-
-
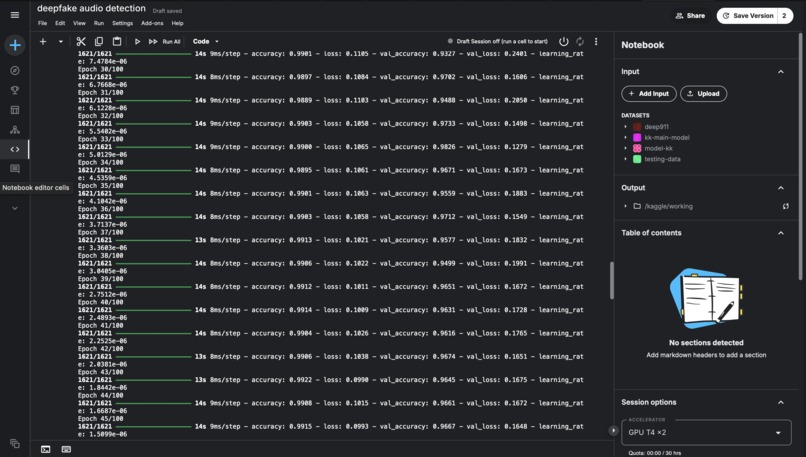
Training Model using Kaggle 2*T4 GPU
-
Training Model using Kaggle 2*T4 GPU
-
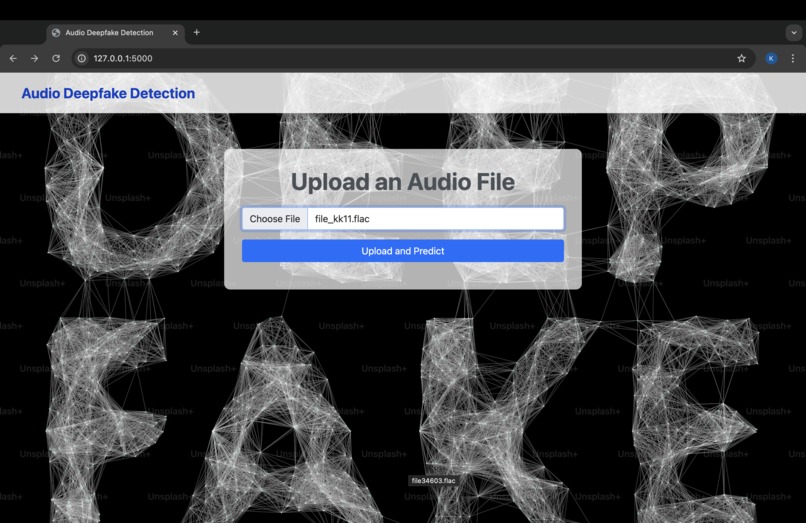
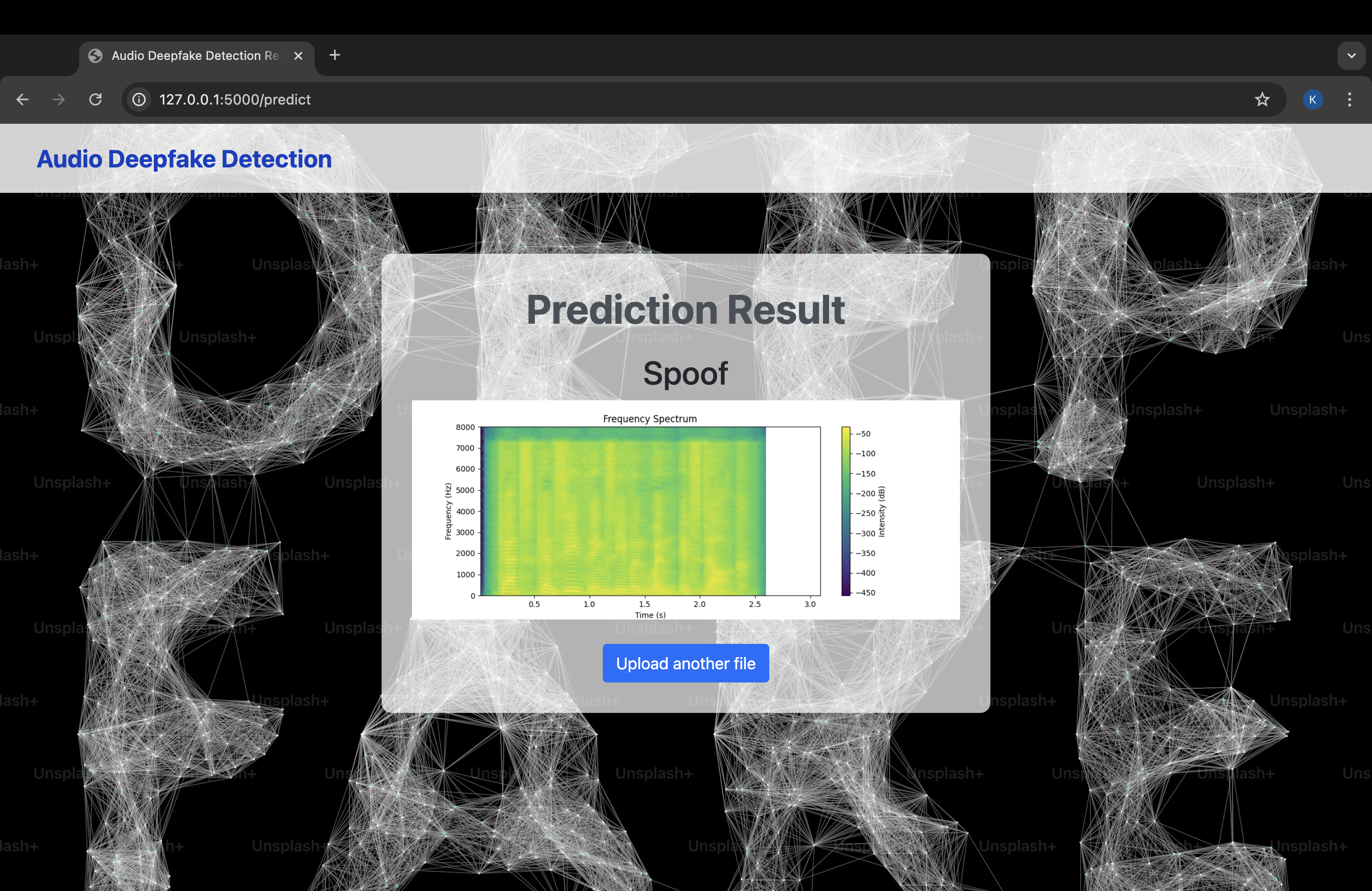
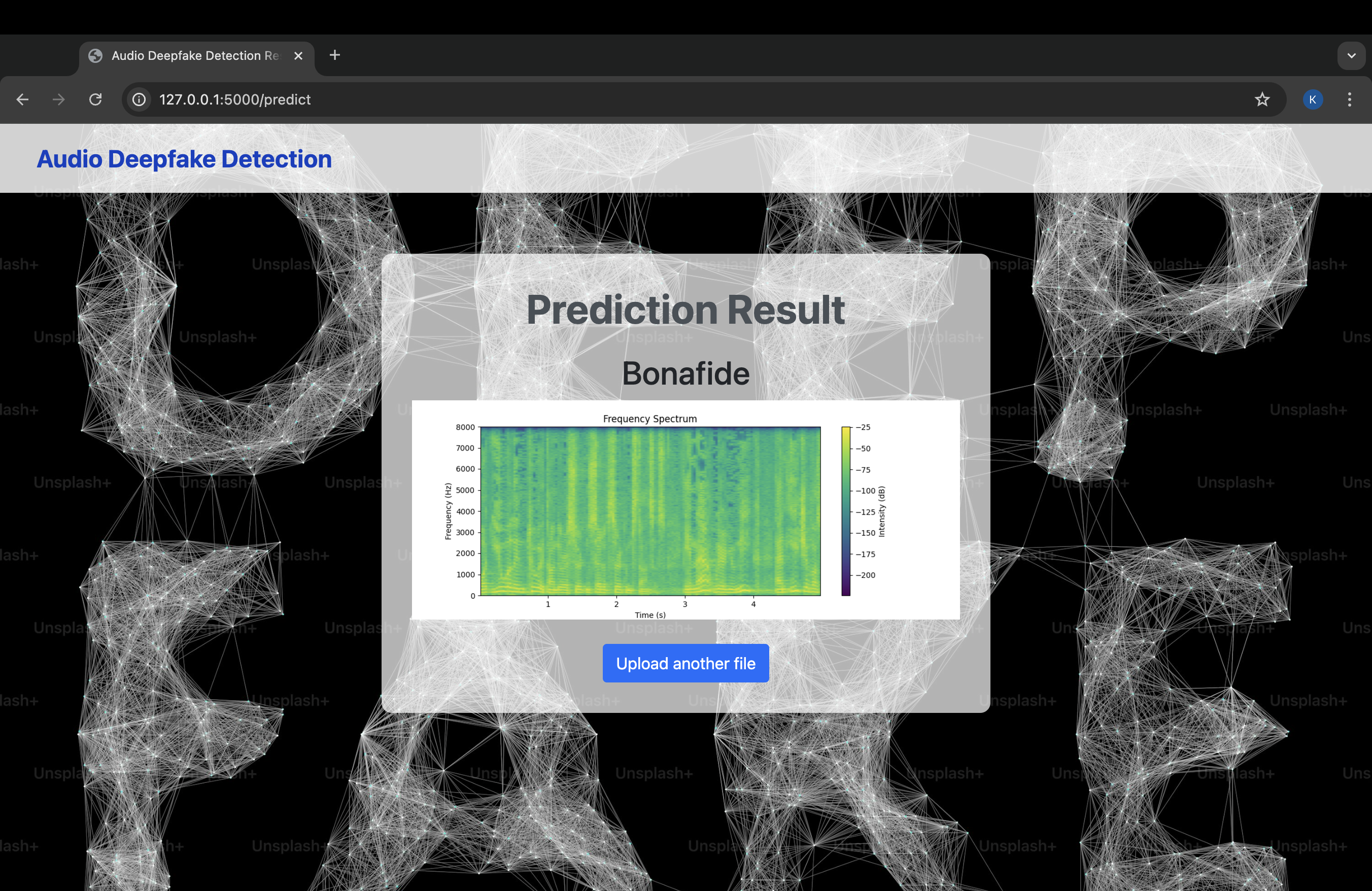
Web App Working
-
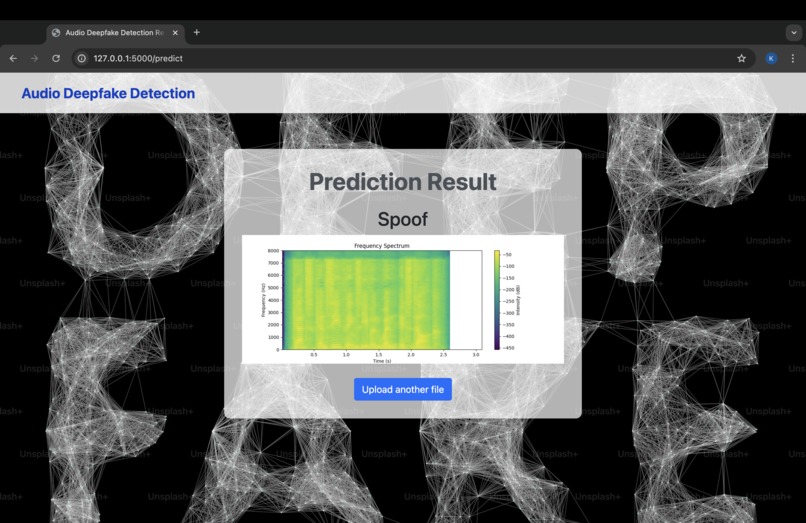
Web App Working
-
Web App Working
-
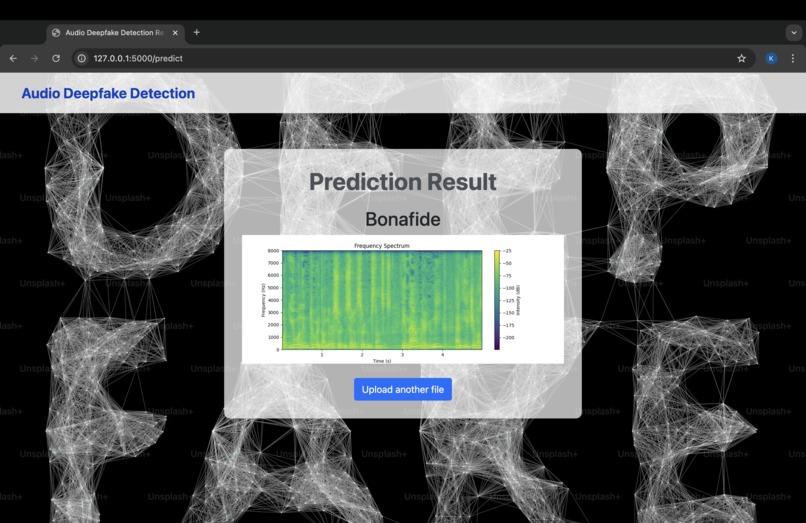
Web App Working
Inspiration
The inspiration behind this project comes from the growing concerns around the authenticity of audio and its impact, particularly in the context of misinformation, cybercrime, and the media. With the rise of deepfake technology, detecting altered or synthetic audio has become essential to maintain trust in online communications.
