-
-
Framework
NovelForge AI
A Gemini 3–powered multi-agent system that turns a single sentence into a consistent long-form story.
Input: one-line idea (+ optional constraints)
Output: Series Bible → Characters → Outline.jsonl → Slice plan → Multi-chapter drafts → Compressed memory (for consistency)
TL;DR
Long-form storytelling is not just “write better text” — it’s a structure + memory problem.
We solve it using:
- Multi-agent specialization (like a real writing team)
- Hierarchical generation (chapter → slice → prose)
- Compressed memory injection (no embeddings / no vector DB)
- Gemini 3 for planning, structured outputs, drafting, and memory compression
About the Project
What inspired us
Most LLM writing demos end at a short story, because once narratives become long, they drift:
- characters “change personality”
- canon facts contradict
- pacing collapses across chapters
We wanted a simple experience:
Type one sentence. Get a structured, multi-chapter story that stays consistent.
What we built
A workflow-orchestrated, Gemini 3 multi-agent pipeline that generates:
- a Series Bible (world rules + plot beats)
- a Character System
- a chapter outline (
outline.jsonl) - a slice plan (scenes per chapter)
- prose drafted slice-by-slice
- and memory compressed after each chapter and injected into the next prompts
Why this matters (Market + Technical Gap)
Market opportunity
The books / publishing ecosystem is already massive:
IBISWorld estimates global book publishing industry revenue at ~$126.9B in 2025:
Global Book Publishing Industry Analysis, 2025 - IBISWorldGrand View Research estimates the global books market at ~$150.99B in 2024, with continued growth projections:
Books Market Size, Share & Growth | Industry Report
Even though these are overall book market numbers (not “novels only”), long-form storytelling remains a high-value content segment—especially as serialized digital fiction and downstream IP expand.
The technical gap: long-form writing doesn’t fit into one model call
A standard novel commonly falls around 70k–100k words (genre dependent).
How Many Words in a Novel? (Reedsy)
Even with long-context models, “single-shot novel generation” is constrained by:
- limited controllability,
- output limits,
- and the inability to preserve canon over many chapters without memory.
Public summaries for Gemini 3 Pro preview commonly cite up to ~64k output tokens and a very large input context window.
Gemini 3 Pro (Preview) - LLM Stats
So the real challenge becomes:
How do we scale storytelling beyond a single prompt while maintaining structure and long-term consistency?
Solution Overview
We scale beyond one context window by combining:
- specialized agents (planning, outlining, slicing, drafting)
- hierarchical decomposition (chapters → slices)
- compressed memory injection (summarize canon + recap after each chapter)
This makes long-form generation structured, stable, and explainable.
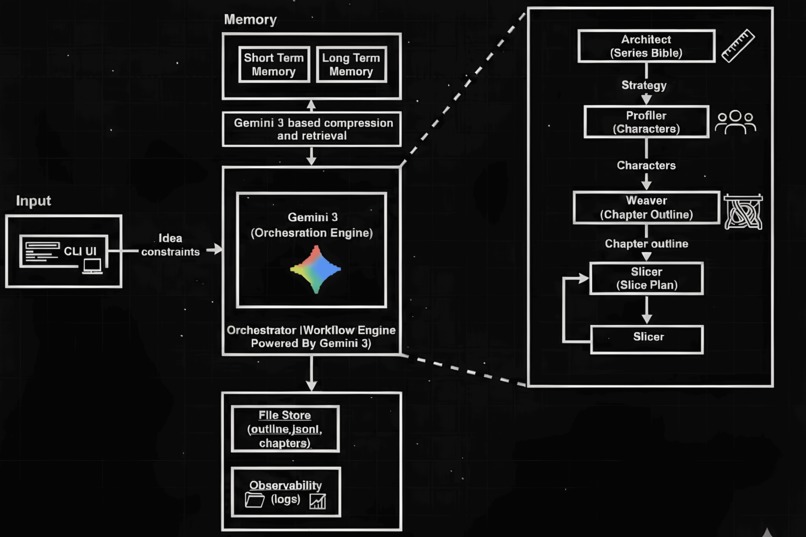
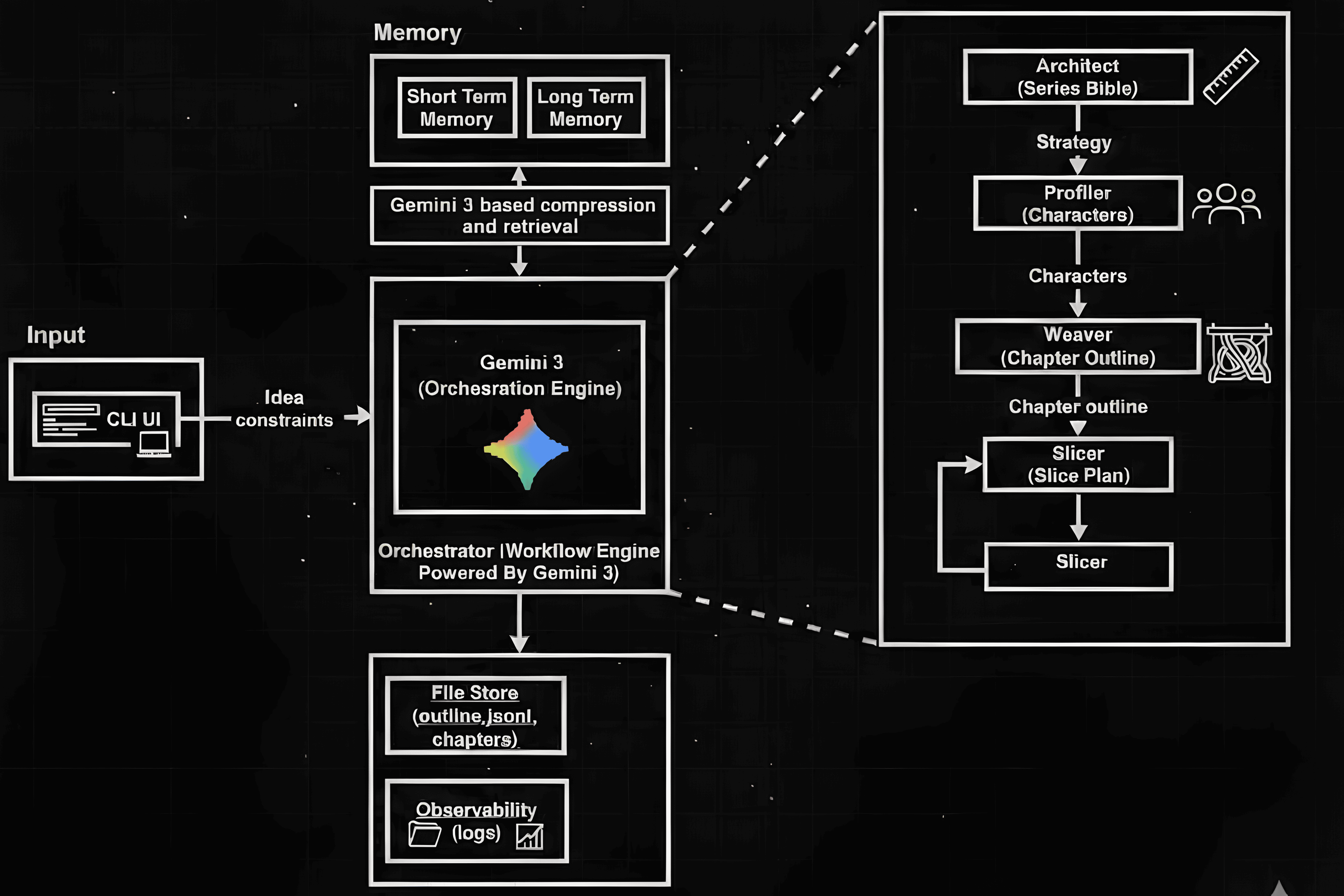
Architecture (High-Level)
