-
-
Landing Page
-
Inspiration
Every RAG demo cherry-picks. Three clean questions, three polished answers, everyone claps. But the reason RAG systems fail in production isn't that they can't answer questions — it's that they can't tell you when not to trust the answer. A hallucinated citation looks identical to a real one. An out-of-date claim reads exactly like a current one. A gap — where the corpus doesn't actually cover the question — is invisible unless the system is built to surface it.
The Human Delta framework names three failure modes: gaps, conflicts, and decay. We wanted to see if we could build those directly into a user-facing interface, for one of the most fragmented knowledge domains we could think of: the deep sea. Peer-reviewed marine biology, NOAA archives, Wikipedia, press releases — the same record gets told four different ways across four different dates, and nobody agrees on the details.
What it does
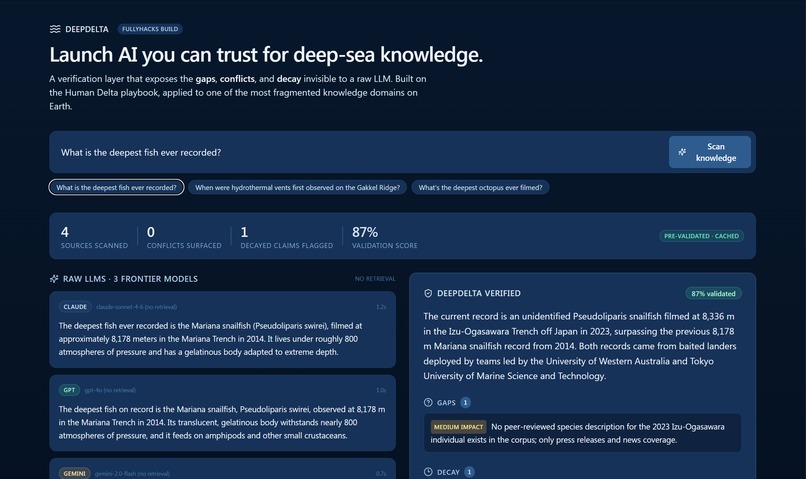
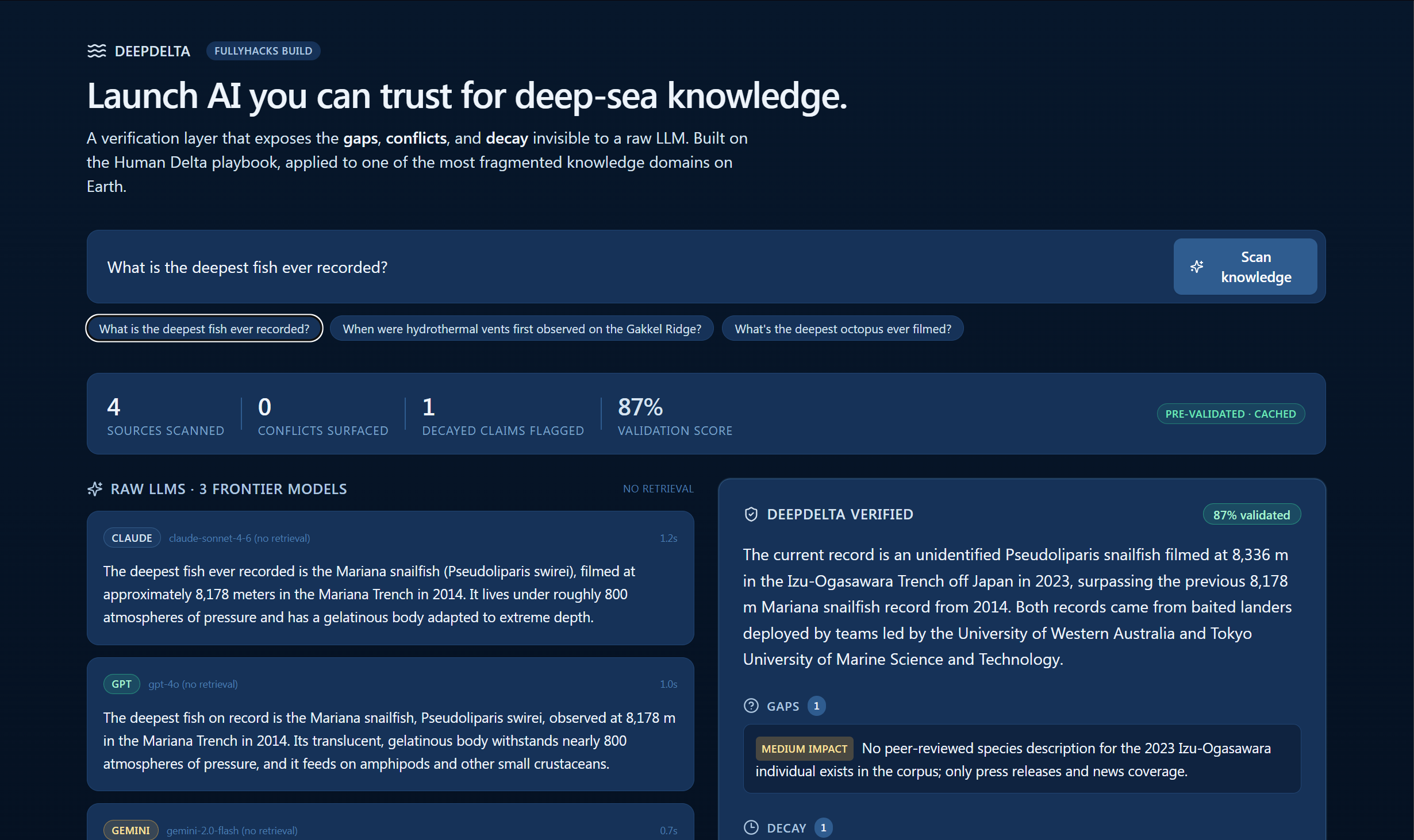
DeepDelta is a two-column comparison. You type a question. On the left, three frontier LLMs — Claude, GPT-4o, and Gemini 2.5 Flash — answer in parallel with no retrieval. That's your baseline: what you'd get from a bare LLM. On the right, DeepDelta runs the question through a Human-Delta-indexed corpus of deep-sea Wikipedia articles, grounds an answer in those sources, and scores it with a separate Claude judge.
The score is a 0–100 number with a visible breakdown: source agreement, direct evidence, recency, self-confidence. Below the score, the UI surfaces gaps (where the corpus doesn't support the answer), conflicts (where sources disagree), and decayed claims (where a more recent source supersedes an older one).
We built three demo queries that each demonstrate a different failure mode:
