmd/SbECmd with --nl and resolve ControlSet001 (acquired hives have no CurrentControlSet symlink), parsing them as-acquired.
Cross-case contamination. EZ Tools reuse CSV output directories, so one case's output could be re-read as another's evidence. Every wrapper now clears its own output directory before running.
Windows tools on a Linux box. EZ Tools are .NET assemblies; on SIFT we invoke them via dotnet, subdir-aware, and mount NTFS volume images read-only through the kernel ntfs3 driver for images whose backup-boot sector is truncated.
Offline / air-gapped operation. When torch / sentence-transformers or the embedding model isn't available, the RAG knowledge base falls back to an offline hashing embedder seeded from the bundled corpus - no network required.
Honest benchmarking. We kept the RAG corpus case-agnostic (per-case IOCs are opt-in, never auto-loaded) so one case can't bias another, and we score Protocol SIFT and DeepSIFT with the identical, content-based scorer. The ground truth is derived from the published scenario, not an official answer key - so we tell judges to verify the evidence, not the number.
What we learned
Architectural enforcement beats prompt instructions. The moment safety lives in guard_command and guard_output_path rather than in a system prompt, "be careful with evidence" stops being a hope and becomes a guarantee.
Grounding is about traceability and honesty. The win isn't claiming the model is always right - it's making every claim cite the exact raw bytes that support it, and being explicit about what the verifier can and cannot check.
Disk-only is not a degraded case. Some of the most important evidence (LNK files, shellbags, UserAssist, browser history, MFT) lives only on disk. Treating disk-only as first-class, not a fallback, is what let us recover findings the baseline missed.
Capturing reasoning matters as much as producing it. A server-side hypothesis ledger turns "the agent self-corrected" from a claim into an artifact a reviewer can inspect.
What's next for DeepSIFT
- Broader evaluation across more SANS and community cases (including the vigia-cases standardized benchmark, which the runner already supports).
- Stronger grounding: move beyond atomic substring matching toward relationship-aware verification, and add per-finding confidence alongside the investigation-level score.
- Live triage: extend the MCP surface to remote endpoints and SIEM sources for real-time response, not just post-acquisition analysis.
- Community hardening: more YARA/Sigma coverage, more parsers, and packaging so any practitioner can deploy DeepSIFT on a stock SIFT Workstation in minutes.
TRY IT (NO API KEY NEEDED)
python3 preflight.py # which forensic tool groups are operational here
pytest -q # full test suite (75 passed, 1 skipped)
python3 verify_findings.py # re-check every claim vs raw evidence + recompute the chain
python3 examiner_portal.py # interactive review UI -> http://127.0.0.1:8420
Built for the SANS DFIR "Find Evil!" hackathon. MIT licensed.
Built With
- bash
- claude
- eztools
- hayabusa
- html5/css3
- javascript
- mcp
- mitre
- node.js
- openclaw
- plaso
- pyaescrypt
- pytest
- python
- python-gnupg
- sanssiftworkstation
- tesseract
- tsk
- volatility3
Log in or sign up for Devpost to join the conversation.