-
deepmersion in a nutshell
-
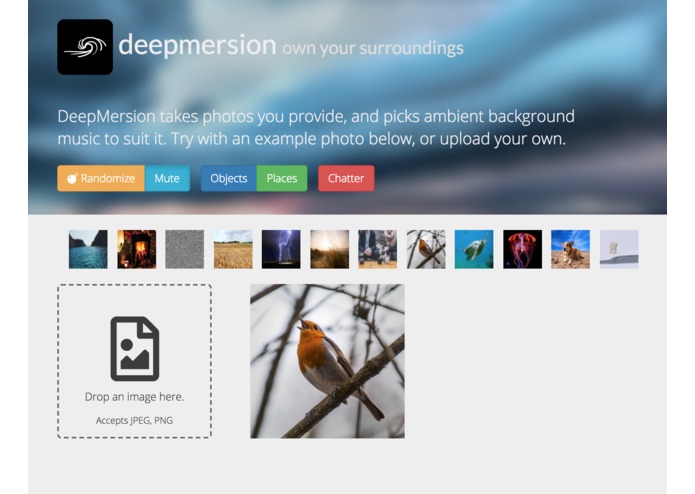
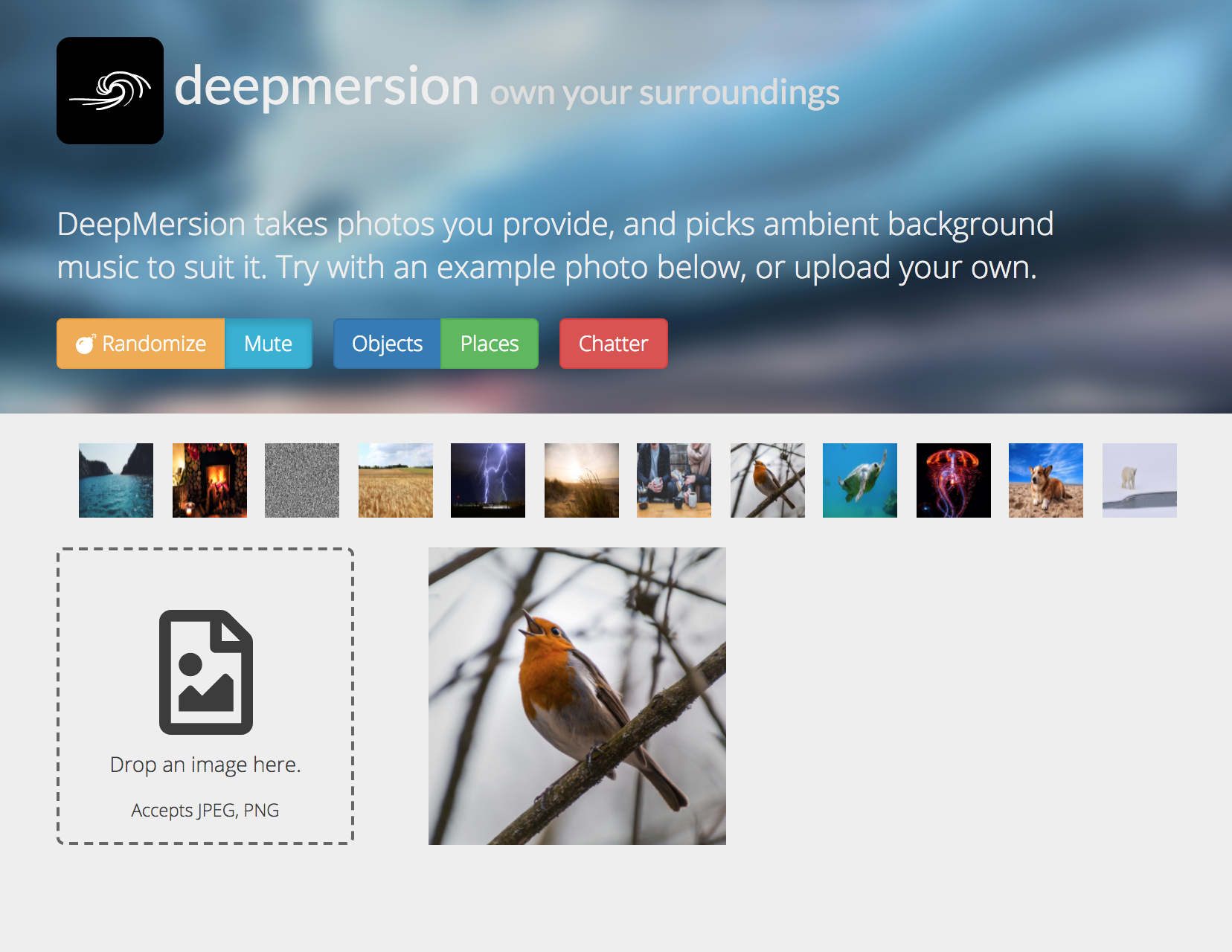
Website
deepmersion
own your surroundings
Motivation
Maintaining focus in the present can be extremely hard. Numerous distractions left, right and centre often impede us to achieve the truly important objectives (cf. performing well at hackathons). One incredible resource for dealing with these issues are ambient sound generators - the proper sound, along with noise-cancellation headphones, can plentifully boost one's productivity.
Unfortunately, we have found that existing solutions for generating ambient sounds either restrict users to one specific sound (rainymood.com), or have an elaborate interface for manually mixing a multitude of sounds (asoftmurmur.com). These options give the user either too little or too much choice---the former's imposed sound choice might not always be appropriate to the surroundings, while the latter might add significant time spent tuning the sound, inadvertently causing an additional distraction (as at least one of the creators of this repository has experienced personally!).
We present deepmersion.com---a prototype of the 'one ambient sound generator to rule them all', simultaneously leveraging three state-of-the-art neural network architectures to provide the user with the optimal level of choice.
High-level outline