What it does
This project aims to detect whether an audio file is genuine (bonafide) or fake (spoofed), specifically targeting deepfake audio. The system uses machine learning to classify audio inputs and predict whether the audio is manipulated or authentic. The web-based application allows users to upload an audio file and receive real-time predictions about its authenticity.
How I built it
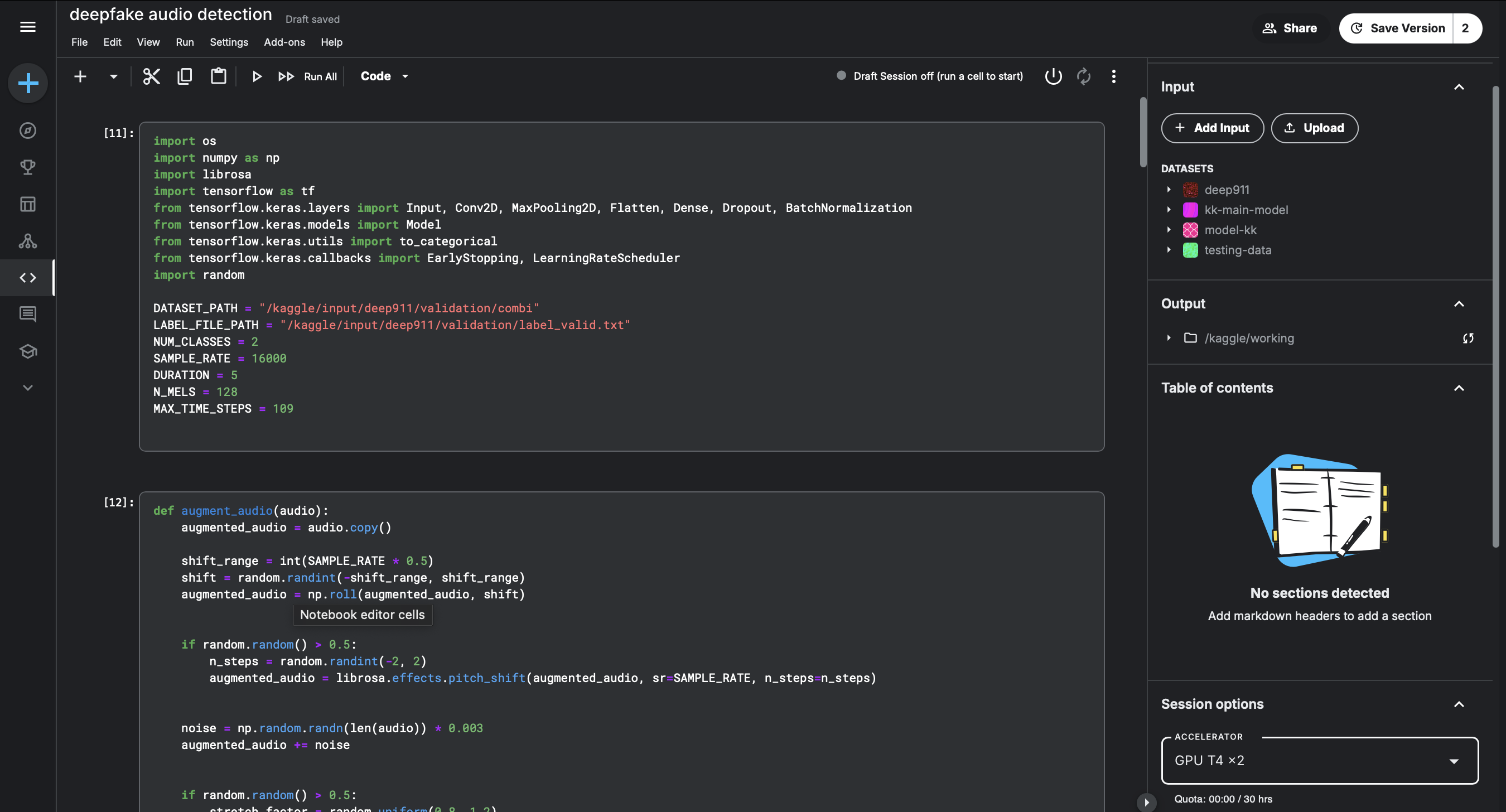
AI Model:- In order to train the AI Model I used python notebook. I did faced few issues while training the model so I preferred to switch to Kaggle and use its Cloud GPU which provides the users with 2* T4 GPU's, For training my I did used various Libraries such as Tensorflow, Librosa, Numpy, Matplotlib, sklearn, etc. I