-
-
DeepCodi Poster
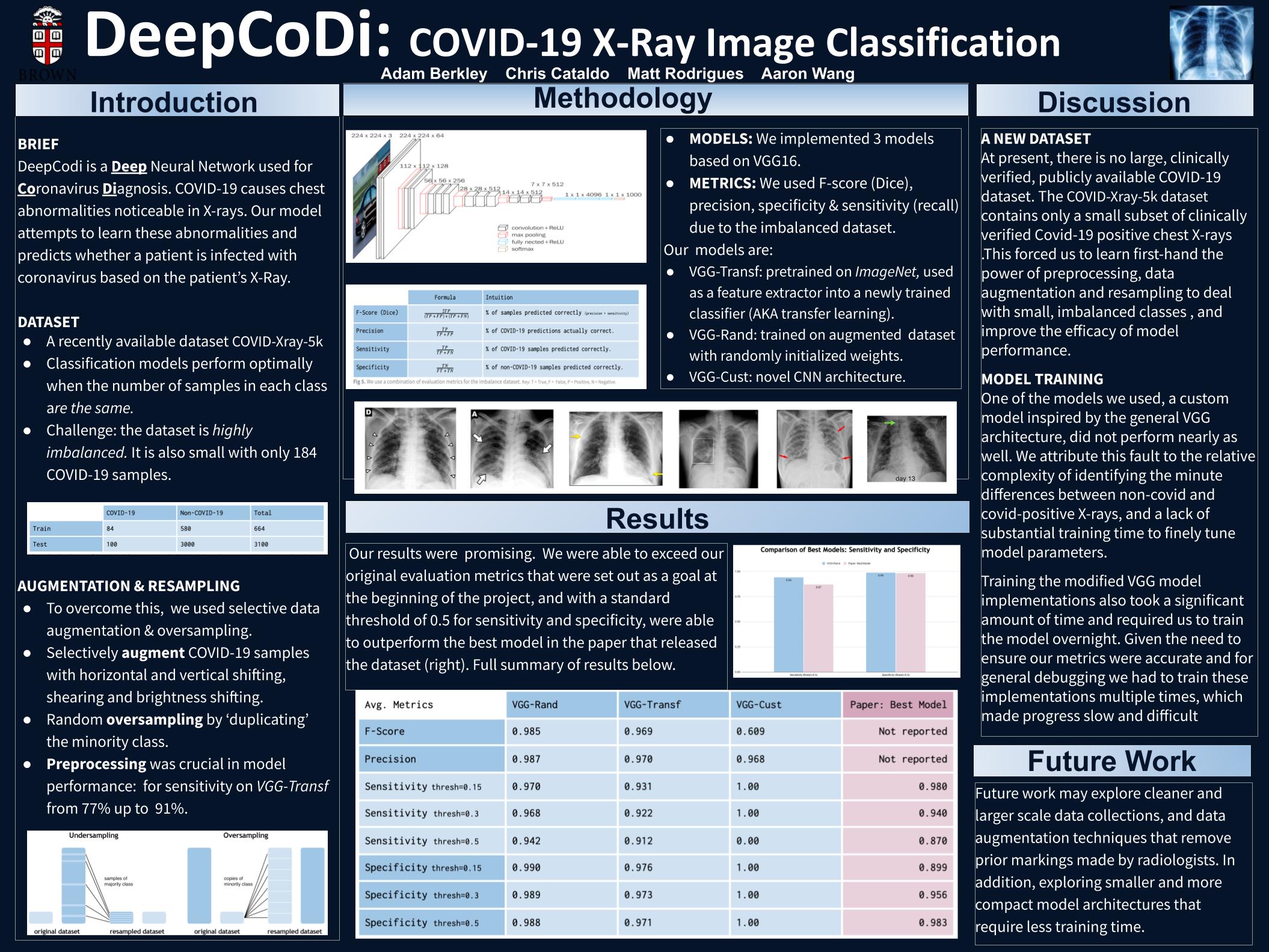
Final Deliverables
Project Check-Ins
- Checkin-1 (Proposal): link
- Checkin-2 (Reflection): link
- Initial and final checkin were Zoom/signup only.
Note: Brown accounts should have access to all links. If you require access and don't have it, please email: mrod@brown.edu, adam_berkley@brown.edu, christopher_cataldo@brown.edu, aaron_j_wang@brown.edu and we'll be happy to take care of it.
Thank you for your time and interest in our project!
Built With
- keras
- python
- tensorflow





Log in or sign up for Devpost to join the conversation.