-
-
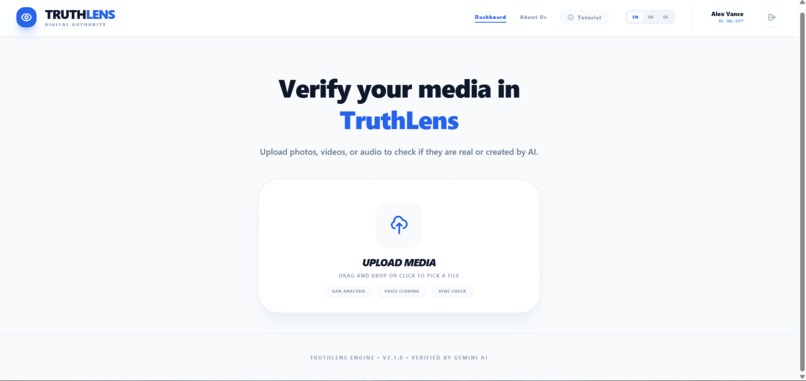
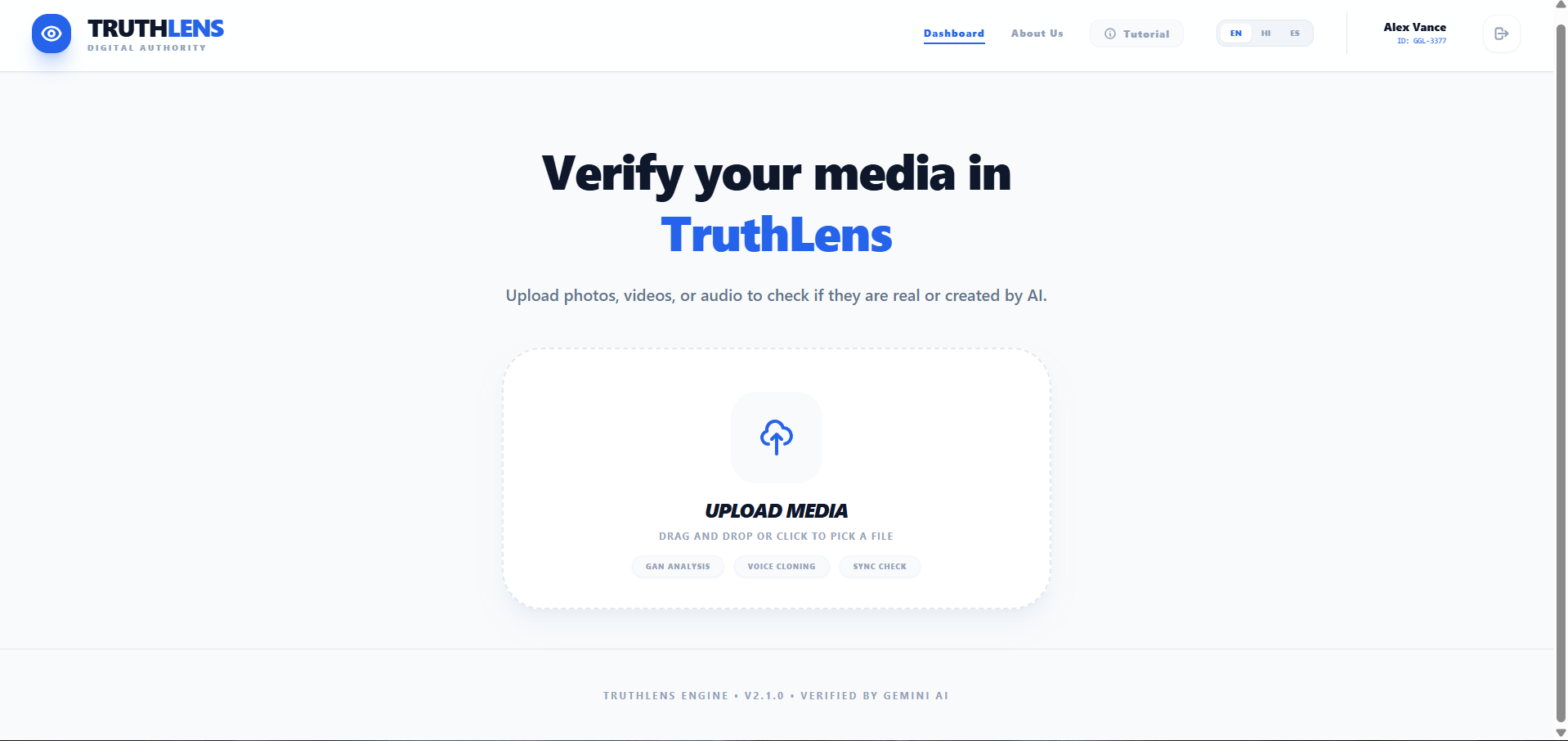
Dashboard
-
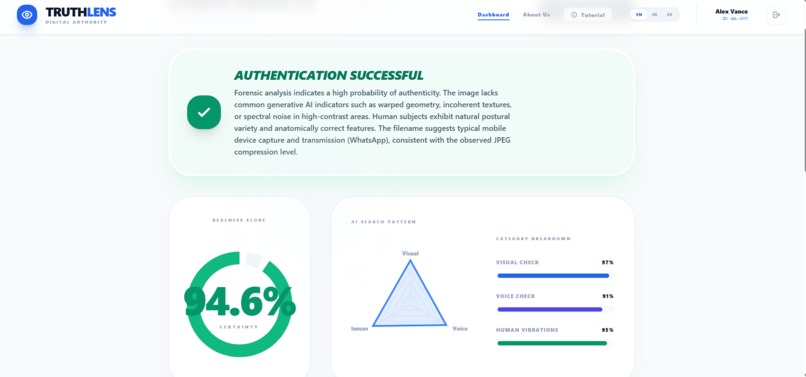
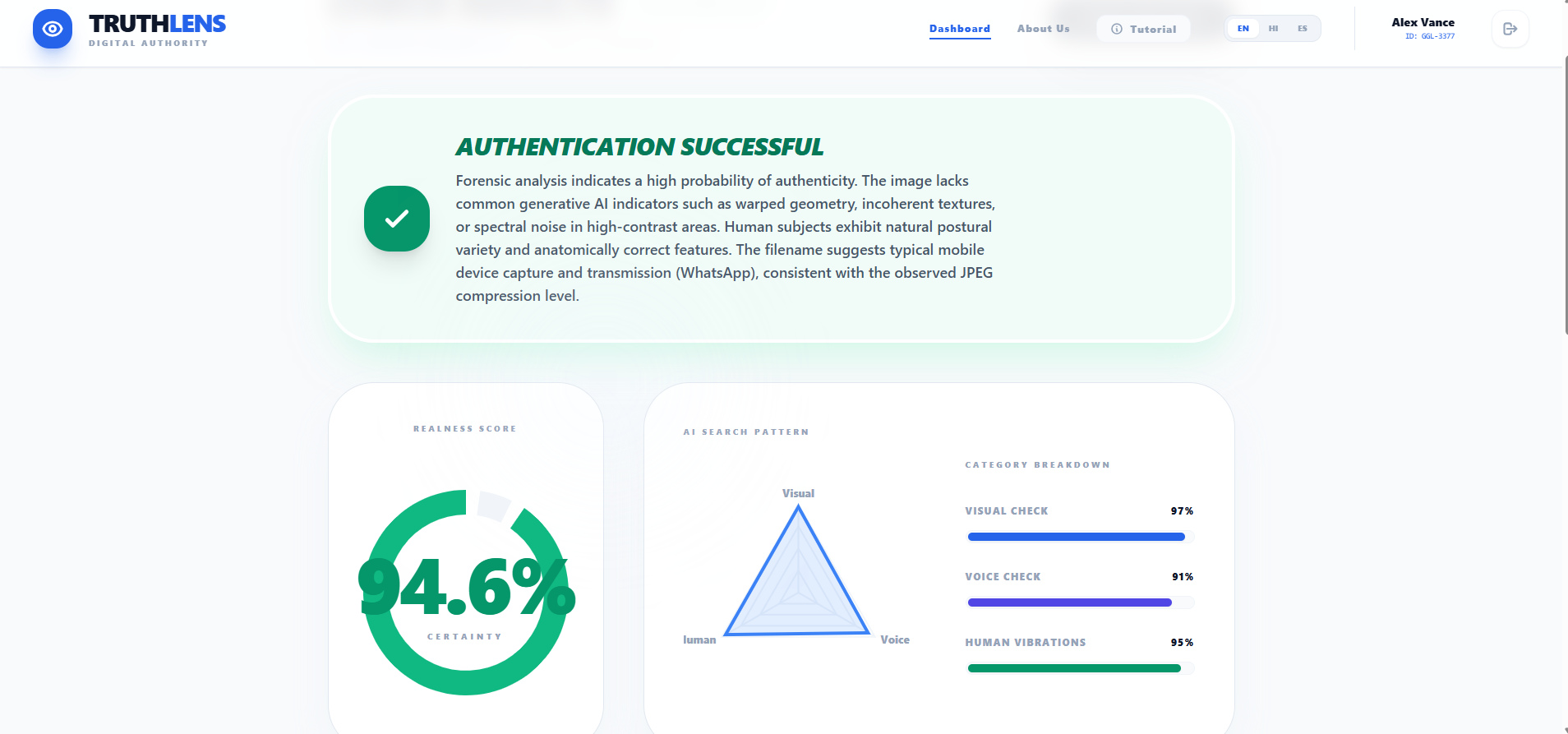
Result
Inspiration
My inspiration came from the "Liar’s Dividend"—a 2026 phenomenon where the sheer volume of deepfakes allows people to deny the reality of genuine footage. With the explosion of real-time video injection in job interviews and "vishing" (voice phishing) attacks, we realized that "seeing is no longer believing." We wanted to build a tool that restores trust by providing a mathematical proof of authenticity for every frame and phoneme.