used Convolutional Neural Network (CNN) to filter out the impurities in the audio data provided by the user so that the model will be able to give concise and accurate prediction. Web App:- I have integrated my model in a Flask App that helps the users to interact with the same using the browser. I have used Chrome Storage API to store the last predicted audio which is also considered under Write and Rewrite API.
Challenges I ran into
The main challenge I faced was gathering the dataset, which has enough quality and quantity of data. After browsing the whole web frequently i some how managed to get the dataset from Kaggle but the challenge was not over yet I had to filter out the data and arrange it in a way that there are equal no of spoof and bonafide data samples so that the AI model can learn in a better way and can be used for accurate predictions. As of now the model is trained for approximately 11,000 data samples which are way too low if I want to publish it on a global level. Lack of Quality as well as Quantity Data
Accomplishments that I am proud of
I had faced many issues while training my model during the initial stage I had to wait for number of hours just to run the number of epochs allocated but at last my hard work paid off when I trained my model with a validation and model accuracy of over 97%.
What I learned
The importance of dataset quality and preprocessing in training effective machine learning models. Challenges in working with audio data, including extracting meaningful features for machine learning models. We can't express the hard work and complexity of a software just by having a look at its UI/UX.
What's next for Deep-Fake Audio Detection
Improvement in Model Accuracy: I plan to gather a larger, more diverse dataset to improve the model’s performance and accuracy in detecting deepfake audio across different types of manipulations. User Experience Enhancement: Improving the UI/UX of the web application to make it even more intuitive and visually appealing. Adding real-time audio detection features which can be used for spam calls and can prove to be useful to keep the users safe from any fraudulence.


Log in or sign up for Devpost to join the conversation.