Client → Orchestrator / Job Runner → Agents → Artifacts + Memory
- The Orchestrator owns the workflow:
- runs the chapter loop + slice loop
- assembles prompts
- injects compressed memory
- validates outputs
- persists artifacts
- Agents stay role-focused (no messy cross-calls)
- Memory is updated per chapter and injected into next steps
Agent Design (Role-Based Multi-Agent Pipeline)
Architect — Series Bible Builder
Turns the one-line idea into a Series Bible: world rules, plot beats, themes, stakes, and long-range structure.
Goal: make the story writeable for many chapters.
Profiler — Character System Designer
Builds a coherent cast: motivations, fears, goals, arcs, and relationship graph.
Goal: create characters that generate conflict naturally.
Weaver — Chapter Outline Generator
Creates the executable chapter plan: chapter summaries, turning points, pacing roles, and cliffhangers.
Goal: structure long-form narrative so drafting doesn’t drift.
Slicer — Chapter-to-Slice Decomposer
Breaks each chapter into 3–4 “slices” (scenes) with explicit objectives, conflicts, and transitions.
Goal: keep generation manageable and controllable.
Writer — Slice-Following Draft Writer
Drafts prose slice-by-slice, preserving tone and canon, and lands the chapter hook.
Goal: produce readable text while respecting the plan.
Memory System (Compressed Summaries, No Embeddings)
We intentionally do not use embeddings or a vector database. Instead, after each chapter, we compress the chapter into:
- Short-term memory: current arc, recent events, immediate continuity constraints
- Long-term memory (canon): stable facts (world rules, character truths, timeline constraints)
Then, for the next chapter/slice, the orchestrator:
- loads memory summaries
- injects them into the prompt context
- continues generation with continuity constraints
This yields long-form consistency without retrieval complexity.
Why Gemini 3
Gemini 3 is not just “a good writer model” for us — it is well-suited for a workflow that repeatedly switches modes:
Strong planning + constraint-following Agents like Architect/Weaver require structured reasoning, not just fluent prose.
More reliable structured outputs Our pipeline depends on JSON/JSONL artifacts; format reliability directly affects system stability. Public summaries highlight Gemini 3 Pro’s large context and high output capacity, supporting long-form pipelines.
Gemini 3 Pro (Preview) - LLM StatsGood summarization for memory compression Memory compression needs precise canon extraction + short recap. Gemini 3 performs well at controlled summarization.
In short:
Gemini 3 makes multi-agent orchestration practical because it handles planning, structure, drafting, and compression reliably in one system.
What We Learned
- Multi-agent systems are software architecture, not “more prompts”.
- Memory is the real bottleneck for long-form LLM products.
- Compression + injection is a strong baseline before adding retrieval/embeddings.
References
Built With
- google-ai-studio


Log in or sign up for Devpost to join the conversation.