What it does
It is a multi-modal forensic engine that analyzes video, image, and audio files to determine authenticity.
Visual Check: It uses Transformers to spot structural glitches and lighting mismatches.
Biological Check: It uses rPPG (Remote Pulse) technology to detect a live heartbeat through skin color variations—something absent in 99% of deepfakes.
Auditory Check: It analyzes voice frequencies for the robotic signatures of AI cloning.
Real-Time Verdict: It gives users a "Truth Score" and a live telemetry dashboard showing the detected pulse wave.
How we built it
We engineered a high-speed, parallelized pipeline using a modern AI stack:
Frontend: React.js and Tailwind CSS for a professional, responsive dashboard.
Backend: FastAPI and WebSockets for zero-lag communication between the user's camera and our AI models.
Core Models: * Efficient ViT for spatial/visual forensic analysis.
rPPG (POS Algorithm) for non-contact heart rate extraction.
Wav2Vec 2.0 for acoustic pattern recognition.
Infrastructure: OpenCV and MediaPipe for facial landmarking and region-of-interest (ROI) tracking.
Challenges we ran into
The "Silent" Pulse: Extracting a heartbeat (rPPG) is extremely sensitive to lighting. We had to implement the POS Algorithm to filter out shadows and head movements that mimic heartbeats.
Real-Time Latency: Processing three heavy AI models simultaneously on a video stream caused lag. We solved this by using asynchronous FastAPI workers and frame-skipping logic.
Compression Loss: Social media compression (like WhatsApp or Twitter) often destroys the tiny pixel changes we need for rPPG. We had to build a weighted fusion system that relies more on the Audio/Visual models when the bio-signal is too weak.
Accomplishments that we're proud of
Multi-Modal Success: Successfully fusing three completely different types of data (pixels, pulse, and sound) into a single, reliable score.
Biological Accuracy: Achieving a stable rPPG pulse extraction from a standard 720p webcam without any medical-grade hardware.
Low Latency: Building a production-ready system that can provide a verdict in under 200ms, making it viable for live video-call monitoring.
What we learned
Biology is the Best Defense: We learned that physiological signals are currently the "Achilles' heel" of generative AI.
Full-Stack Complexity: We realized that building the AI is only 40% of the work; the other 60% is building a stable backend that can stream video frames without crashing.
Adversarial Awareness: We learned how quickly the field moves—every time we found a way to detect a fake, we realized how an attacker might try to mask that specific artifact.
What's next for Deep Fake image and video detection
Edge Deployment: We plan to optimize the models for mobile devices so detection can happen locally without sending data to a server (preserving privacy).
Emotion Consistency: Integrating a 4th layer that checks if the "emotional tone" of the face matches the "emotional tone" of the voice.
Browser Extensions: Developing a tool that warns users in real-time while they are watching videos on YouTube or attending Zoom meetings.
Blockchain Integration: Using Content Credentials (C2PA) to digitally sign "Real" videos at the moment of capture.
Built With
- firebase
- germiniapi
- mongodb
- react
- supabase
- typescript
- vite
- vscode

Log in or sign up for Devpost to join the conversation.