-

Figure 1. ChatGPT prompt "deep sea transitioning from grayscale to vibrant colors below the waves"
-

Figure 2. DeepColor poster
-
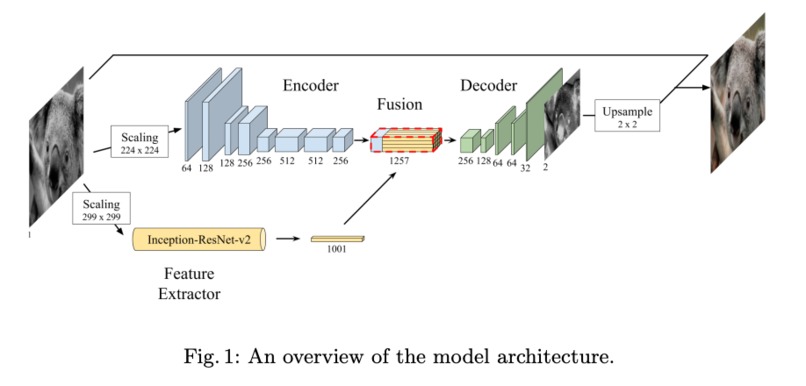
Figure 3. Original paper model architecture (from "Deep Koalarization")
-

Figure 4. The raw colored images are preserved to be a "ground truth" for our analysis. We preprocessed the images to be greyscale.
-

Figure 5: Comparison of Colorization. First two rows are U-Net, the next two are DenseNet, and the final row is MobileNet.
-
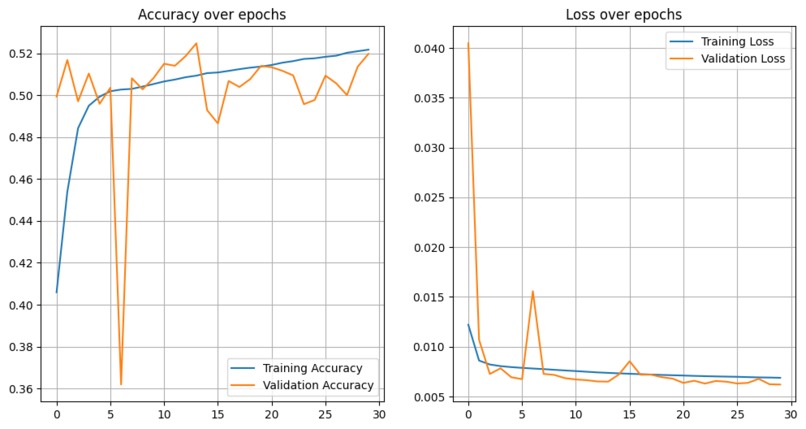
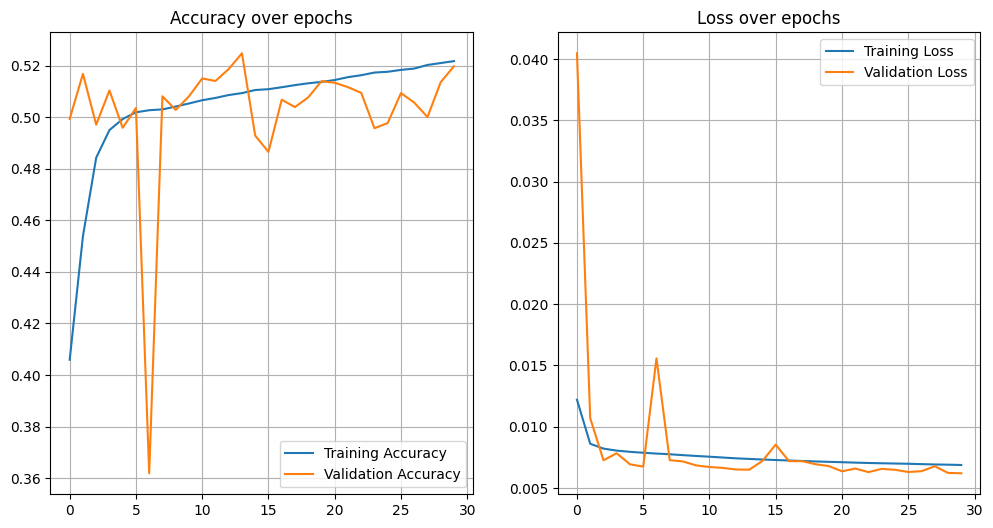
Figure 6: Example Training and Validation. U-Net accuracy and loss over 30 epochs shows rapid early improvement and stabilization.
