-
-
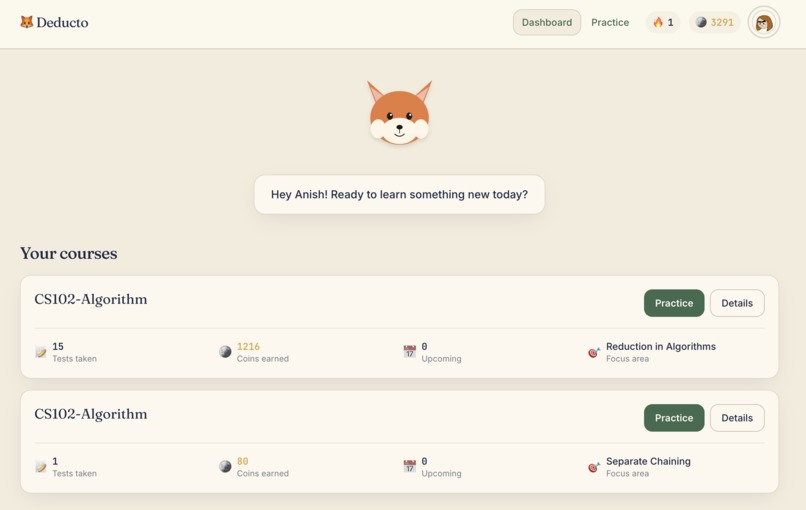
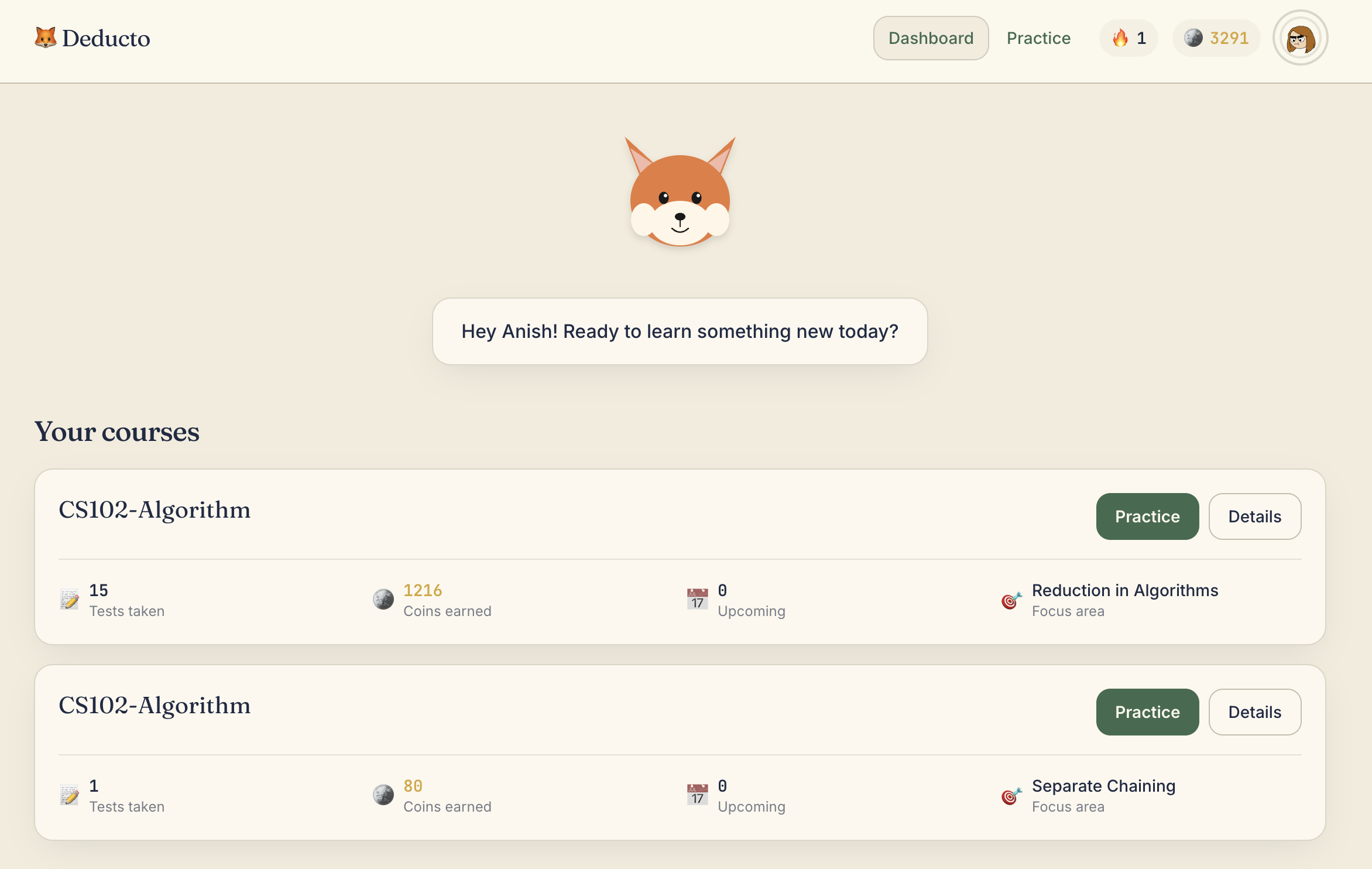
Home Page
-
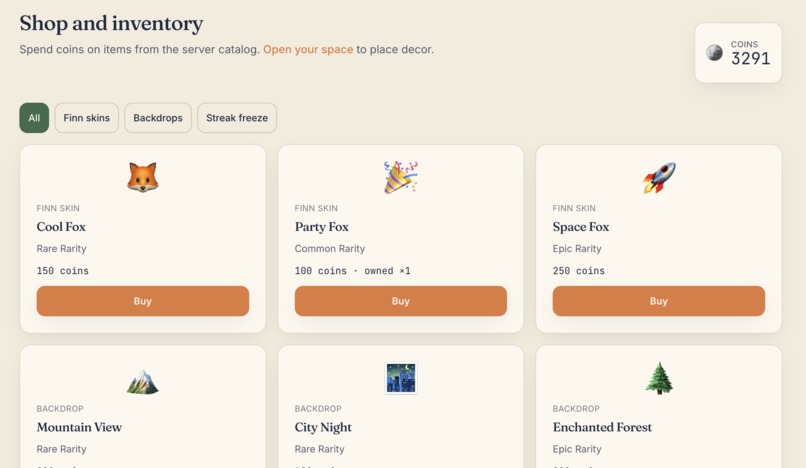
