-

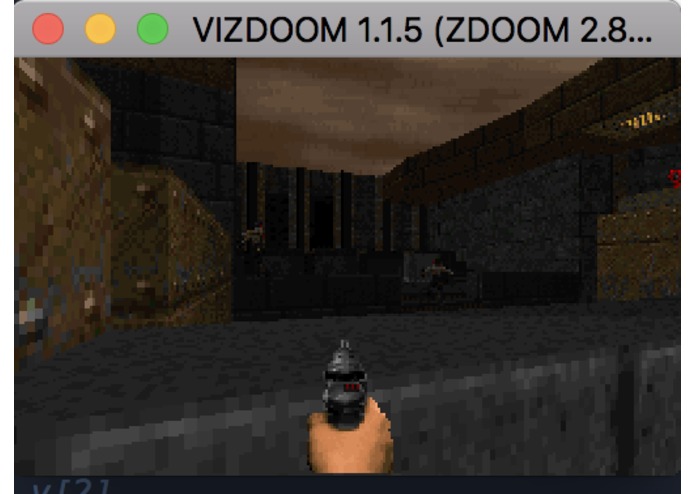
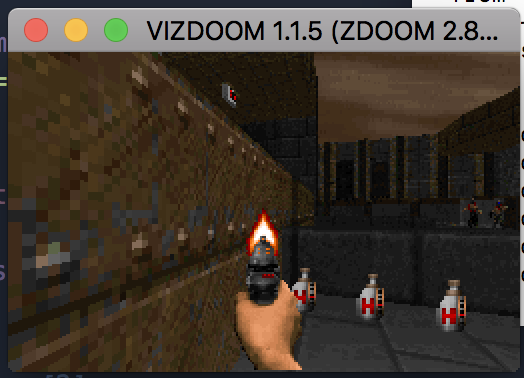
The Deep Recurrent Q-Network attempts to shoot an enemy during the testing phase.
-
The Deep Recurrent Q-Network takes cover from hostiles in the environment.
-
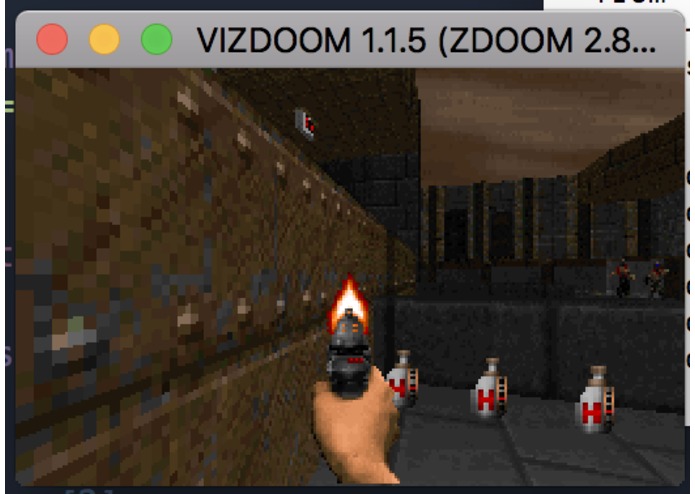
The Deep Recurrent Q-Network experiences difficulty in navigating the environment.
-
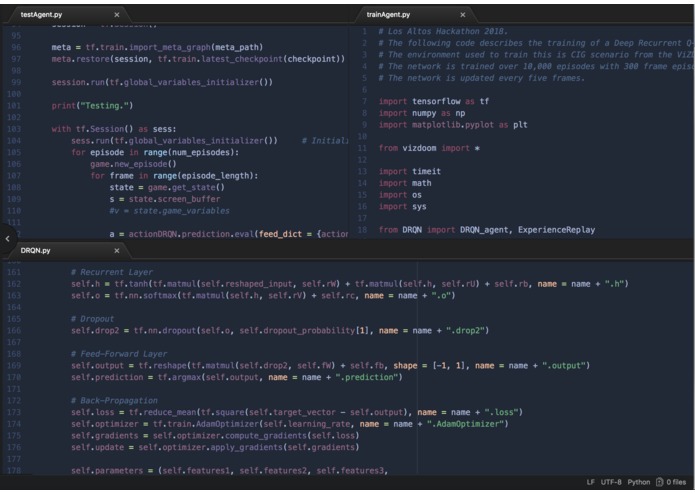
A small portion of the three python files used to create the Deep Recurrent Q-Network with a combined total of 534 lines of code.


Inspiration:
I was inspired to create this project because of my love of video games as well as my growing interest in machine learning and neural networks. I was also inspired to create this project because I attempted to create a different Deep Recurrent Q-Network in early 2018 to perform in Doom scenarios but failed dramatically, and thus wanted to remedy my mistakes.
What it does:
The Deep Recurrent Q-Network, through 3,000,000 frames of trial and error, attempts to learn the best mappings between frame information from the first-person-shooter game _ Doom _ and the optimal actions to take to maximize a preset goal, in this case, killing the maximum number of enemies. In other words, this project was created to train the Deep Recurrent Q-Network to effectively play _ Doom _. The Deep Recurrent Q-Network takes individual frames from the ViZDoom API and convolves them through three convolutional layers. Next, the convolved inputs are sent to a recurrent layer followed by a feed-forward layer to create a vector of q-values. The network then chooses the maximum q-value and uses the action associated with it to modify its environment. It then receives a reward value from the environment which the network uses to adjust its internal parameters, increasing the chance that its future predicted actions will be optimal.
How I built it:
The code for the network was written in Python v3.6.4 as well as using the tensor library Tensorflow v1.6.0. The network was trained for 10,000 episodes, each episode constituting the completion of 300 frames or the total number of frames until the network dies in the environment. Training of the network finished after 9.43 hours on 2.9 GHz Intel Core i5 CPU.
Challenges I ran into:
I found a surprisingly low amount of bugs in my network and the training of the network ran smoothly. However, the network gained no reward across all 3,000,000 frames of training and the loss values seemed to center around 0.0 across the entirety of training and, the fact that the loss values did not smoothly converge to a plateau around 0.0, is usually a sign of an underfit network.
Accomplishments that I'm proud of:
I am proud of the fact that I was able to fix problems found in my first iteration of Deep Recurrent Q-Networks in Doom scenarios, as the network in my first attempt was unable to move around in its environment. I am also impressed with my ability to create a deep neural network in a relatively short time span, even though it was eventually unsuccessful.
What I learned:
I learned about the importance of time-management in the creation of deep learning algorithms. If I was aware of the large time commitment towards training a Deep Recurrent Q-Network, I would have attempted a simpler project. By training a network with a variable level of success, as I was uncertain if the network would perform efficiently and, by training it across an approximately 10 hour period, the success of my entire project was dependent on whether my network would produce acceptable results as, if it hadn't, I would have no time to add any improvements to my network (creation of the network was about 6 hours, training was about 10 hours, for a combined total of 16 hours out of the approximately 24-hour period).
What's next for Deep Recurrent Q-Networks in Doom Environments:
In the future, I seek to improve the loss and optimization algorithms for my Deep Recurrent Q-Network, as I believe these are the factors responsible for the awful performance of my network.
Built With
- python
- tensorflow
- vizdoom

Log in or sign up for Devpost to join the conversation.