-
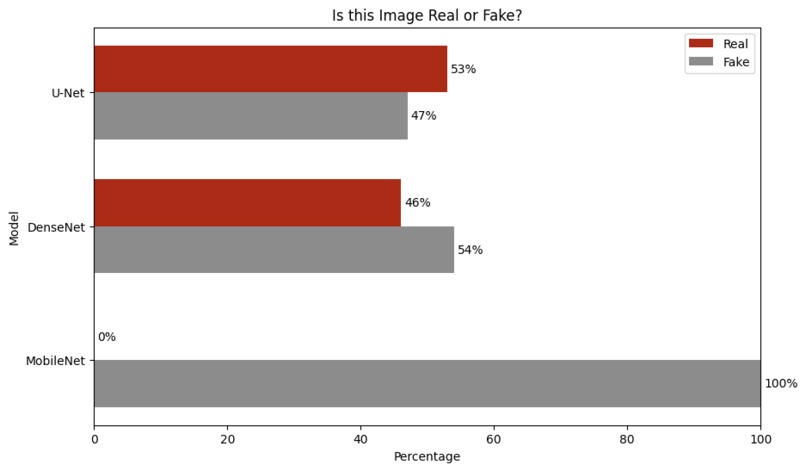
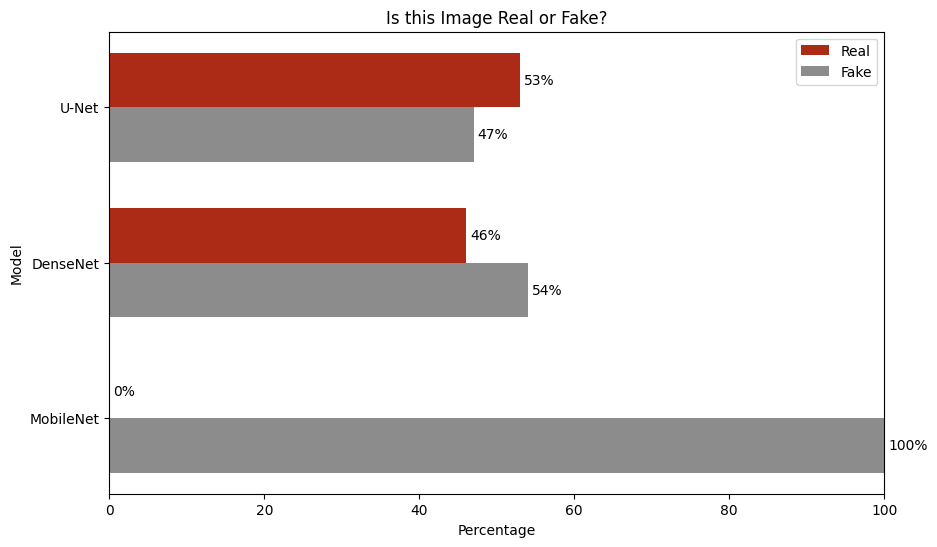
Figure 7: Public Acceptance User Study. U-Net and DenseNet were favorably viewed, MobileNet was unfavorably viewed.




DeepColor: Enhancing Image Colorization with Advanced Deep Learning Techniques
Colorize with Deep Learning: From Grayscale to Vibrant Hues!
Anna Tsvetkov (atsvetko), Samuel Walhout (swalhout), Taojie Wang (twang49)
All Deliverables:
(2) Check out our Final Write-Up!
DevPost Contents:
(1) Project Outline
(2) Check-In # 3 1 Page Reflection (at bottom of this Devpost)
Introduction
The problem we set out to solve is the colorization of grayscale images using deep learning techniques. We explored how well deep learning models, especially Convolutional Neural Networks (CNNs), can understand and replicate the complexities of color in images. We are motivated by the idea that by advancing the capabilities of deep learning models in image colorization, we can contribute to the broader “big-picture” question of how machines can understand and replicate human perception. This not only has important practical applications in fields involving the remastering of images, visual art, and surveillance, but also deepens our understanding of the perceptual processing of artificial intelligence.
