-
-
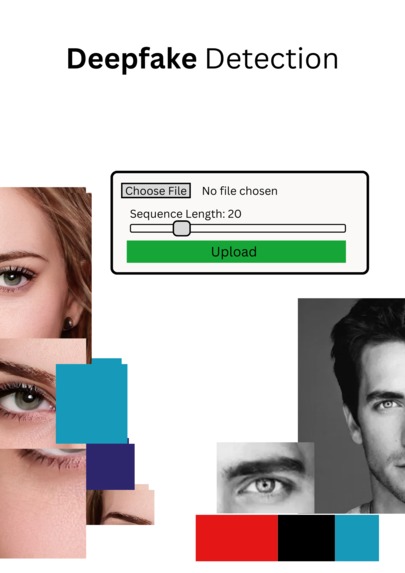
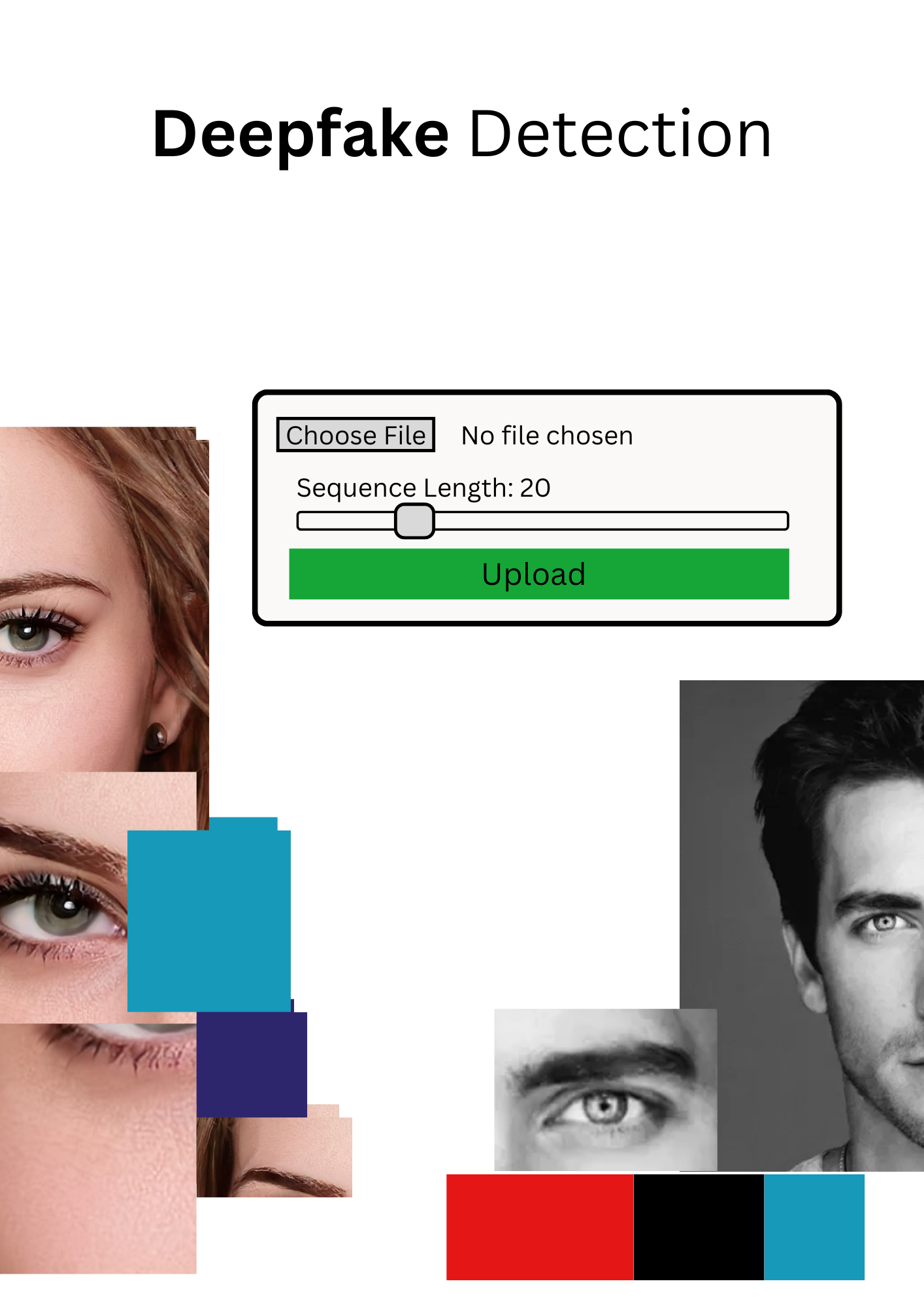
this is the UI of my Project
Inspiration
In the world of ever growing Social media platforms, Deep fakes are considered as the major threat of the AI. There are many Scenarios where these realistic face swapped deep fakes are used to create political distress, fake terrorism events, revenge porn, blackmail peoples are easily envisioned. Some of the examples are Brad Pitt, Angelina Jolie nude videos It becomes very important to spot the difference between the deepfake and pristine video. We are using AI to fight AI.Deepfakes are created using tools like FaceApp[11] and Face Swap [12], which using pre-trained neural networks like GAN or Auto encoders for these deepfakes creation. Our method uses a LSTM based artificial neural network to process the sequential temporal analysis of the video frames and pre-trained Res-Next CNN to extract the frame level features. ResNext Convolution neural network extracts the frame-level features and these features are further used to train the Long Short Term Memory based artificial Recurrent Neural Network to classify the video as Deepfake or real. To emulate the real time scenarios and make the model perform better on real time data, we trained our method with large amount of balanced and combination of various available dataset like FaceForensic++[1], Deepfake detection challenge[2], and Celeb-DF[3].
Motivation of our project:
The increasing sophistication of mobile camera technology and the evergrowing reach of social media and media sharing portals have made the creation and propagation of digital videos more convenient than ever before. Deep learning has given rise to technologies that would have been thought impossible only a handful of years ago. Modern generative models are one example of these, capable of synthesizing hyper realistic images, speech, music, and even video. These models have found use in a wide variety of applications, including making the world more accessible through text-to-speech, and helping generate training data for medical imaging. Like any trans-formative technology, this has created new challenges. So-called "deep fakes" produced by deep generative models that can manipulate video and audio