We believe that the key principle of immersion in sound requires either disengaging other senses (e.g. by closing their eyes), or the sound reflecting a distilled version of one's surroundings. This keeps the auditory experience consistent with the perceived world, making it less artificial. The first option can be quickly discarded, since the primary use case of our app involves productivity-boosting (of course, other applications of deepmersion are more than possible). Therefore, we would ideally want the generated ambient sound to match the user's surroundings. Deepmersion was built with this as primary objective---specifically, making it way simpler to do so compared to the extensive manual fine-tuning offered by existing solutions. The user provides an image to our system (for our main use case, this will be a shot of the user's immediate surroundings) and the system responds with an appropriate ambient sound that captures the content of the image.
We find this approach to be optimal - there are no adjustment requirements from the user, with the sound generated still often being appropriate.
Internals overview
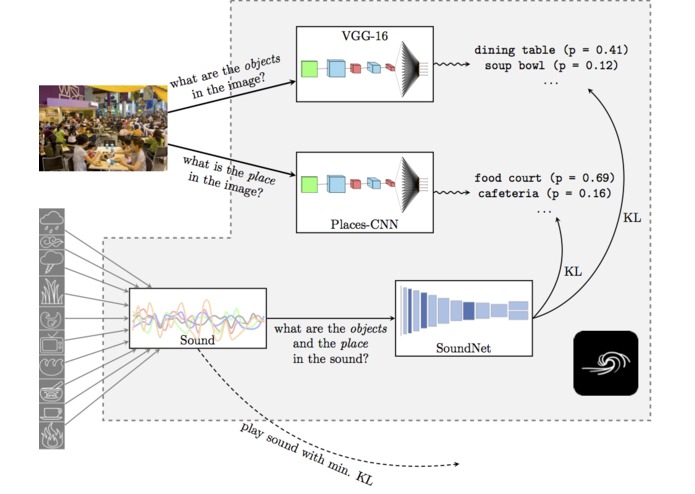
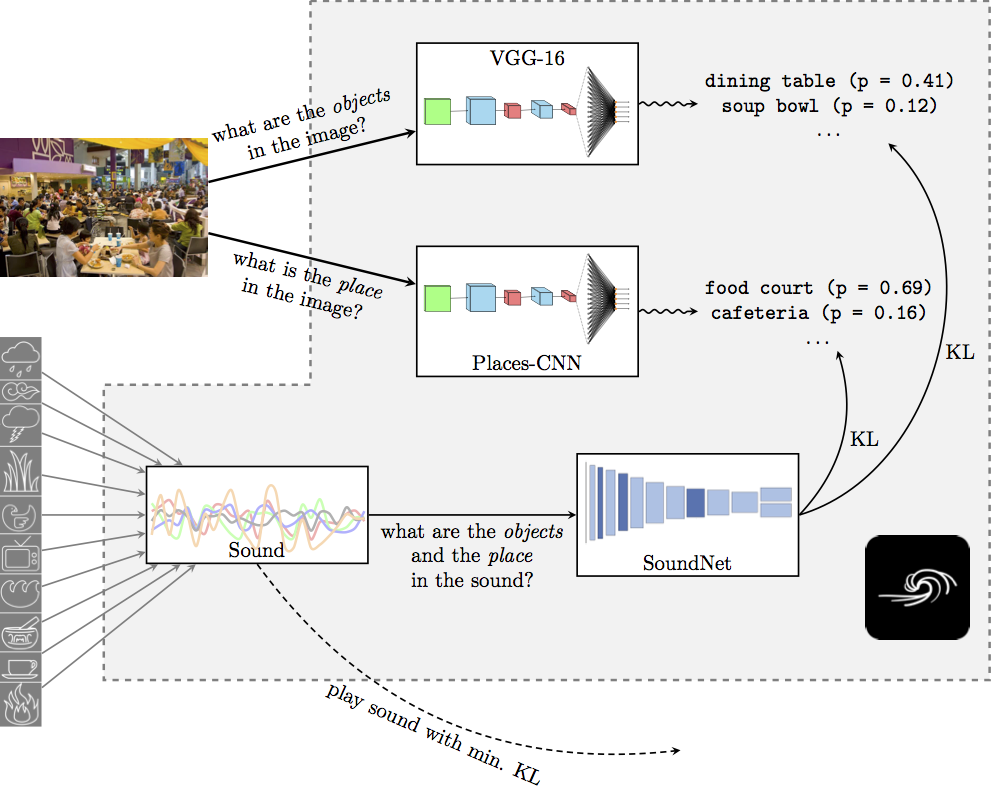
When an image is submitted to the system, its content is analysed by two state-of-the-art neural networks for object and scene recognition:
- VGG-16 (Simonyan and Zisserman, 2014) for extracting the most prominent objects from an image (pre-trained on the ImageNet dataset - 1000 object classes);
- Places-365-CNN (Zhou et al., 2017) for extracting the scene characteristics of an image (pre-trained on the Places2 dataset - 365 scene classes).
These are capable of extracting robust high-level image features. In order to match the image with appropriate sounds, a database of ambient sounds is constructed---in our case, we have built a dataset of superimpositions of the 10 basic sounds from A Soft Murmur. These sounds are then fed through a SoundNet neural network architecture (Aytar et al., 2016), which is trained to predict content (objects and scenes) in videos while only having access to the sound information. It has been pre-trained on hundreds of gigabytes of MP3 files, and therefore offers a robust representation of auditory features. The most appropriate sound is then chosen based on the Kullback-Leibler (KL) divergence between the image network predictions and the SoundNet predictions.
All models have been expressed in the PyTorch framework, enabling seamless integration with Python workflows.
Additional features
Aside from the basic functionality mentioned above, we support two modes of generating sounds: one that searches a fixed database of superimposed sounds, and one that creates a custom superimposed sound, dependent on how similar each basic sound is to the input image. Furthermore, the user may choose to disable either the object or scene features (depending on the sort of focus desired when making decisions).
Finally, keen users can find sufficient code in our repository to construct their own databases (of not necessarily ambient sounds!).
Further ideas and feedback are, of course, very welcome! Own your surroundings.
License
MIT









Log in or sign up for Devpost to join the conversation.