We are building upon an existing paper Deep Koalarization: Image Colorization using CNNs and Inception-ResNet-v2 by Frederico Baldassarre, Diego González Marín, and Lucas Rodés-Guirao. The paper introduces a model that combines a CNN trained from scratch with high-level features that were extracted from the pre-trained Inception-ResNet-v2 model for image colorization. The use of a pre-trained model for feature extraction was particularly interesting, as it provides information about the image content that can aid in the colorization process. We chose this paper because it presents a novel approach to image colorization that we believe can be further extended and improved with advanced deep learning techniques.
The problem falls under the category of structured prediction in machine learning. More specifically, structured prediction involves the prediction of structured outputs, such as images, as opposed to scalar outputs found in regression tasks or class labels found in classification tasks. In our work, the structured output is the colorized version of a grayscale image.
Our approach, which we call DeepColor, extends the “Deep Koalarization” model by using different architectures, datasets and hyperparameters. We plan to explore architectures such as U-Net, DenseNet and MobileNet to assess the impact of different kinds of architectures on colorization accuracy. We will also conduct both quantitative ablation studies and qualitative evaluations to understand how different layers and hyperparemeters affect the colorization process. Our ultimate goal is to enhance the model’s ability to both capture and replicate the complexities of color in various images. The upshot of our project is more accurate and visually appealing colorized images, which has significant technical and ethical implications in fields ranging from image remasterization to surveillance.
Related Work and Inspiration
We are aware of the significant attention that image colorization has received both in the academic literature and popular media, which drew us to explore this topic for our project. The key paper that inspired our work, as we noted and described above, is Deep Koalarization: Image Colorization using CNNs and Inception-ResNet-v2 by Frederico Baldassarre, Diego González Marín, and Lucas Rodés-Guirao. Another influential paper was Colorful Image Colorization by Richard Zhang, Phillip Isola, and Alexei Efros. This work introduced a deep learning approach also based on a CNN model, but where the model predicts the color components of an image based on its luminance component with a novel loss function that specifically promotes vibrant and diverse colorization. The paper also demonstrated the ability of a CNN-based model to produce both realistic and visually appealing colorizations. We also reviewed Let There be Color!: Joint End-to-end Learning of Global and Local Image Priors for Automatic Image Colorization with Simultaneous Classification by Satoshi Iizuka, Edgar Simo-Serra, and Hiroshi Ishikawa. This work introduced an image colorization technique that used technical features like global priors and local image features. The authors used a deep neural network that learned to colorize an image and also to classify its semantic content which helped the model produce more accurate colorizations. Our review of the literature suggests that image colorization is a large and promising field that offers plenty of opportunities for advancements with diverse deep learning techniques.
Public Code:
Data
We have multiple ideas for the datasets we will use for our project. Importantly, these are different from the data used in the original paper we are replicating, which used a subset of the ImageNet dataset for their model, in particular 60,000 images. Due to limitations in our computing resources, processing and colorizing such a large number of images might not be feasible. Handling large datasets requires a significant amount of memory and computational power, which might exceed the capacity of our available hardware. To address this, we will experiment with different batch sizes of images (e.g. 100, 200, 500, 1000 and perhaps even greater) to find a balance between computational efficiency and the performance of our model.
First, we will experiment with using a subset of the COCO Dataset (Common Objects in Context). We chose this dataset because it provides a diverse range of images with different scenes and objects which will help our model learn to colorize a wide range of subjects and scenarios. The COCO dataset contains over 200,000 labeled images, including complex scenes with multiple objects. We will select a representative subset that captures this diversity. The dataset is available here.
Second, we plan to use a subset of the Places365 Dataset. This dataset is specifically designed for scene recognition and has over 2.5 million images covering more than 205 unique scene categories. By including Places365 in our training data, we aim to enhance our model's ability to colorize various environments, such as natural landscapes to urban settings. We believe that this will complement the object-centric focus of the COCO dataset and provide a more comprehensive learning experience for our model. The dataset can be accessed here.
