-
-
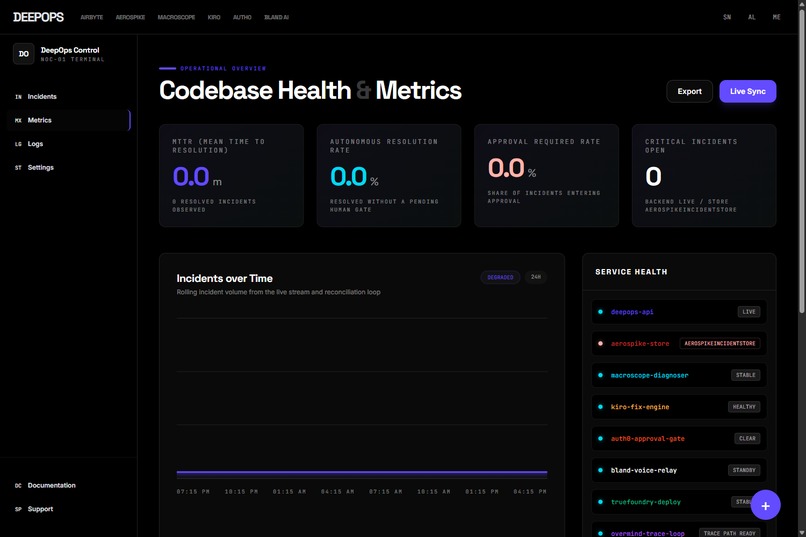
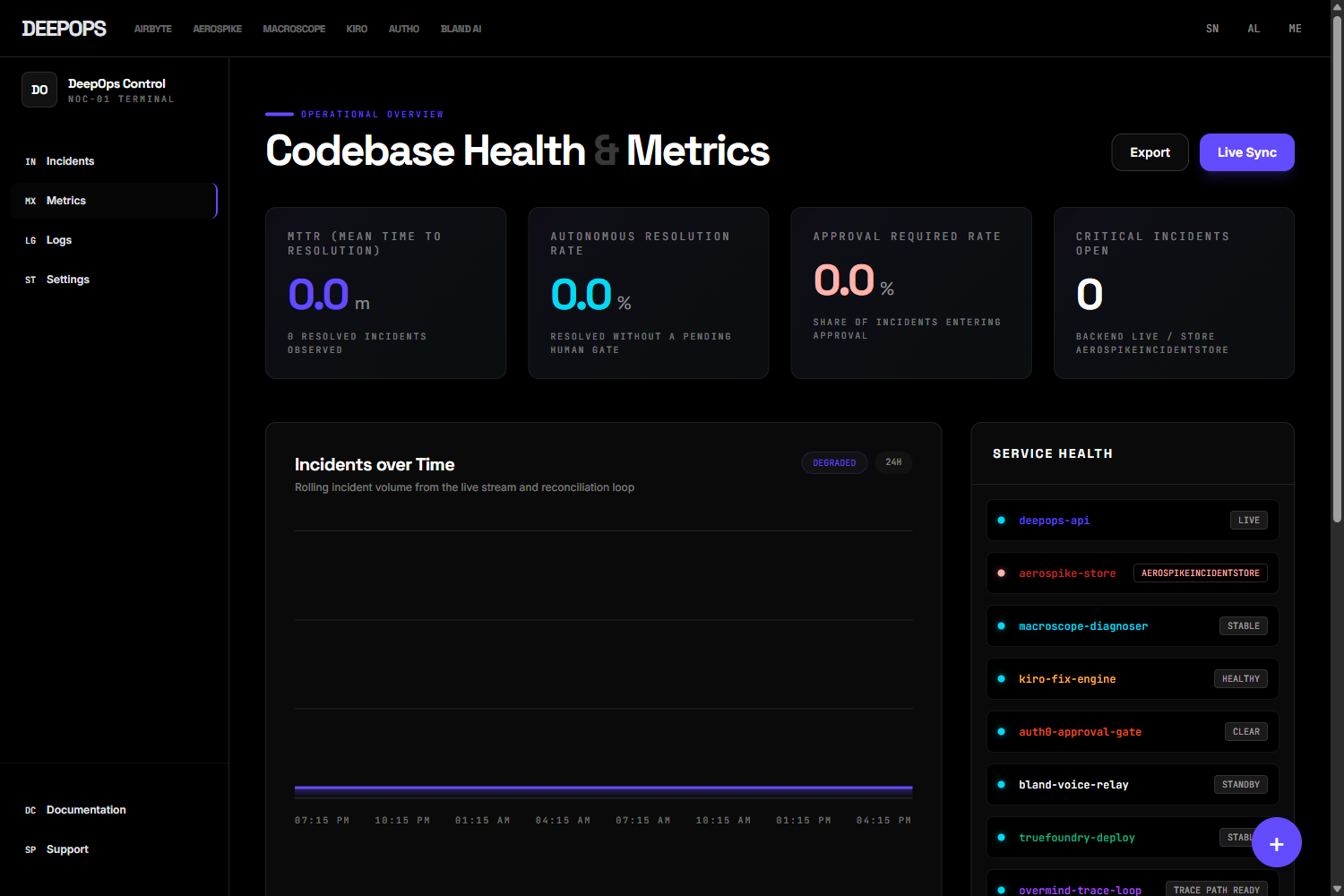
Metrics
-
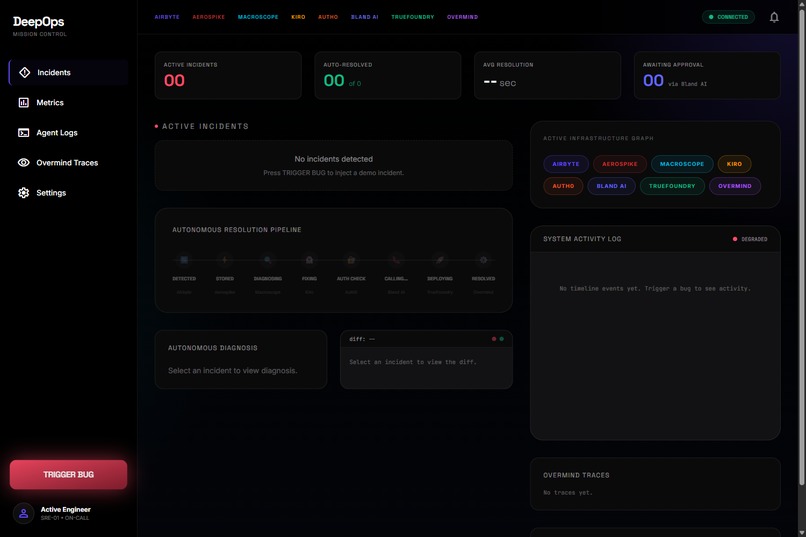
Dashboard
-
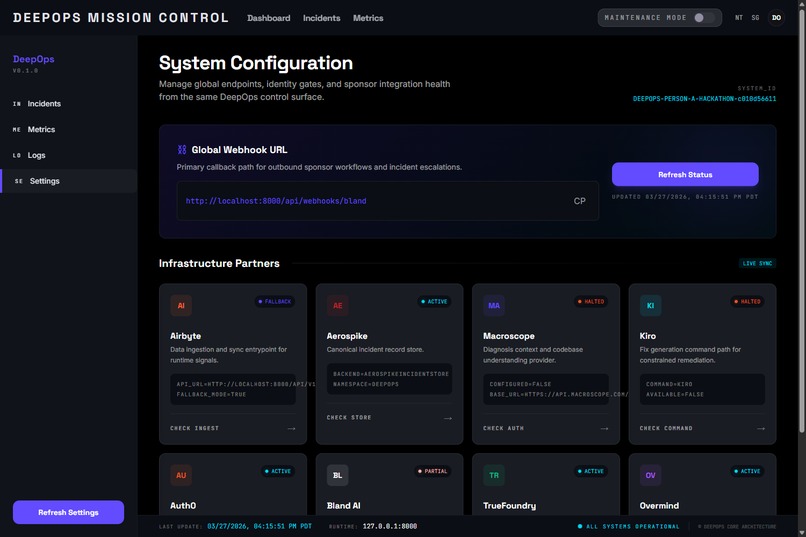
Settings
-

Landing Page
-

All

Inspiration
Production incidents are still handled with fragmented tools, manual debugging, and delayed escalations. We wanted to build a system that acts like an autonomous on-call engineer: detect the issue, understand it, fix what is safe, and involve a human only when risk is high.
