-

Final Presentation
-
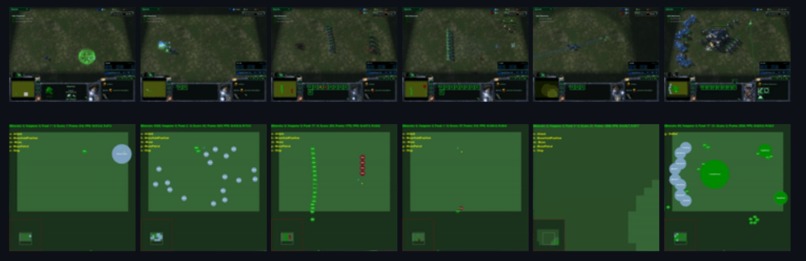
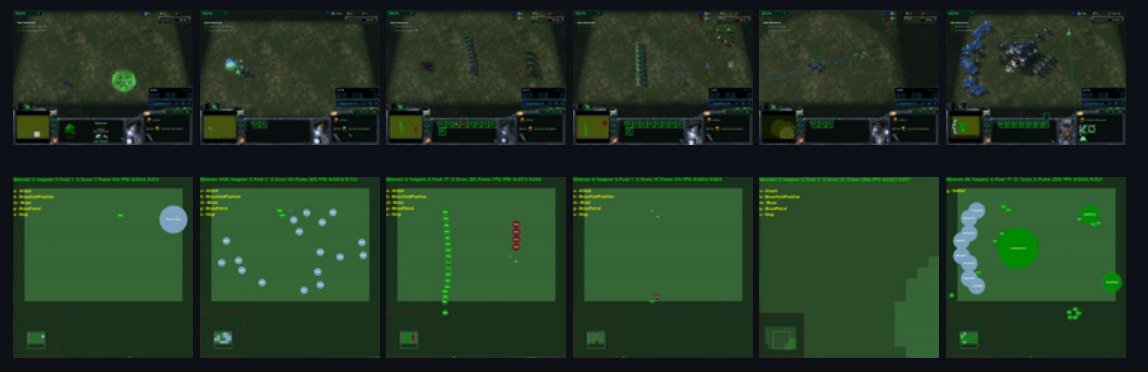
Top images represent the actual game. Bottom images represent a simplified version of the actual game to allow faster training.