Third, we plan to use a subset of the ADE20K dataset which contains more than 20,000 images annotated with objects and object parts. This dataset will provide our model with the opportunity to learn the colorization of both objects and their parts in detail, which is important for achieving realistic colorization results. The dataset can be found here.
We will need to preprocess the data for each dataset in four main steps:
Grayscale Conversion: We will convert the color images to grayscale to create the input for our colorization model. This step is important as our model aims to learn how to add color to grayscale images. It's also important to note that we chose to use colored datasets (and not grayscale datasets) to retain the original color images as the "ground truth" for training and evaluating our model. This allows us to compare the colorized output of our model to the original color images and calculate metrics such as Mean Squared Error (MSE) or Peak Signal-to-Noise Ratio (PSNR) to assess the colorization accuracy.
Resizing Images from the Datasets: We will resize the images to a uniform size (e.g., 256x256 pixels) to ensure consistency across the datasets and reduce computational load during training. The choice of size may depend on the computational resources that we have available and the desired level of detail in the colorized images that we select. Uniform sizing across our datasets is also important for batch processing in neural networks.
Normalization: We will normalize the pixel values to a range that is suitable for the input to our network, like [-1, 1]. This will help with our training process and will improve convergence. This will help us make sure that all input features (pixel values in our case) are treated equally by the model.
Data Augmentation for Variety: Finally, we will apply data augmentation techniques such as rotation and flipping to increase the diversity of the training data and, therefore, improve the robustness of our model. The hope is that this will help our model generalize to unseen data by simulating variations that might occur in real-world scenarios (e.g. objects getting rotated, flipped over, etc.).
We believe that these three datasets will give our model a really comprehensive exposure to a variety of subjects, including objects, people, scenes, and their components.
Methodology
The original paper proposed a model that combines a deep Convolutional Neural Network (CNN) trained from scratch with high-level features extracted from the pre-trained Inception-ResNet-v2 model. Their architecture includes an encoder-decoder structure with a fusion layer that integrates the features from the Inception-ResNet-v2 model. This fusion layer basically makes sure that the semantic information provided by the Inception-ResNet-v2 model is distributed across the spatial regions of the image, which helps the decoder in generating a more accurate and detailed colorization. Please see below for Figure 3 in Project Media for an illustration of their model architecture.
We plan to experiment with the following architectures, and include our justifications for each one below:
U-Net: According to our research, U-Net is well known for how effective it is in image segmentation tasks which can help us retain important spatial information and reconstruct the detailed color in the images well. We hypothesize that U-Net's ability to capture both local and global features might be beneficial for image colorization.
DenseNet: DenseNet has dense connections between layers, which can enhance feature propagation and reduce the number of parameters in our model. We believe that DenseNet's architecture could provide a good balance between the complexity of our model and its colorization quality.
MobileNet: MobileNet seems to focus on reducing computational cost while maintaining accuracy, which is good for our work given our limited computational resources. We plan to experiment with MobileNet to explore the trade-off between model size and colorization performance.
The original paper trained their model using Adam optimizer and with a learning rate of 0.001, and they also used MSE as their objective loss function. They had a fixed input image size and a batch size of 100. Their training process involved minimizing the MSE between the estimated pixel colors in the color space and their real-world values. For our models (U-Net, DenseNet, and MobileNet) we will train these models using a similar approach to the original paper, with the objective function being the Mean Squared Error (MSE) between the estimated colors of the pixels and their real-world values. We will use the Adam optimizer and experiment with different learning rates and batch sizes to optimize the training process.
One of the hardest parts of implementing these models might be for us to achieve a balance between the complexity of our model and our colorization quality. We found that each architecture has its own strengths and weaknesses, and finding the right configuration for our specific colorization task is challenging. Additionally, the specific aspect of the original paper of integrating high-level features from pre-trained models like Inception-ResNet-v2, as done in the original paper, might require careful design to ensure that these features effectively contribute to the colorization process and we would need to figure out the extent to which we could implement this part of the paper with our architecture if we run into issues.
In case we run into issues, as backup ideas, we are considering experimenting with variations of the architectures mentioned above, such as exploring different depth and growth rates in DenseNet and similarly playing around with the others. We could also investigate the use of other pre-trained models for feature extraction or explore different loss functions that might better help us with our colorization task.