"What's the deepest fish ever recorded?" — the raw LLMs cite a 2014 Mariana snailfish record. DeepDelta scores it 87% and flags decay: a 2023 Izu-Ogasawara Trench observation superseded the record at 8,336 m. "When were hydrothermal vents first observed on the Gakkel Ridge?" — DeepDelta scores this 78%, with 100% source agreement but only 17% direct evidence, because most retrieved sources are cross-references rather than primary accounts. That's honest calibration. "What's the deepest octopus ever filmed?" — all three frontier LLMs confidently answer with a depth record. DeepDelta scores it 19%, with 0% source agreement and 0% direct evidence, and surfaces the gap: no source in our corpus describes octopus depth records at all. The judge refused to fabricate. That last case is the whole point. A verification layer that's unwilling to say "I don't know" isn't a verification layer.
How we built it
Retrieval uses Human Delta's filesystem directly. Rather than a vector database, we read raw Markdown files under /source/website/en.wikipedia.org/.md via hd.fs.read(). An allowlist of 23 deep-sea slugs — organisms, trenches, zones, expeditions, ecology — gates which pages flow into the pipeline. This is deliberately auditable: any judge can tree /source and see the exact corpus the model is reasoning over. No embeddings, no black box.
Fan-out hits Claude, GPT-4o, and Gemini 2.5 Flash in parallel through a single API route. Each raw call is independent — a rate-limited or down provider renders as a graceful "Unavailable" card without breaking the rest of the pipeline. We learned this the hard way when Gemini's free tier blocked us for a few hours mid-build.
Judge is a second Claude call with forced tool-use. The model must return a strict JSON schema — synthesis, gaps, conflicts, decay, and three self-reported fractions for agreement, direct evidence, and self-confidence. There's no free-form text path. This bounds the attack surface against prompt injection from the corpus and gives us a typed response we can score deterministically.