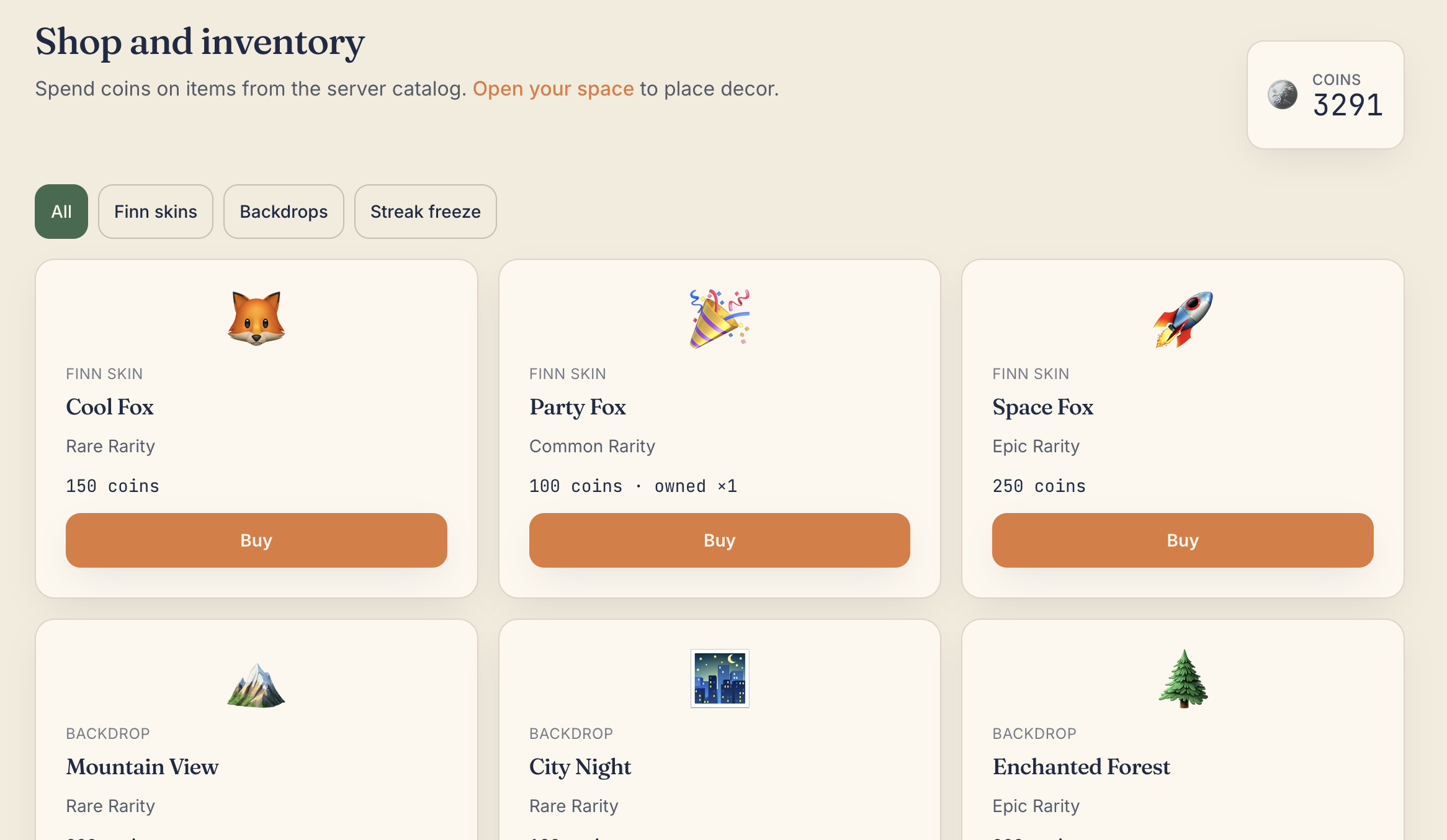
Store
-
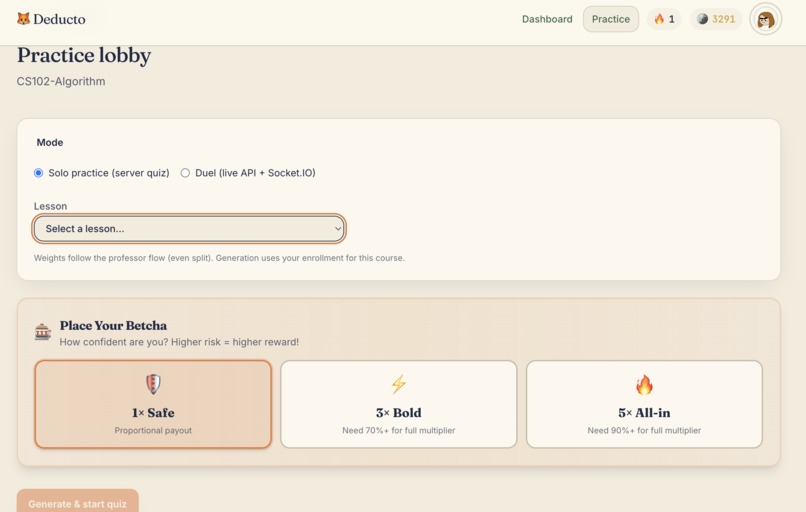
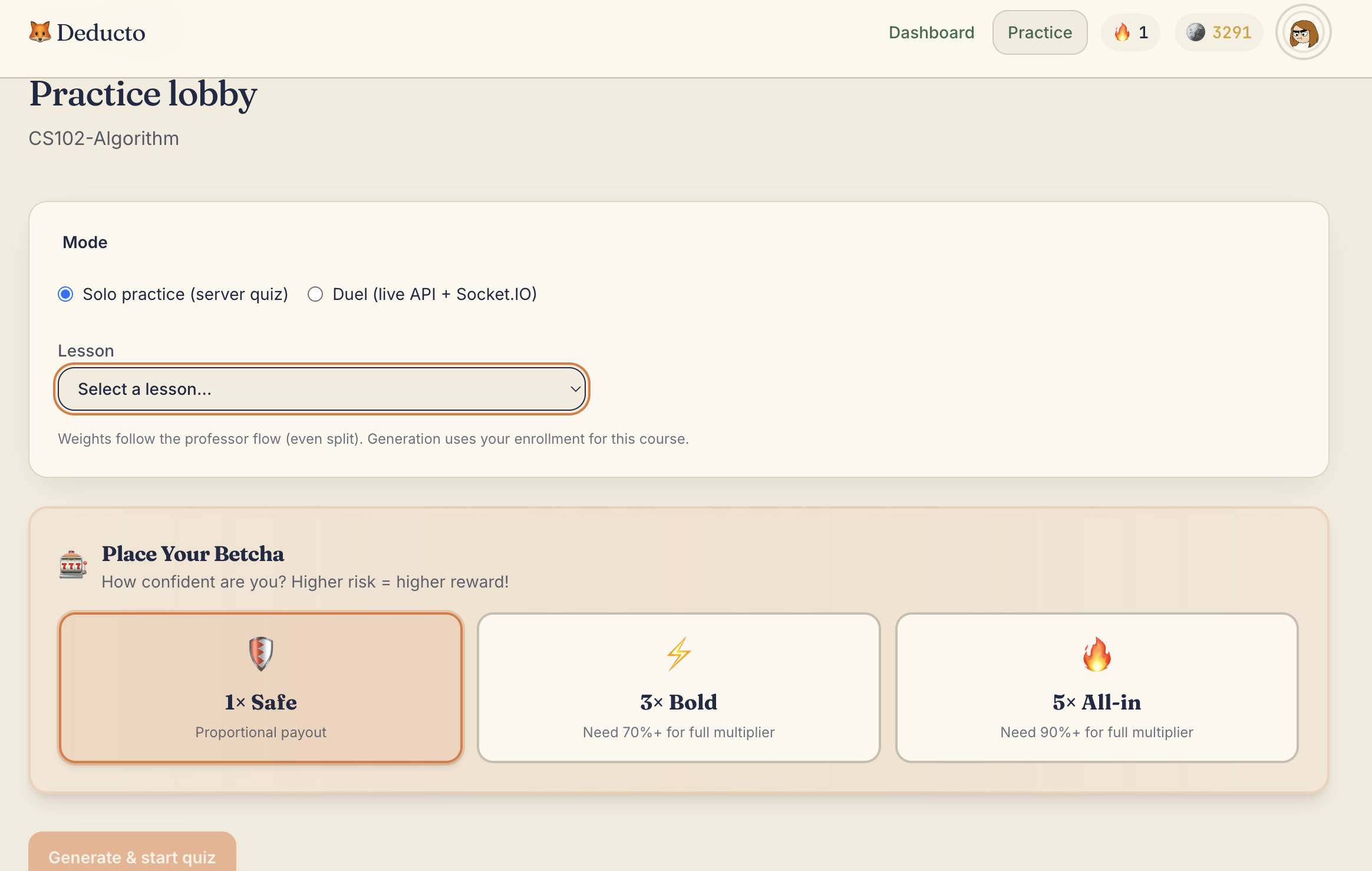
Practice Lobby
-