What it does
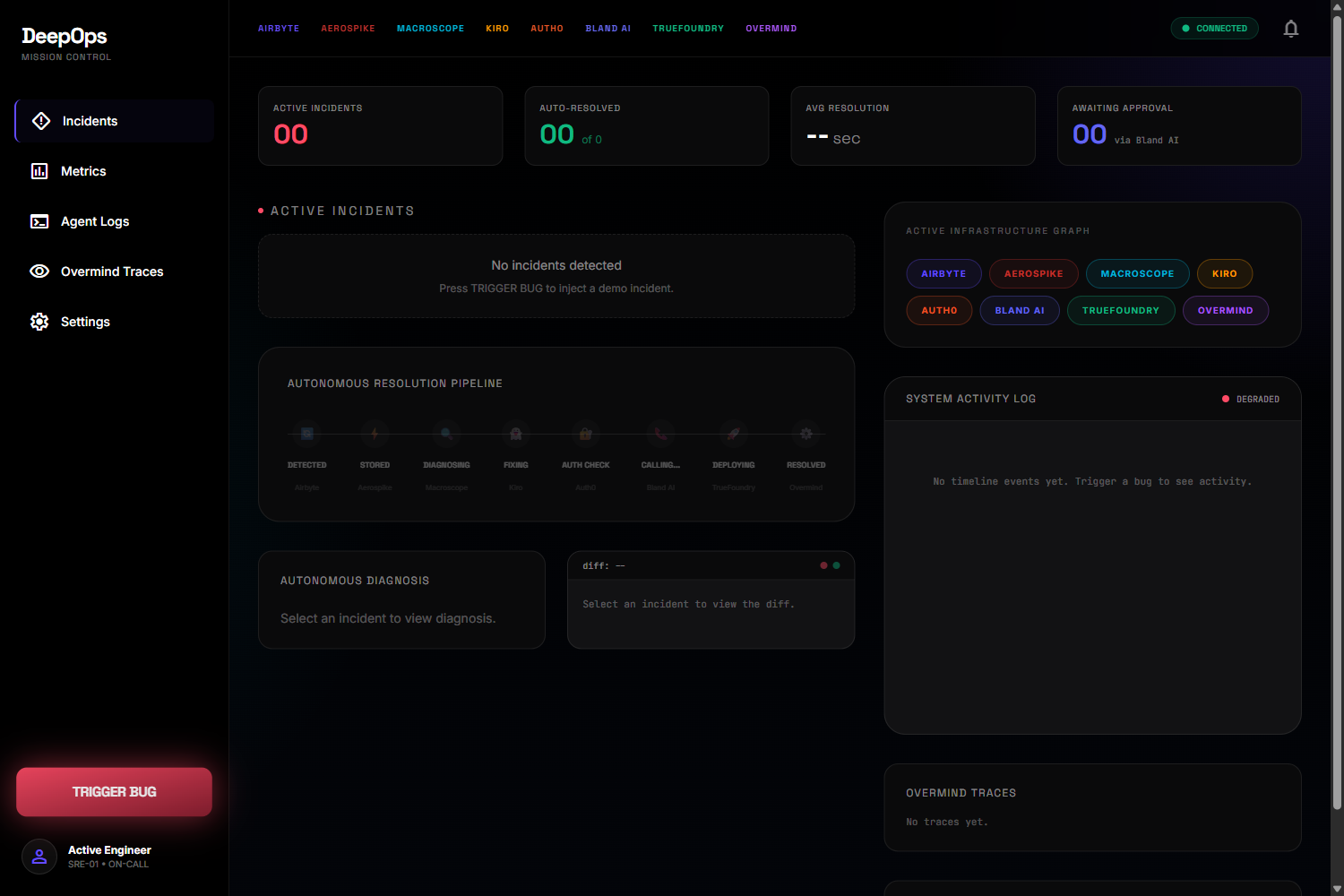
DeepOps is an AI incident-response system for live applications. It monitors a running app, turns failures into canonical incident records, diagnoses root cause, drafts and packages a fix, routes risky changes through human approval, and escalates critical incidents through a phone call when immediate human input is needed.