clips. Since their first appearance in late 2017, many open-source deep fake generation methods and tools have emerged now, leading to a growing number of synthesized media clips. While many are likely intended to be humorous, others could be harmful to individuals and society. Until recently, the number of fake videos and their degrees of realism has been increasing due to availability of the editing tools, the high demand on domain expertise.
Goals and objectives of our project:
Goal and Objectives: • Our project aims at discovering the distorted truth of the deep fakes. • Our project will reduce the Abuses’ and misleading of the common people on the world wide web. • Our project will distinguish and classify the video as deepfake or pristine. • Provide a easy to use system for used to upload the video and distinguish whether the video is real or fake.
Methodologies of Problem solving:
- Analysis:
• Solution Requirement We analysed the problem statement and found the feasibility of the solution of the problem. We read different research paper as mentioned in 3.3. After checking the feasibility of the problem statement. The next step is the dataset gathering and analysis. We analysed the data set in different approach of training like negatively or positively trained i.e training the model with only fake or real video’s but found that it may lead to addition of extra bias in the model leading to inaccurate predictions. So after doing lot of research we found that the balanced training of the algorithm is the best way to avoid the bias and variance in the algorithm and get a good accuracy.
Parameter Identified
- Blinking of eyes
- Teeth enchantment
- Bigger distance for eyes
- Moustaches
- Double edges, eyes, ears, nose
- Iris segmentation
- Wrinkles on face
- Inconsistent head pose
- Face angle
- Skin tone
- Facial Expressions
- Lighting
- Different Pose
- Double chins
- Hairstyle
- Higher cheek bones
Development:
After analysis we decided to use the PyTorch framework along with python3 language for programming. PyTorch is chosen as it has good support to CUDA i.e Graphic Processing Unit (GPU) and it is customize-able. Google Cloud Platform for training the final model on large number of data-set.

Log in or sign up for Devpost to join the conversation.