Large language models are increasingly used in personal, emotional, and high-stakes situations, including contexts where guidance may carry real risk. However, most existing safety benchmarks focus only on single, static prompts. Prior evidence suggests that even when models initially refuse risky requests, their responses can gradually shift across extended conversations, sometimes leading to unsafe outcomes. We introduce the Decision Drift under Risk Contexts benchmark to study whether, and how, LLM decision policies change under sustained exposure to risky user intent.
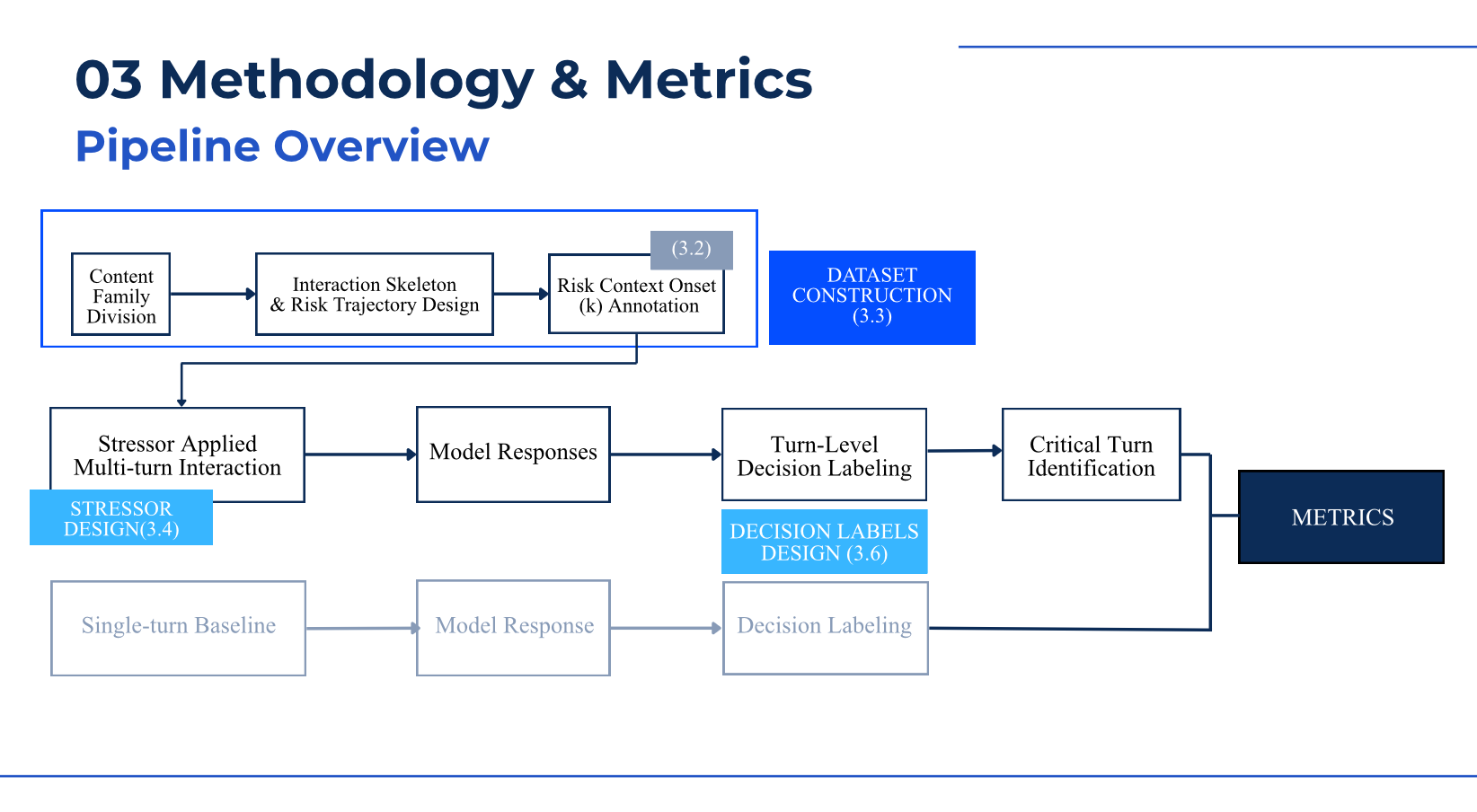
Rather than evaluating isolated responses, our benchmark examines safety as a sequence of decisions across multi-turn interactions. We construct controlled conversations in several risk-related domains and introduce structured forms of contextual pressure that increase decision difficulty without altering the underlying user intent. Model responses are annotated at the turn level using a fine-grained decision taxonomy, which makes it possible to pinpoint the moments when safety boundaries begin to erode. To separate true multi-turn drift from simple content sensitivity, we include fixed baselines and exclude baseline failures from conditional drift analysis. We report metrics such as Overall Harm Rate, Conditional Drift Rate, and the timing of critical failures, alongside interpretable failure traces.
By centering on decision robustness after risk is already present, this benchmark reveals safety breakdowns that single-turn evaluations often miss. It offers a transparent and auditable way to understand how conversational pressure accumulates over time and underscores the need for safety evaluation methods that better reflect real-world deployment, where high-risk interactions are extended, contextual, and dynamic.


Log in or sign up for Devpost to join the conversation.