
An AWS Deeplens Challenge Submission to Measure a Viewer's Facial Reaction to Funny Media
The Goal
The main goal of the project is to replace the "focus group" movie studios would have to perform when a new comedy movie comes out. Instead of having a small group of people from a mall in Iowa determining if a movie is subjectively funny, our goal is to use the Deeplens to look at viewers' reactions and simply measure their smiles and laughs more quantitatively using Deeplens. Also, by automating the process of gauging a viewer's reaction while watching media, we can allow many more subjects to participate since we aren't limited to human facilitators to run the experiment.
To achieve this we need a project that will identify users in the Deeplens view as they screen a movie, and a model which will detect their reaction. Our Deeplens project will detect faces in a frame and use a Convolutional Neural Network to determine if they are smiling in a particular frame. These results can then be sent up using IoT to aggregate data about their reaction to viewing a movie.
All that would be required of a subject is to have a Deeplens viewing their reaction while the subject herself is watching the movie the studio is trying to put in front of a test audience.
Since there is no pre-made models of facial expressions (we could find) we need to train out own model using AWS Services.
Training Set Creation
Before we can train a model to check for smiles, we need a dataset. Using the Labelled Faces in the Wild dataset, we have 13,000 faces in various states of expression.
However, we need these images labelled to have a "smile" or not and since we didn't really have time to manually check these we decided to make use of Amazon Rekognition to label the images for us.
While this means our model's accuracy will have an upper bound of Rekognition's accuracy, we have great faith in the Amazon AI team's work.
Using Rekognition, we get a payload of each of the 13,000 images which look like:
{
"Smile": {
"Value": false,
"Confidence": 93.7759780883789
},
"Emotions": [
{
"Type": "HAPPY",
"Confidence": 91.7003402709961
},
{
"Type": "CALM",
"Confidence": 12.208562850952148
},
{
"Type": "SAD",
"Confidence": 9.688287734985352
}
]
}
While eventually we'd like to make use of other emotions for other ranges of film work, for now we're just focused on smiling and laughing for comedies. The Deeplens networks were not about to handle more than one output up until less than a week before the due date :-P.
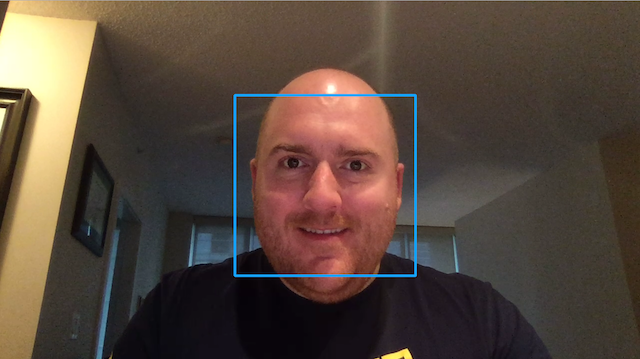
In order to focus the learning of the model on faces, we make us of OpenCV's Haar Cascades to crop the images to just the faces, as seen below:


We wrap up the 13,000 cropped images (split into training and validation sets) into rec files with all the labels we've parsed for easier training with Gluon. Though, we'll just train on smiles for now.
python im2rec.py ~/deeplens-facial-emotion/listfile-train.lst ~/deeplens-facial-emotion/cnn-face/
python im2rec.py ~/deeplens-facial-emotion/listfile-val.lst ~/deeplens-facial-emotion/cnn-face/
All this work can be seen in the dataset-creation.ipynb notebook.
The Custom Model (Smile Net)
With our 2 Rec files for training in validation, we can then train a modified AlexNet to make a Convolutional Neural Network (with the last 2 dense layers lightened to bring down model size) for training.
After 30 epochs and about an 80% accuracy rate, we can then output the model to S3 for use in our Deeplens project.
All this work can be seen in the face-detection-model-creation notebook.
The outputted models can be seen in the models folder with the smile-net prefix.
The Lambda Function
Our lambda function to run inference is based off the "face-detection" example. However, our function uses the model optimizer on load and uses the OpenCV's Haar Cascade to detect faces first instead of the model.
For each face detected using the Haar cascade, we use our optimized smile-net model to determine if the cropped face area is smiling. The model we use is our created smile-net model which we run on each individual face that is detected. For each face that is "smiling", we draw a blueish frame around the face, and for each neutral face we draw an orange frame around the discovered face.
The lambda_package folder contains the modified greengrassHelloWorld.py file, and the haarcascade_frontalface_alt.xml file.

Demo Video
AWS Deeplens Challenge - facial emotion detector
Further Work
- Obviously a better initial dataset would help training.
- More effort into the emotion model would be useful as its 80% accuracy probably isn't enough for what we'd want out system to do
- Right now we're just uploading one "face" to the IoT event. For this to work better, we'd want to individually assign faces when we get them and track them through the field of view.
Built With
- gluon
- python


Log in or sign up for Devpost to join the conversation.