-
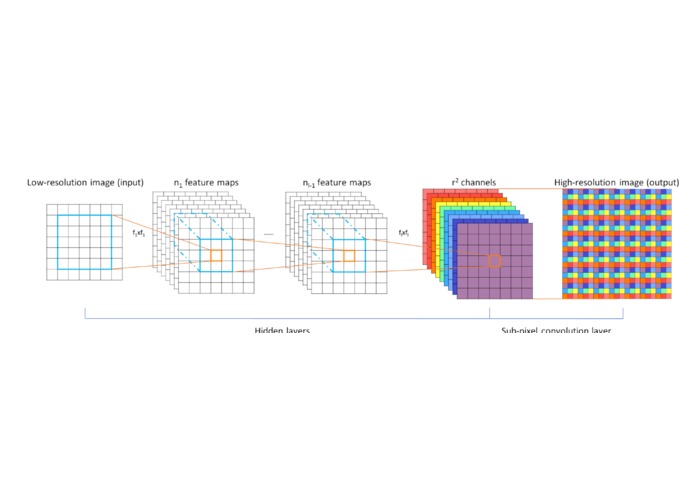
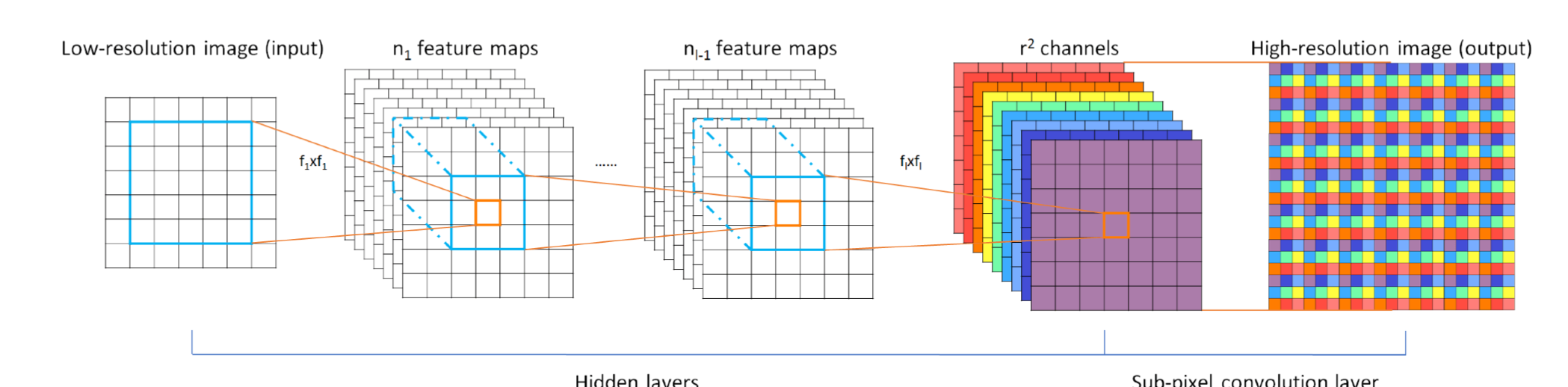
Subpixel Net
-

