Inspiration
I spent years in Treasury and Wealth Management before switching to tech. I know what it feels like to open a 60-page weekly pack on a Friday afternoon: most “breaches” are really data quality noise or definition disputes — but you still can’t wave them through, because the one you ignore is always the real one.
When I started experimenting with Gemini 3, something clicked: extracting structured signals from messy PDFs, scans, emails, and statements suddenly became practical. So I picked a hard problem I actually understand from the inside.
What it does
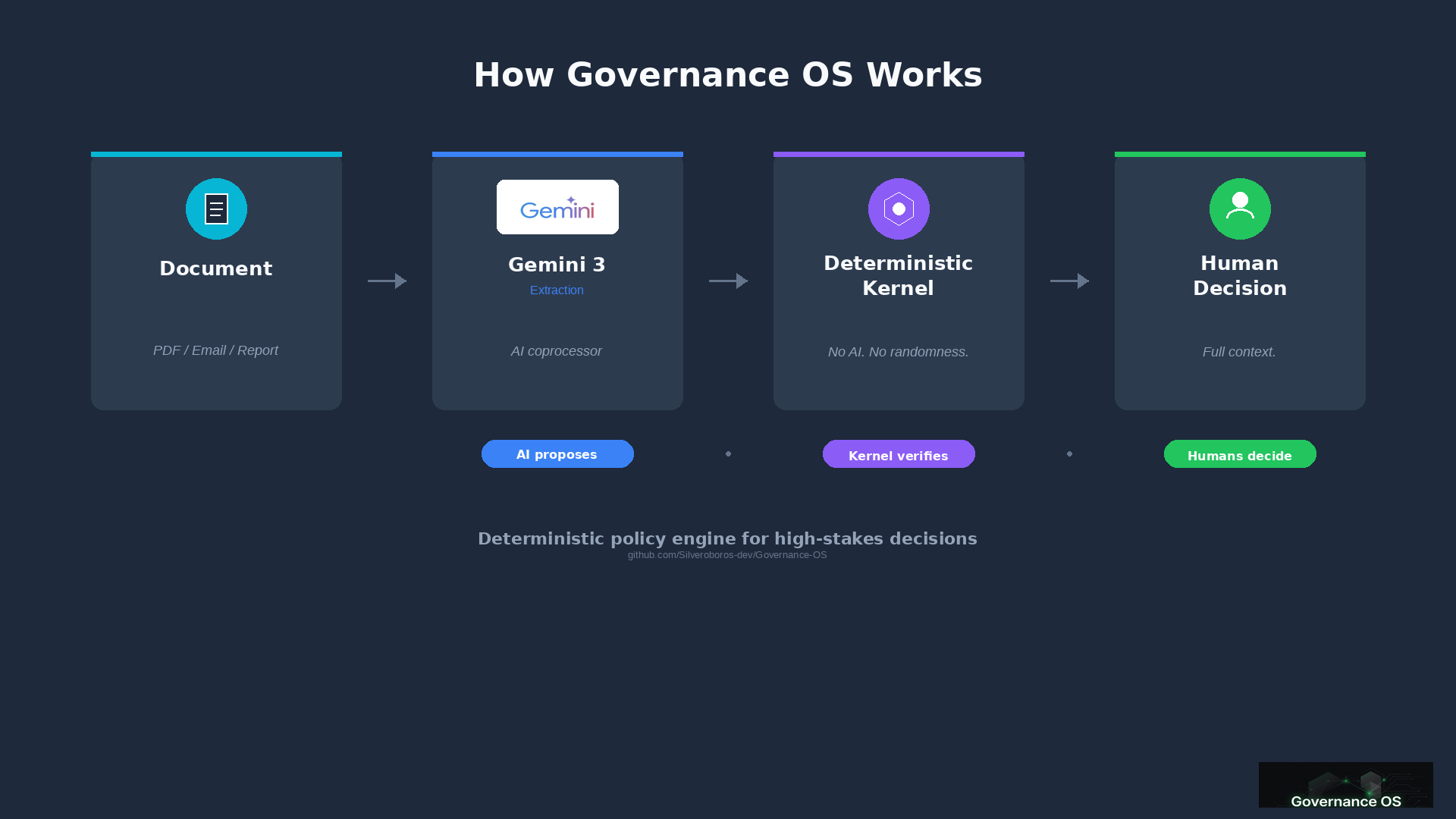
Decision Kernel turns messy evidence into a defensible, replayable decision workflow for Treasury and Wealth.