Metrics
Success, in our project, is constituted by the accuracy of colorization by our model. This will be primarily measured through quantitative and qualitative experiments that we will run. In addition to accuracy, we will also consider the visual appeal and the naturalness of the colorized images as a metric for success since our ultimate goal is to produce images that are not only accurate but also aesthetically pleasing to perceivers.
The authors of the paper we are implementing hoped to find a novel approach to colorizing grayscale images using deep learning techniques. They aimed to show that a model that combined a CNN with high-level feature extraction from the Inception-ResNet-v2-pre-trained model could accurately colorize images. They primarily quantified their results through qualitative assessments. For their quantitative assessments, they mentioned using Mean Squared Error (MSE) as the objective function during training but did not provide explicit MSE values as a measure of colorization accuracy in the results section. Instead, they conducted a user study to assess the “public acceptance” of the colorized images, where participants were asked to judge whether the colorized images looked real or not. In the paper, "public acceptance" refers to the percentage of participants in a user study who mistakenly identified colorized images as real color images. A higher rate of public acceptance indicates that the colorized images are more convincing and indistinguishable from true color images to human observers. This qualitative approach allowed them to gauge both the perceived realism of their model's output and its visual appeal, which is what we are also trying to achieve. In our work, we will use both qualitative and quantitative assessments, including a user study (in MTurk) as well as quantitative assessments like Mean Squared Error (MSE) or Peak Signal-to-Noise Ratio (PSNR) between the colorized and original images.
We plan to run experiments to explore different architectures such as U-Net, DenseNet and MobileNet and to experiment with different layers and hyperparamters. Unlike the original authors, we will conduct quantitative ablation studies to understand the impact of different components of the model on colorization accuracy. We will also use qualitative experiments to assess the visual quality of the colorized images.
Our base goal is to approximate the performance of the original paper in terms of colorization quality. We will aim for a similar rate of "public acceptance" in a user study (in MTurk), which was reported to be 45.87% in the original paper, and use additional metrics such as Mean Squared Error (MSE) or Peak Signal-to-Noise Ratio (PSNR) between the colorized and original images, even though the original paper did not provide explicit quantitative metrics. Our target goal is to improve upon our quantitative and qualitative assessments by experimenting with different architectures and hyperparameters. This could involve achieving higher "public acceptance" rates in a user study (e.g., exceeding 45.87%) or better scores on quantitative metrics like MSE or PSNR. Our stretch goal is to achieve state-of-the-art colorization accuracy that potentially surpasses the model in the original paper as well as other existing models in the field of colorization. This would involve significantly higher "public acceptance" rates and superior quantitative metric scores, indicating that our model can produce highly realistic and accurate colorizations.
Ethics
Ethics plays a large role in the application of colorization technology. The ethics of colorization finds its historical roots in the early attempts to add color to black and white images. The ethical considerations of colorization have evolved since then, particularly when it comes to representing marginalized communities and historical events. Before the advent of deep learning techniques, colorization was extremely expensive and impractical on a large scale making it available only to those with certain financial resources and commercial interests. Deep learning-based colorization democratizes access to colorization technology, which enables communities to share their pictorial history in full color no matter the resources that they have. This can be a powerful tool for storytelling and preserving cultural heritage, as seen in Peter Jackson’s They Shall Not Grow Old, where early computerized colorization techniques were used to bring World War I footage to life. As deep learning colorization becomes more affordable and more accessible, it enables a wider range of stories to be shared, extending beyond those backed by the financial resources and commercial agendas of major production companies.
However, the ethical implications of colorization must be carefully considered. As highlighted by Justin Olah and Jenny Yang, in Let There Be Color!: Deep Learning Image Colorization, colorization can potentially go against the original artist’s intention and the historical context of the original work. There are images, for example, whose subjects or original creators may not wish to be colorized or simply have not consented for the images to be colorized, especially in the case of the remastering of historical images where the subjects and artists are no longer alive to give their consent. Colorizing an image without their explicit consent raises a number of ethical issues concerning respect for the intentions of creators of art, the dignity and privacy of artistic subjects, and the potential distortion of historical and cultural accuracy. Colorizing such images without careful consideration can therefore lead to a misrepresentation of the past and a lack of respect for the individuals and contexts depicted. It is therefore important to approach colorization with sensitivity and a deep and nuanced understanding of the ethical implications involved with the powerful technique.