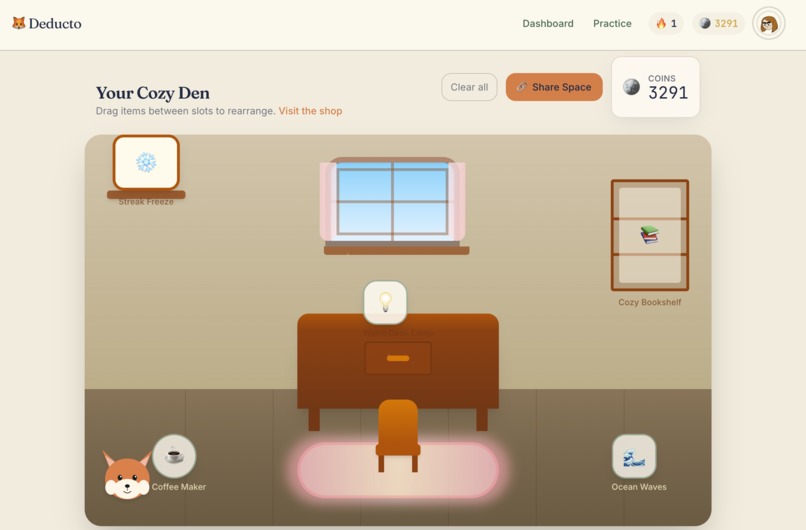
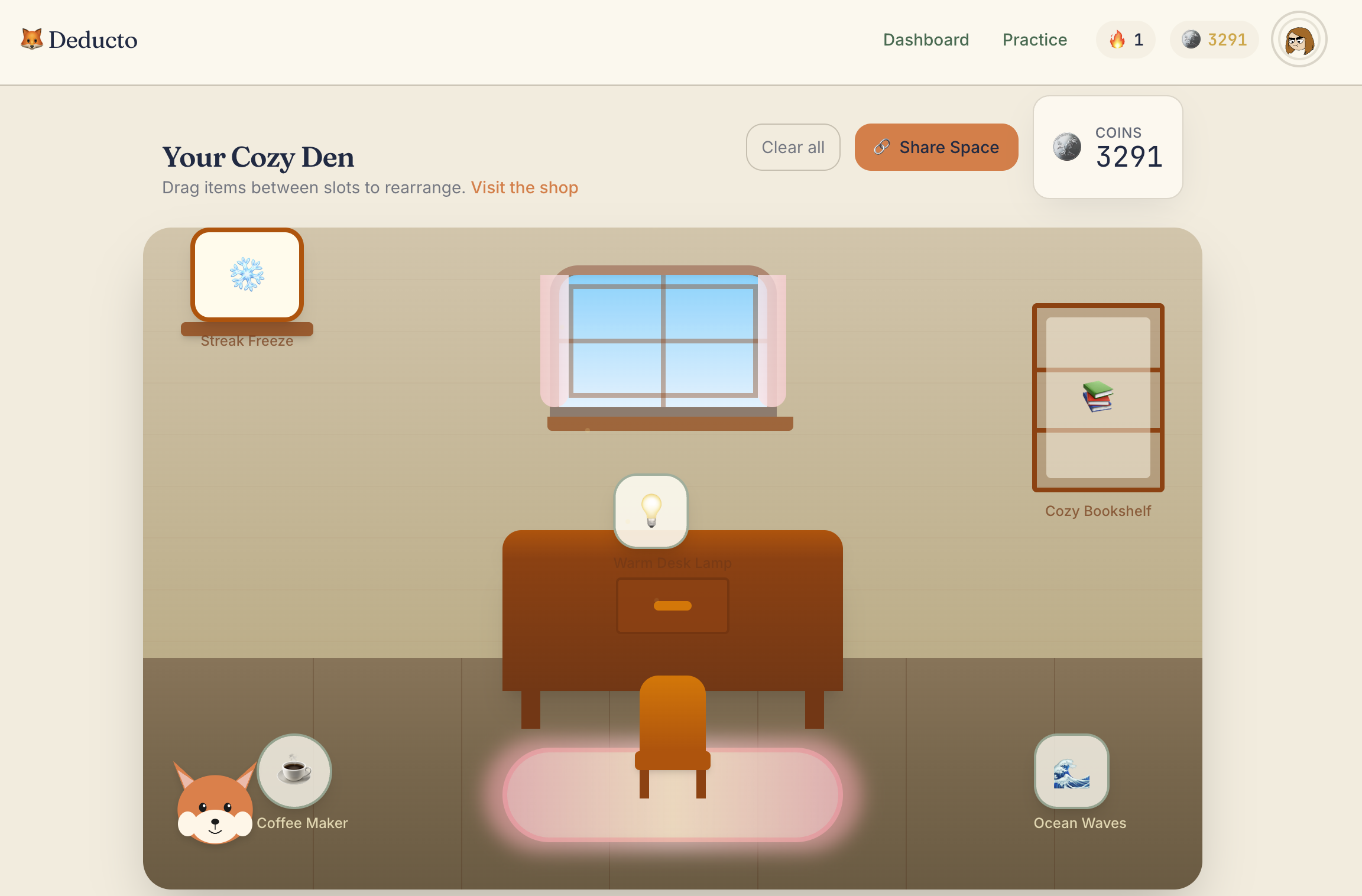
Space
Deducto
Where coursework becomes a daily habit.
Deducto is an AI-powered learning platform that transforms passive coursework into an engaging daily routine. Professors can generate lesson-aligned quizzes quickly, while students stay motivated through live quiz events, duels, confidence wagers, streaks, rewards, and Finn the Fox voice companion.