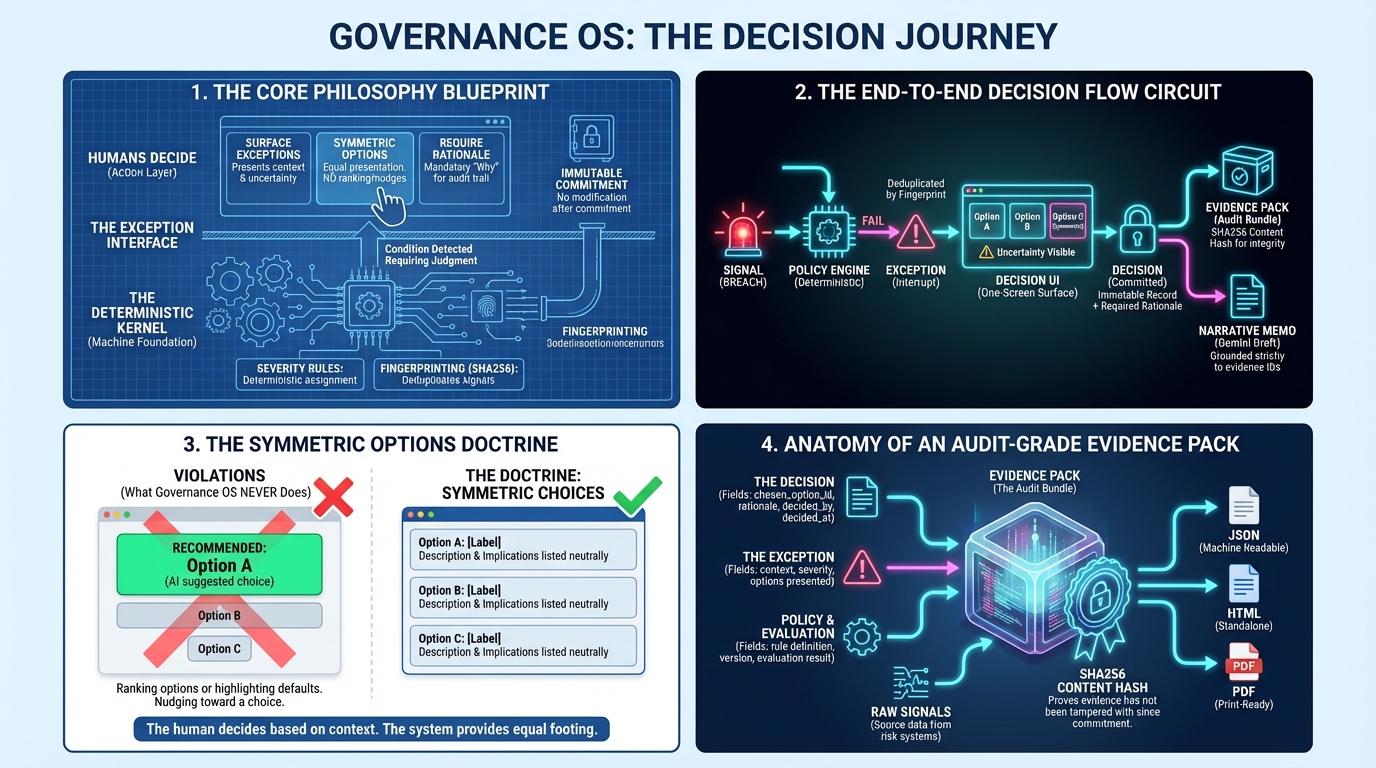
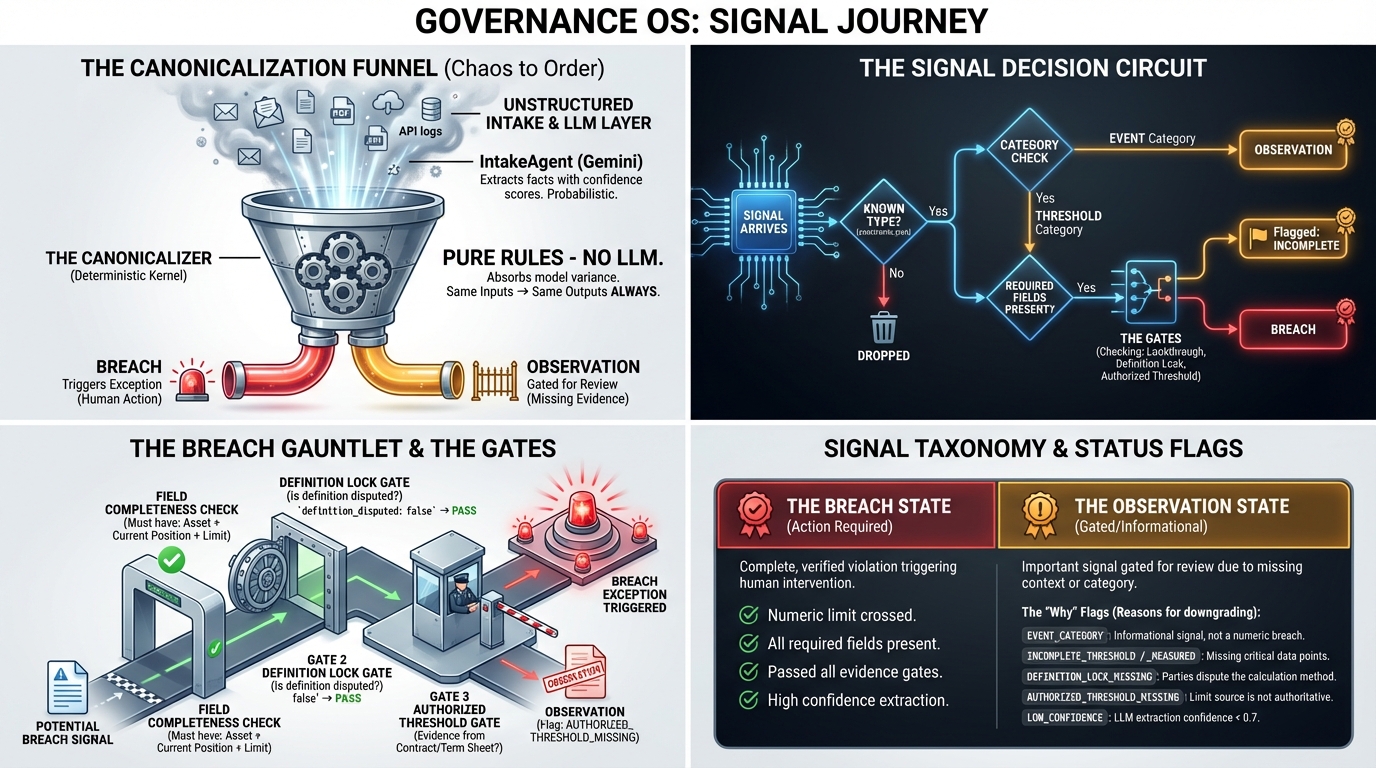
Gemini reads documents and extracts candidate signals with provenance (evidence spans). Then a deterministic kernel validates each candidate before a human sees it. Only confirmed breaches can FAIL policy; everything else becomes an observation/review item.