Moreover, in the realm of surveillance, the ethical considerations of deep learning colorization become even more pronounced. While colorization can enhance the clarity and also the usefulness of surveillance footage, it also raises significant ethical concerns about privacy. The ability to add color to grayscale surveillance images could potentially be used to identify individuals and to reveal details that were not originally visible. In addition, the application of colorization in surveillance needs to be carefully regulated to prevent misuse. There is a risk that colorized surveillance footage can be misinterpreted or even manipulated in certain ways, leading to false accusations and judgements that raise serious concerns within the realm of criminal justice. We therefore believe it is important to establish ethical guidelines and to ensure transparency in the use of colorization in technology to protect the rights and privacy of individuals.
So, while we believe that deep learning colorization offers valuable benefits in terms of storytelling and artistic visual enhancement, its application requires careful ethical consideration to prevent misuse, preserve historical accuracy, and protect individual rights concerning consent and privacy.
Division of Labor
Here is our division of labor, with the tasks that will be led and conducted by each team member.
Anna Tsvetkov (atsvetko):
- [ x ] Lead the downloading and preprocessing (including greyscale conversion, resizing, normalization and data augmentation) of the Coco Dataset
- [ x ] Lead the development and implementation of the Mobile-Net architecture
- [ x ] Handle the training process of the Mobile-Net model, including setting up the Adam optimizer, and ideal learning rates, and batch sizes
- [ x ] Final evaluation of the Mobile-Net model and determining our model’s success based on quantitative and qualitative metrics
Samuel Walhout (swalhout):
- [ x ] Lead the downloading and preprocessing (including greyscale conversion, resizing, normalization and data augmentation) of the Places2 Dataset
- [ x ] Lead the development and implementation of the U-Net architecture
- [ x ] Handle the training process of the U-Net model, including setting up the Adam optimizer, and ideal learning rates, and batch sizes
- [ x ] Final evaluation of the U-Net model and determining our model’s success based on quantitative and qualitative metrics
Taojie Wang (twang49):
- [ x ] Lead the downloading and preprocessing (including greyscale conversion, resizing, normalization and data augmentation) of the ADE20k Dataset
- [ x ] Lead the development and implementation of the Dense-Net architecture
- [ x ] Handle the training process of the Dense-Net model, including setting up the Adam optimizer, and ideal learning rates, and batch sizes
- [ x ] Analyze the results of the experiments and compare them with the baseline model from the original paper
- [ x ] Final evaluation of the Dense-Net model and determining our model’s success based on quantitative and qualitative metrics
And all of us will collaborate on the following tasks:
- [ x ] Selection of the datasets (COCO, Places2, ADE20K)
- [ x ] Review and discussion of related work in the field of image colorization
- [ x ] Conduct quantitative ablation studies to assess the impact of different model components on colorization accuracy
- [ x ] Coordinate the user study (with peers) for qualitative assessment and the public acceptance evaluation
- [ x ] Writing and editing the final report and putting all the presentation materials together
Reflection
April 24
Introduction
The problem we are trying to solve is the colorization of grayscale images using deep learning techniques. We explore how well deep learning models, especially Convolutional Neural Networks (CNNs), can understand and replicate the complexities of color in images. We are motivated by the idea that by advancing the capabilities of deep learning models in image colorization, we can contribute to the broader “big-picture” question of how machines can understand and replicate human perception. This not only has important practical applications in fields involving the remastering of images, visual art, and surveillance, but also deepens our understanding of the intersection between artificial intelligence and human perception.
We are building upon an existing paper Deep Koalarization: Image Colorization using CNNs and Inception-ResNet-v2 by Frederico Baldassarre, Diego González Marín, and Lucas Rodés-Guirao. The paper introduces a model that combines a CNN trained from scratch with high-level features that were extracted from the pre-trained Inception-ResNet-v2 model for image colorization. The use of a pre-trained model for feature extraction was particularly interesting, as it provides information about the image content that can aid in the colorization process. We chose this paper because it presents a novel approach to image colorization that we believe can be further extended and improved with advanced deep learning techniques.