Elevator Pitch
Deducto bridges the gap between learning and engagement by combining real class content with consumer-grade retention mechanics: synchronized quiz moments, confidence wagering, streak-based progression, and voice-first interactions.
Inspiration
Traditional LMS platforms are great at storing content, but weak at creating habits.
We were inspired by how products like Duolingo and social apps keep users returning daily through emotional feedback loops, identity, and momentum.
Our goal: apply those same mechanics to actual coursework, not just generic trivia.
What It Does
For Students
- Join classes using a code
- Take scheduled Tempo quizzes and on-demand practice sessions
- Challenge classmates in duels
- Place Betcha multipliers (
1x,3x,5x) before quizzes - Earn coins, maintain streaks, and unlock personalization
- Customize and share their Space
- Interact with Finn via voice cues and guided feedback
For Professors
- Create and manage courses
- Upload learning materials and define lessons
- Trigger concept extraction from lesson content
- Generate, review, and refine quiz questions
- Schedule quiz windows and track class-level performance
How We Built It
We built Deductible as a full-stack web platform with a modular architecture:
- Frontend: React + TypeScript + Vite, with Zustand + TanStack Query
- Backend: FastAPI, role-based auth, API-first architecture
- Realtime: Socket.IO-powered synchronized quiz sessions
- AI pipeline: concept extraction + quiz generation from lesson context
- Voice layer: Finn interactions powered by ElevenLabs integration
- Data/integrations: Supabase-backed persistence and cloud-ready storage interfaces
We split responsibilities into platform, intelligence, engagement, and experience layers so each subsystem could evolve independently.
Challenges We Faced
- Realtime synchronization: Keeping quiz state and timing consistent across multiple participants
- Balancing AI quality vs. speed: Generating useful quiz content fast enough for interactive workflows
- Scope control in hackathon constraints: Prioritizing end-to-end flow over edge-case perfection
- Voice UX reliability: Ensuring smooth fallback behavior when external voice calls are delayed
- Cross-role complexity: Designing clear student and professor experiences without duplicating logic
What We Learned
- Product clarity matters more than raw feature count.
- Abstracting AI workflows early makes iteration dramatically faster.
- Realtime systems demand deterministic event design from day one.
- Gamification only works when rewards, identity, and progression are tightly connected.
- Voice feels magical only when latency and context are thoughtfully handled.
Accomplishments We’re Proud Of
- Built a working end-to-end learning loop from content to quiz to rewards
- Unified student and professor flows in a single coherent product
- Added realtime competition and confidence mechanics, not just static quizzes
- Created a recognizable product identity around Finn and voice interactions
- Shipped a project with clear post-hackathon extensibility
Math Behind the Motivation Loop
We modeled engagement as a weighted function of consistency, challenge, and reward:
[ E = \alpha S + \beta C + \gamma R ]
Where:
- (S) = streak consistency signal
- (C) = challenge intensity (duels, timed quizzes, Betcha)
- (R) = reward progression (coins, unlocks, personalization)
With:
[ \alpha + \beta + \gamma = 1, \quad \alpha,\beta,\gamma \ge 0 ]
A simplified reward expectation model for Betcha-like decisions:
[ \mathbb{E}[\text{coins}] = p \cdot m \cdot b + (1-p)\cdot f(b) ]
Where:
- (p) = probability of meeting threshold performance
- (m) = selected multiplier (
1, 3, 5) - (b) = base reward
- (f(b)) = fallback payout function when threshold is not met
These equations are intentionally simple, but they guided how we tuned risk/reward and retention dynamics.
Tech Stack
- React 19, TypeScript, Vite
- React Router, Zustand, TanStack Query
- Tailwind CSS, Framer Motion
- FastAPI, Uvicorn, Pydantic
- Supabase client, JWT auth
- python-socketio (realtime quiz room)
- OpenAI-compatible AI integrations
- ElevenLabs voice integrations
- Pytest for backend testing
Project Structure
frontend/ -> UI, routes, stores, voice/realtime clients
backend/ -> APIs, auth, courses, quizzes, engagement, scoring
Built With
- ai
- fastapi
- gemini
- gemma
- langchain
- python
- react
- typescript

Log in or sign up for Devpost to join the conversation.