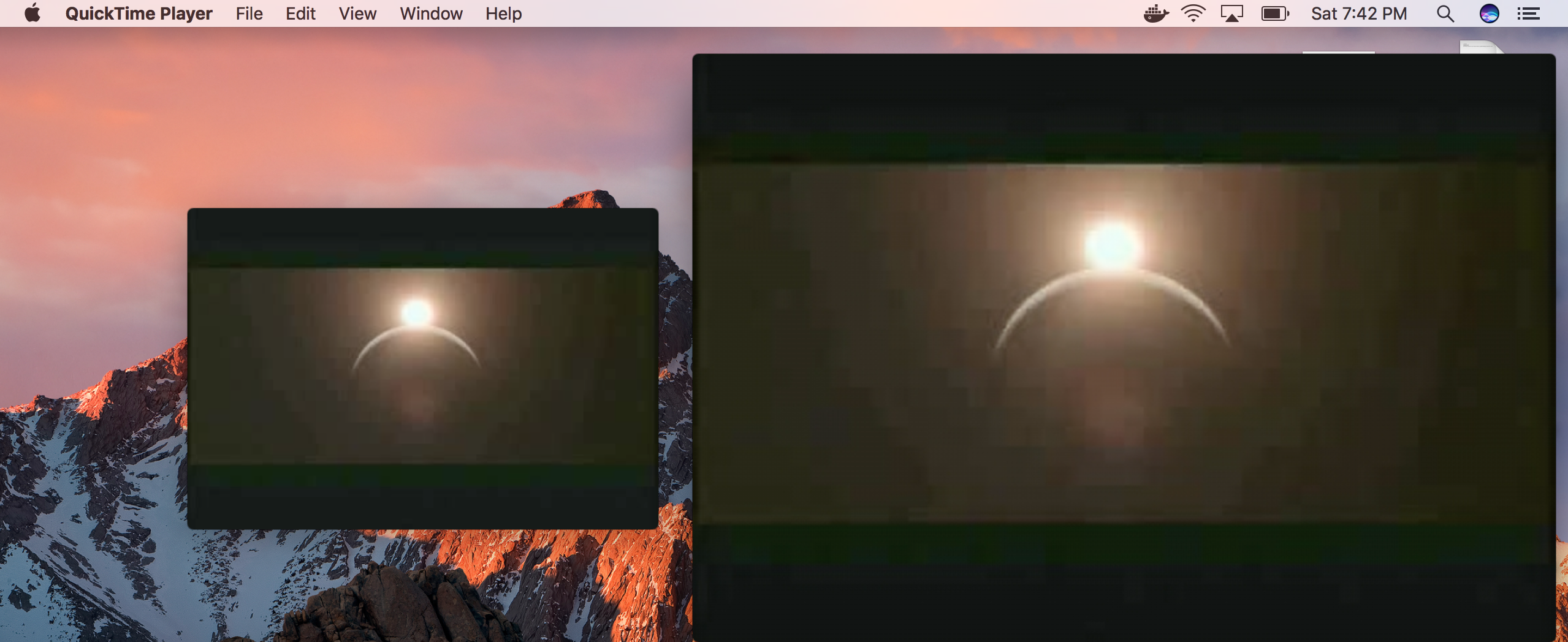
Comparison From One specific frame(Left : Before, Right : After)
-
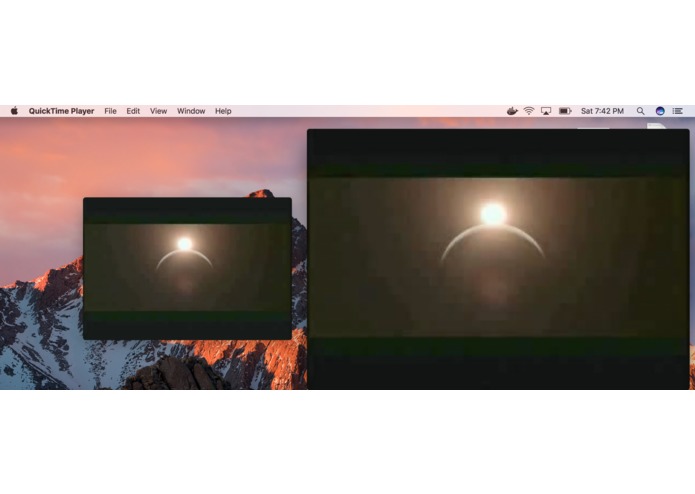
The model upscales the current video by 2x at the exact same resolution!
-

After 10 epochs
-

Left: Before Right After
-

-

Top -> Before Bottom -> After





Inspiration
I started out by watching a simple video before starting the hackathon, I realized how low-res it was... Then my mission started. Also recently I've been looking at other deep learning models on Github, which inspired me to create this AI prediction software with Deep learning. As a high-schooler this project was one of my best projects and I'm proud of it.
What it does (SIMPLE)
Takes Low res video video, outputs High-Res video
How I built it
I first started out with the idea of sub-pixel convolutional nets. I used Theano as my deep learning framework, and existing scientific python libraries for the machine learning algorithms. The way the program upscaled a LR image is through sub pixel convolution nets with fractional stride of 1 in the LR space. Which I found out can be naively implemented by interpolation, perforate or un-pooling from LR space to HR space followed by a convolution with a stride of 1 in HR space. These implementations increase the computational cost by a factor of r2, since convolution happens in HR space.So Given a training set consisting of HR image examples IHR,n = 1...N, we generate the corresponding LR n images ILR , n = 1 . . . N , and calculate the pixel-wise mean. Then it is able that the implementation of the above periodic shuffling can be very fast compared to reduction or convolution in HR space because each operation is independent and is parallelizable in one cycle. Which then allowed the layer to operate log2r2 times faster compared to deconvolution layer in the forward pass. For the training dataset I used the OpenImages Dataset( https://github.com/openimages/dataset) and used this script to resize them(https://github.com/ejlb/google-open-image-download) and got an okay~ model(Trained in a very short time because of the hackathon!!!!!) After getting a model to use I implemented the sub-pixel convolutional nets, the Network layers, and made a few tweaks to the Training methods. After this I used two libraries installed with home-brew called FFmpeg and Libav for the video processing, which converted the video to individual frames(FFmpeg) for the model to pass, and then re-structured the frames in a mp4 format(Libav.)
Challenges I ran into The challenges I ran into very SEVERE
0.5. Tried to run regular convolutional nets, but figured out that it only worked on images.....
- Tried using caffe, which messed up my computer because I was trying to use python bindings
2.Fmpeg was extremely hard to setup
3.Super-resolution model underperformed, had to re-train
- Tried to reconstruct frames to video with FFmpeg but completely failed :(
5.Had to set up subprocess scripts to get around the FFmpeg python bindings
Accomplishments that I'm proud of
1.Finished this project in a record time!
2.Works:)
3.Didn't give up after FFmpeg completely failed
4.Could write a scientific paper on this
What I learned
1.I learned a lot about deep learning, and especially how to pre-train models using perceptual loss
2.How to run subprocess scripts
3.How to implement sub-pixel nets
- More in general about moviepy
What's next for DeepRes
Have to include python bindings for libav, and replace ffmpeg with it
Have to add everything into one script
Have to write a paper on it
4.Have to train the model for much longer!


Log in or sign up for Devpost to join the conversation.