The problem falls under the category of structured prediction in machine learning. More specifically, structured prediction involves the prediction of structured outputs, such as images, as opposed to scalar outputs found in regression tasks or class labels found in classification tasks. In our work, the structured output is the colorized version of a grayscale image.
Our approach, which we call DeepColor, extends the “Deep Koalarization” model by using different architectures, datasets and hyperparameters. We plan to explore architectures such as U-Net, DenseNet and MobileNet to assess the impact of different kinds of architectures on colorization accuracy. We will also conduct both quantitative ablation studies and qualitative evaluations to understand how different layers and hyperparemeters affect the colorization process. Our ultimate goal is to enhance the model’s ability to both capture and replicate the complexities of color in various images. The upshot of our project is more accurate and visually appealing colorized images, which has significant technical and ethical implications in fields ranging from image remasterization to surveillance.
Challenges
What has been the hardest part of the project you’ve encountered so far?
The most challenging aspect of our project has been dealing with the architectural complexities of the three models we are implementing. In particular, the upsampling processes required to match the output image size with the input dimensions was challenging. To work through this, we experimented with different configurations of upsampling layers. This process required extensive testing and validation to ensure that the network architecture was configured correctly to upscale without losing detail.
Additionally, managing the huge sizes of our chosen datasets and making subsets for training proved to be challenging due to our limited computational resources. We worked through this by using really efficient data management libraries and platforms. Specifically, we leveraged TensorFlow datasets and Hugging Face's datasets library for the Places and ADE20k datasets, which provide streamlined access to subsets of the datasets, which really reduced our load time and memory overhead. For the Coco database, we used the FiftyOne library, which is particularly useful for visualizing and filtering the large dataset efficiently. These tools allowed us to handle large volumes of data more effectively, enabling us to focus on model training and optimization without being hindered by our hardware limitations.
Another challenge has been the loss of our fourth group member. When we originally proposed this project, we were expecting to have an additional member to help share the workload. Since we have not chosen to pare down the scope of our project, it has resulted in additional responsibilities for each group member.
Insights
Are there any concrete results you can show at this point?
Yes. Our preprocessing pipeline is fully functional, as demonstrated in Figure 4 above, where we show the transformation of raw images into their greyscaled, resized counterparts. This groundwork allows us to proceed with confidence into the training phase and also to have a "ground truth" colorization available for later analysis. Our initial model configurations and layer setups for each model are also illustrated in our Github repo and are promising and indicate that the models are functioning as intended.
How is your model performing compared with expectations?
Our models are performing beyond our initial expectations. We've been happily surprised by the preliminary results, which suggest that our modifications and architectural choices are functional and may potentially offer improvements over the foundational "Deep Koalarization" model.
Plan
Are you on track with your project?
Yes. We are on track with our project timeline. The immediate next steps involve just finishing up the last bits of the training of our models across all three datasets and doing our comprehensive qualitative (user study) and quantitative (MSE and PSNR) analyses. Each team member has clear tasks and plans aligned with these objectives, ensuring efficient progress toward our final goal which are outlined above under Division of Labor above. We are all on the same page about using peers for our qualitative study and showing them the respective images and implementing MSE and PSNR.
What do you need to dedicate more time to?
As we move closer to completing DeepColor, we would like to dedicate more time to the evaluation phase, particularly in analyzing the outcomes of our models in depth. Specifically, more time is required for setting up and refining our evaluation metrics, such as Mean Squared Error (MSE) and Peak Signal-to-Noise Ratio (PSNR), and for conducting a thorough user study to assess the public acceptance of our colorized images. After talking with our TA, and due to financial constraints, we decided to opt to do an "informal" user study with colleagues instead of an official (and paid) user study in MTurk so will be devoting time to finding participants.
What are you thinking of changing, if anything?
Given our current success, we plan to adjust our approach to experiment with larger image sample sizes, to test the absolute limits of what our computational resources can handle. This adjustment is easily implemented (one line changes) thanks to the flexible nature of our code. Additionally, as we mentioned above, we've decided to modify our initial user study approach. Instead of using MTurk, which incurs costs, we will conduct our qualitative assessments with our peers, which provides a more accessible and financially feasible method for gathering necessary data.

Log in or sign up for Devpost to join the conversation.