How we built it
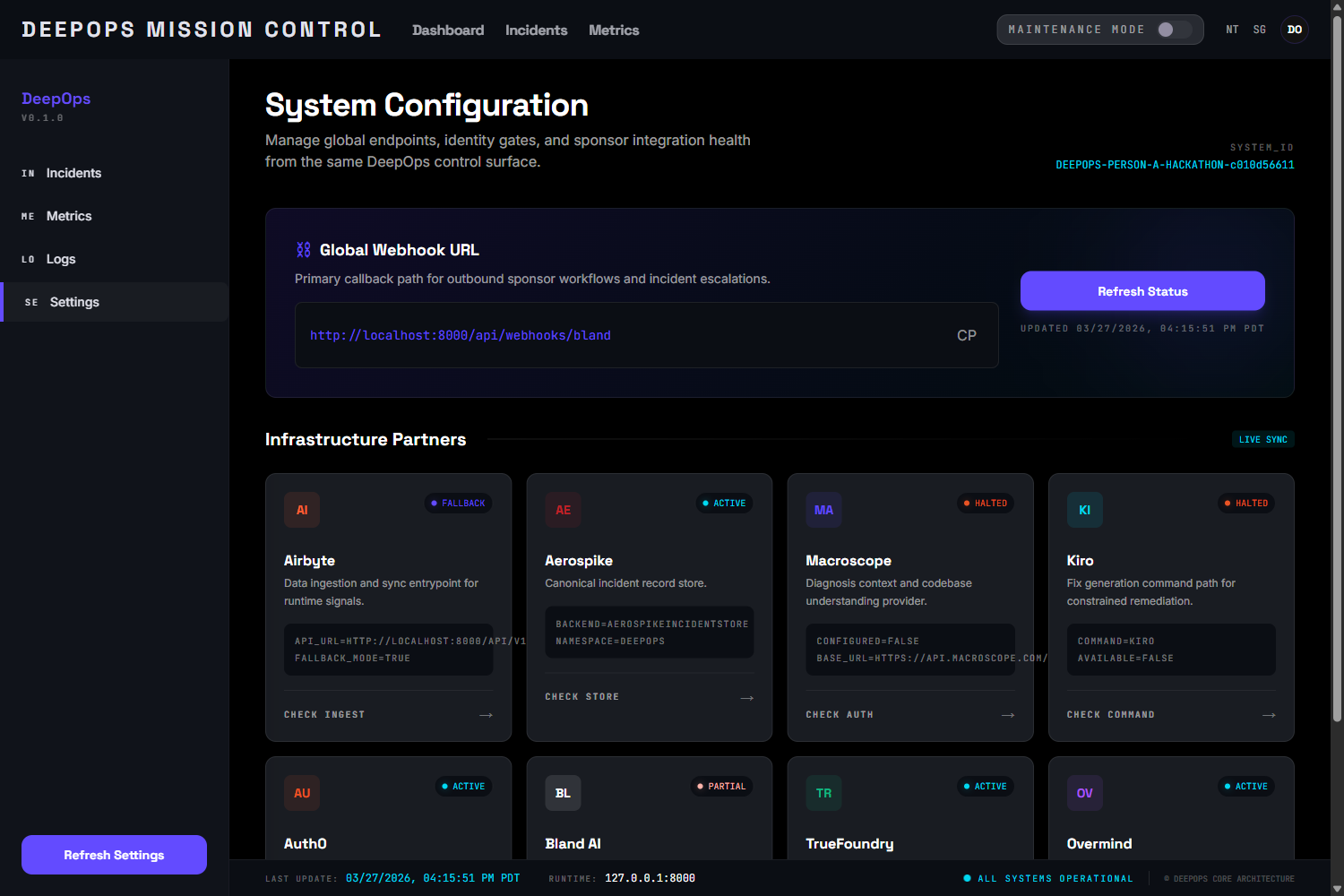
We built DeepOps as a full-stack system with a FastAPI backend and a Next.js frontend. Aerospike stores live incident records, Airbyte supports ingestion flows, Macroscope provides diagnosis context, Kiro handles fix generation, Auth0 supports approval gating, Bland AI enables phone escalation, TrueFoundry handles deployment, and Overmind/Overclaw support tracing and optimization. The frontend provides landing, dashboard, metrics, and settings surfaces connected to real backend APIs and SSE streams.
Challenges we ran into
The hardest part was making the system feel like one coherent incident loop instead of a set of disconnected sponsor integrations. We had to unify the incident schema, align lifecycle states across backend and frontend, wire approval and escalation paths correctly, and keep the demo realistic without hardcoding fake flows.
What we learned
We learned that autonomous remediation is not just about generating fixes. The hard part is designing the control plane around the fix: state transitions, approvals, escalation logic, deployment feedback, and observability. Building that full loop made the project much stronger than a single-agent demo.


Log in or sign up for Devpost to join the conversation.