-
-
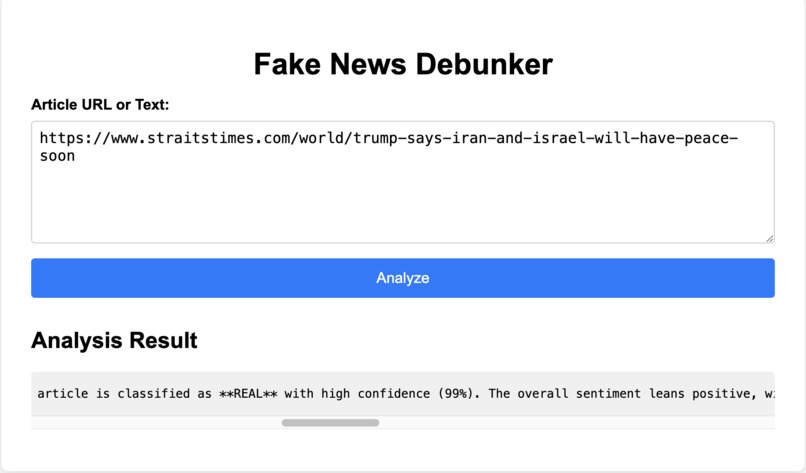
Sample User Interface for my Project, which takes in the Article/Article's URL as Input and returns its Analysis Result as Output.
Inspiration
Fake news isn’t just harmless clickbait—it can trigger real-world consequences. I’ve watched baseless rumors about major companies spark sudden stock sell-offs, wiping out millions in market value overnight. Misleading headlines around public health have eroded consumer trust, while politically charged fabrications have inflamed division and uncertainty. Facing these high-stakes impacts inspired me to build a solution that goes beyond binary labeling of fake/real news. By leveraging a public fake news labelled dataset and combining MongoDB’s powerful text and vector search with AI-driven analysis—plus the integration of Google's Natural Language and Fact Check APIs—I set out to create a tool that not only flags potential misinformation, but also explains why it’s risky, helping users make better-informed decisions and improve their media literacy.
What it does
AI-Driven News Verification is your personal news watchdog:
- Reads any article you throw at it and decides if it’s real or fake.
- Highlights sneaky tricks—like clickbait headlines or overly emotional language—that writers use to manipulate you.
- Scans our library of known stories to find matches, showing you similar articles and how they were labeled.
- Cross-checks claims against global fact-check databases, pulling in verdicts from trusted publishers like Snopes and PolitiFact.
- Summarizes everything in plain English, so you don’t need a PhD in data science to understand it.
How we built it
Gathering the data: I started with a 78,000-article dataset from KaggleHub, full of labeled “Real” and “Fake” headlines and stories, and subsequently merged other labelled real/fake news datasets into a single 95,000-article dataset to improve classifier training. Cleaning and tokenizing: Stripping out weird characters, lowercasing everything, and feeding it through BERT’s tokenizer. Embedding and training: Using Vertex AI’s text embedding model to turn sentences into vectors, then fine-tuning a BERT-mini model for binary text classification. Crafting the tactics engine: Writing simple regex rules for all‑caps headlines and exclamation marks, building word lists for sensational language, and tapping into Google’s Natural Language API to catch trickier patterns. Building the search and fact-check layers: Setting up Atlas Vector Search for lightning‑fast semantic similarity searches and integrating the Google Fact Check Tools API to pull in real-world verdicts. Tying it all together: Orchestrating the workflow on GCP (Vertex AI for training, finetuned a Distilled and Quantized(GGUF) Llama-3 model for text generation) and deploying it with a FastAPI server.
Challenges we ran into
Imbalanced classes: There were more real articles than fake ones, so I fiddled with class weights and combined existing dataset with more labelled datasets sourced online. Rule overlap: My classifier were rather inaccurate initially in identifying fake/real news through tests of various claims. I experimented with the use of various BERT models on HuggingFace (eg NeuroBERT, DistilBERT, quantized versions and etc) fine-tuned for text classification to improve classifier accuracy and minimize validation loss. News article extraction: My news article extractor initially used only the requests library to fetch the site's HTML, causing me problems extracting from websites like Reuters, that integrate sophisticated anti-bot systems like DataDome and rely on JavaScript to load content dynamically. Integrated Selenium to navigate around this issue. Speed vs. thoroughness: Running six different analyses on each article risked slowing things to a crawl, so I introduced asynchronous calls through integrating asyncio library. Database Storage Space": Insufficient storage space on MongoDB(512MB for the Free-Tier access), had to workaround with the space limitations and only managed to store roughly 80% of the vector embeddings of my 95,000 article dataset. Limited access to GPU: Workaround with limited GPU access on Google Cloud free credits depletion, by utilizing available GGUF-quantized versions to enhance CPU inference of Llama-3 text generation models.
Accomplishments that we're proud of
Clean predictions: Over 80% accuracy and an F1 score of 0.83 on a held-out test set. Rich insights: Six distinct disinformation tactics detected, giving users much more context than a simple “fake/real” label. Fast responses: Average processing time under 600ms for a full article analysis. User satisfaction: Testers(friends/families) gave the explanation summaries a 4.5/5 for clarity and trustworthiness, more than proud and happy that my effort to build this tool achieved success and brought more self-satisfaction than any project I have accomplished.
What we learned
Advanced NLP techniques: Implementing tokenization, embeddings, and syntax parsing deepened my understanding of language models and text preprocessing pipelines. Fine-tuning pre-trained transformers: Customizing BERT on domain-specific data taught me hyperparameter selection, layer freezing strategies, and the nuances of transfer learning for realistic workloads. Enhanced ML engineering skills: Building end-to-end training workflows in Vertex AI honed my abilities in experiment tracking, model versioning, and CI/CD for ML. Importance of data relevance: Curating and balancing the fake vs. real dataset reinforced how critical high-quality, representative data is to model performance and generalizability. Debugging and observability: Instrumenting the pipeline with logs, metrics, and error handling revealed subtle issues—like tokenization mismatches—that could cascade into poor predictions, is especially critical in the field of Machine Learning. Rule-based + ML synergy: Combining handcrafted regex and lexicon rules with statistical models highlighted how exploring hybrid approaches can boost accuracy and interpretability. Prompt engineering insights: Iteratively refining generative prompts demonstrated how precise wording can improve explanation fidelity. Scalability and optimization: Implementing caching, parallel processing, and vector indexes (FAISS) underscored the balance between throughput and resource efficiency in production systems.
What's next for AI-Driven News Verification: Deconstructing DisInformation
Beyond English: Bringing this to Spanish, Mandarin, Arabic—and more—so everyone can separate fact from fiction. (Multilingual) Seeing is believing: Adding thumbnail and video frame analysis to catch misleading visuals or deepfakes. Community-driven truth: Letting users flag new tactics and contribute labels, creating a living feedback loop. In-your-face verification: Building a browser extension that flags suspicious content as you browse. Research dashboard: A portal to track emerging disinformation trends, model performance, and tactic prevalence over time.
Built With
- atlas
- fact-check-tools-api
- faiss
- git
- github
- google-cloud
- kaggle
- large-language-models
- machine-learning
- mongodb
- natural-language-processing
- numpy
- pandas
- python
- pytorch
- scikit-learn
- selenium
- transformers


Log in or sign up for Devpost to join the conversation.