Checkpoint 2 link
Final Writeup link
Video Presentation link
Presentation link
Introduction
StarCraft II is a real-time strategy video game where two players fight against each other to win the game by destroying each other’s infrastructure. StarCraft II can be seen as a game that requires higher level strategic planning (often called macromangement or “macro” for short) and lower level planning and controls (often called micromanagement or “micro” for short). With DeepMind’s Python component of the StarCraft II Learning Environment (SC2LE), individual “micro”-level tasks that one can expect to see in a full match of StarCraft II are available as separate simulations to test the capabilities of artificial intelligence agents.
Both of us have been avid players of the game in the past and have a very deep understanding of the game. This naturally led us to question how deep learning and reinforcement learning can be applied to the game and evaluate the performance of our models, given our knowledge of the game.
The SC2LE’s simulations model the tasks we want to solve as a Markov decision process which leads us to solve these tasks with reinforcement learning. We will combine our knowledge of deep learning from this course and our background in reinforcement learning to create deep reinforcement learning models to solve the tasks.
Related Work
The most complex and well-known work in StarCraft II AI is the AlphaStar from DeepMind (which is rumored to be still playing on the game servers against unfortunate human players that were matched with AlphaStar). While AlphaStar plays full matches of StarCraft II instead of simulation tasks and is beyond the scope of this project, we will discuss major components that DeepMind used to build AlphaStar that can guide us towards creating our own model. AlphaStar’s model is a multi-agent reinforcement learning algorithm that utilizes both transformers and LSTM to deal with the large action space of the game and long-term sequence modelling. A full match of the game requires deciding between a large range of actions which includes actions such as choosing buildings to construct, army units to build, where to move existing army units, and so on. Unfortunately, DeepMind does not release implementation details.
The most popular implementations of SC2LE are Reaver and another from Autonomous Systems Labs. These two implementations are based off of research by DeepMind and Blizzard which used FCCN and FCCN + LSTM. Main contributions of both Reaver and ASL are the implementations of A2C and PPO with FCCN (Fully Convolutional Neural Network) because the original paper does not release implementation details. Another main contribution from Reaver is the optimized training framework for those with access to no more than one computer. Reaver can speed up training from a single machine up to 1.5 times. FCCN is believed to be used to maintain the spatial information all the way up until the output, which is the action of the agent. Because the two most popular implementations use FCCN, we can take away with the knowledge that the importance of spatial information from each frame of the game must be regarded highly within the community.
Data
The data will be collected by running simulations of the game, and each data point will be an image frame. However, the image frame won’t be exactly the same as the simulation itself. SC2LE has an option to output a simplified version of the image frame.
Methodology
While our tasks will not require such a large range of actions as AlphaStar, we wish to utilize transformers and RNNs to test their respective performance. The SC2LE research and the community has worked with CNNs and FCNNs, but the use of transformers or RNNs (basic RNN, GRU, and LSTM) has not been done within the community of SC2LE.
We wish to create two types of models. Our first model will combine a fully convolutional neural network with transformers and RNNs for long term sequence modeling. We also want to test the performance of transformers and how well they can learn to solve MDP tasks.
We believe that RNNs and transformers have great potential in outperforming the current best models of FCNN. This is due to the fact that image frames will come in ordered sequences that RNNs and transformers can make best use of. By taking advantage of the extra information gained from the image sequences, our model can hypothetically make better decisions at each action step.
The model will be trained as the simulation repeats through a number of episodes. Through this method, we will check whether the agent is converging to an optimal policy. We believe our work can bring great contribution to the community by providing and analyzing the performance of RNN and transformer models and comparing them to the existing FCNN models.
Backup idea we have is to implement different types of deep learning models as a referenceable baseline for SC2LE and other reinforcement learning testbeds. By building custom models of different architecture we have learned throughout the course, from the basic models to those that combine different types of architecture, we plan to provide experiments that showcase pros and cons of different models.
Methodology: Metrics
Because there are existing implementations to solve SC2LE tasks, we will compare our results with results of other models. For example, Reaver model has the number of seconds the model took to solve each task. We may compare our model in regards to time (seconds) to determine the success of our model.
Determining success is difficult for our project. While each task has a clear success and failure state, we hope to go beyond this and create a model that can perform as well as other implementations or better. Our first step will be to train the model to successfully solve each task in a reasonable amount of time (minute or two). Afterwards, we will focus on improving the performance up to or better than other implementations.
Methodology: Ethics
The problems we are tackling have a large state space. This is because the number of possible interactions between different agents increases exponentially with respect to the number of agents and the position of an agent is in a continuous space. Therefore, any classical planning method would be unfeasible given the large number of states and the stochasticity of the environment. Also, supervised learning would require too many manually run pre-computed simulations with labeling. Since the agents react to each other in real time, reinforcement learning would be the best fit.
Starcraft II is a real-time simulation of wars with many high-level conceptual factors, such as economy, base expansion, army positioning, attention distraction, and more. Therefore, many real world war strategies can be applied in the video game and vice versa. Our research and the related works can potentially showcase the power of deep learning in real world wars. Once the real world agents are modeled in such video game environments, deep learning could potentially provide guidelines for military strategies when making strategically difficult decisions or providing accurate outcomes of the decisions that they plan to make.
Methodology: Division of Labor
For the first part of the project, we will work on creating the model together. We will review other research results to formulate ideas for the model and create data using simulations. For the second part of the project, we will train and test our model separately and have regular meetings to discuss possible adjustments. For the last part of the project, we will create a visual poster and practice live presentation together.



Log in or sign up for Devpost to join the conversation.