Score combines the judge's three fractions with a deterministic recency signal — per-source year regex with an 8-year decay curve — using fixed weights (40% agreement, 20% evidence, 20% recency, 20% self-confidence). Every component is visible in the UI so a reviewer can trace the score back to its inputs.
Stack: Next.js 14 App Router, TypeScript, Tailwind CSS for the UI; Anthropic SDK for Claude; direct REST calls for OpenAI and Gemini; the humandelta npm package for HD access. Deployed on Vercel.
Challenges we ran into
The Human Delta semantic search endpoint wasn't returning hits during the workshop window — our probes landed at zero every time despite the corpus being populated. Rather than block, we pivoted to reading files directly from HD's filesystem. It turned out to be a stronger architectural story: auditable by construction, and the retrieval step is now four lines of code instead of a search-result-ranking problem.
Gemini 2.0 Flash was silently deprecated for new API keys. Our prewarm script kept failing with 429s that (after truncation) hid the real error underneath — a 404 saying the model was no longer available to new users. We only caught it after building a diagnostic script (scripts/test-gemini.ts) that bypassed our abstraction and printed full HTTP responses. Upgrading to Gemini 2.5 Flash fixed it immediately.
The gap-detection demo broke when we expanded the corpus. Our original gap query was "Where do giant cucumbers live?" — a nonsense species. It scored 55% with an 8-page corpus. Then we added the Sea Cucumber Wikipedia page to round out the organism coverage, and the judge started returning 79% because it now had rich source material on a tangentially-matching species. We swapped in "What's the deepest octopus ever filmed?" — a question where the corpus genuinely has nothing relevant. That collapsed the score to 19%, which is a more honest demo of what gap detection should look like.
Deploying to Vercel surfaced the timeout cap. The verified column runs three parallel provider calls plus a judge plus retrieval, and the Hobby tier caps functions at 10 seconds. Adding export const maxDuration = 60; to the API route fixed it, but it's a real scaling consideration.
Accomplishments that we're proud of
We built the thing we promised. Every layer runs live against real APIs — retrieval, fan-out, judge, score. The UI shows the contrast between confident-wrong and calibrated-honest in a single screen. The octopus query — where three frontier LLMs agree on a fabricated answer and the verification layer lands at 19% — is the moment the project justifies itself, and it works every time.
We also kept the architecture honest. No vector database, no hidden embeddings. A judge can read the corpus with ls, read the judge prompt in one file, and audit the score calculation in 25 lines of TypeScript. Transparency was a design choice from the beginning, not a retrofit.
What we learned
Differential scoring beats absolute refusal. A system that refuses everything is useless; a system that validates everything is dangerous. The product is the variance — 87% when the corpus supports the answer with some staleness, 78% when sources are consistent but indirect, 19% when retrieval is empty. Getting all three scores to land at the right levels required tuning the judge prompt more carefully than we expected.
Retrieval transparency is the underrated property. Vector DBs hide the corpus behind embeddings. Filesystem retrieval shows you exactly what went in. For a verification system that has to convince a skeptic, the second architecture is much easier to defend.
Error truncation hides real problems. Our "catch the error, print the first 200 characters" pattern was masking the actual cause of a deprecation error. Raising it to 800 characters saved us hours. Build your diagnostic tools early.
What's next for DeepDelta
Source provenance. Every source in the retrieval should carry a visible chain of custody — when it was indexed, by whom, what hash. Human Delta's filesystem gives us the scaffolding for this.
Calibrated score weights. The four score components are currently hand-weighted (40/20/20/20). With a labeled dataset of "this answer is well-grounded" vs "this answer isn't," we could learn the weights instead of guessing them.
Streaming judge output. Claude's tool-use supports streaming, and the judge is the latency bottleneck. Progressive rendering of gaps and conflicts would cut perceived latency significantly.
Drill-down on score components. Click "67% direct evidence" and see the exact source spans the judge cited. This is a transparency win and a debugging win — if the score feels wrong, you can immediately see why.
Vertical expansion. The pipeline is domain-agnostic. Swap the allowlist in lib/humandelta.ts and the seed URLs in scripts/index-corpus.ts, and the same architecture runs over medical literature, legal opinions, or internal compliance docs. Verification-as-a-service for regulated industries is the natural next step.
Built With
- anthropic-sdk
- gemini
- human-delta
- next.js
- openai
- tailwindcss
- typescript
- vercel

Log in or sign up for Devpost to join the conversation.