Key insight: in our test packs Gemini proposed 14 potential breaches → Governance OS confirmed only 4 (28%). The rest were downgraded due to missing evidence or merged as duplicates.
| Metric | Treasury (Orion) | Wealth (Stonebridge) | Total |
|---|---|---|---|
| Candidate breaches (Gemini proposed) | 5 | 9 | 14 |
| Confirmed breaches | 2 | 2 | 4 |
| Downgraded to observations | 3 | 7 | 10 |
| Dropped (invalid) | 0 | 0 | 0 |
| Merged (deduped) | 0 | 0 | 0 |
What remains includes: which policy triggered, which evidence supports it, and symmetric options with no recommendation baked in. The human decides, and an audit pack is generated automatically.
Judge Quickstart (90 sec)
- Open the live app: https://governance-os.web.app/
- Review the flow: messy evidence -> Gemini candidate signals -> deterministic kernel gating -> human decision + audit pack
- Architecture diagram (PDF): https://github.com/Silveroboros-dev/Governance-OS/blob/main/docs/architecture.pdf
- Watch the 3-minute demo: https://www.youtube.com/watch?v=gIQE8P1BVAg
- Verify reproducibility in repo: run make evals and check evals/outputs/
- Key result from test packs: 14 Gemini breach-candidates -> 4 confirmed breaches, 10 downgraded to observations (~71% false-alarm prevention)
How I built it (Gemini 3 integration)
- Gemini 3 Flash extracts candidate signals + evidence spans into JSON.
- Gemini thinking mode improves extraction on ambiguous docs.
- Deterministic kernel canonicalizes/gates; only confirmed breaches can FAIL.
- Gemini drafts narratives only; humans make decisions.
make evals-geminiverifies grounding/schema, but never changes outcomes.
Reproducibility:
make evalsproves determinism + safety boundaries on every run.- Expected: "OVERALL: PASS" with all suites green
- Results: evals/outputs/ (JSON files with timestamps)
- To verify determinism: run 3x, compare hashes in output - must be identical
- Or the full version just ran:
python -W ignore::RuntimeWarning -m evals.runner --suite all --pack all --verbose
Challenges I ran into
The biggest fight was with myself. Gemini 3 makes multi-agent orchestration tempting, but policy evaluation cannot be probabilistic if you want auditability. Agents would have looked impressive and made the system impossible to trust.
I also had to tighten semantics that are easy to get wrong:
- “Event” signals should never become confirmed breaches.
- Observations should never cause FAIL. They should generate review items outside the evaluator.
- “Target bands” and ambiguous definitions must be gated until verified.
And yes: keeping Docker, multiple deploy targets, and a growing test suite in sync while working solo is the unglamorous part.
Accomplishments I’m proud of
- The breach/observation boundary is reproducible from a fresh clone: “make evals” replays the same outcomes consistently.
- The system is designed to be non-manipulative: no “recommended option” UI, symmetric choices, and the LLM is never the source of truth for severity or escalation.
- A Gemini-based CI verifier (“make evals-gemini”) can check grounding and schema compliance for coprocessor outputs, but it cannot change policy outcomes.
What I learned
I'd read about Firebase and GCP but didn't expect to ship anything on them anytime soon. With AI-assisted development I went from reading docs to a deployed system on Cloud Run, Cloud SQL, and Firebase App Hosting in days instead of months. I also learned that the cleanest boundary is architectural, not prompt-based: letting AI propose, but forcing the kernel to verify deterministically.
What's next for Decision Kernel
The system makes the cost of bad policy visible and immediate. Weak policies generate noise. Precise policies stay quiet on what doesn't matter. I think once executives see that, they'll realize managing through better policies has way more ROI than firefighting every day. Next up: policy authoring assistance where Gemini drafts and humans approve, a replay harness for tuning policies against historical data, and expanding beyond treasury and wealth into any domain where high-stakes decisions need audit-grade evidence.
Built With
- claude-code
- docker
- fastapi
- firebase
- gcp
- gemini
- json-mode
- mcp
- next.js
- postgresql
- pydantic
- python
- react
- sqlalchemy
 Chen")

Log in or sign up for Devpost to join the conversation.