-
-
Page overview
-
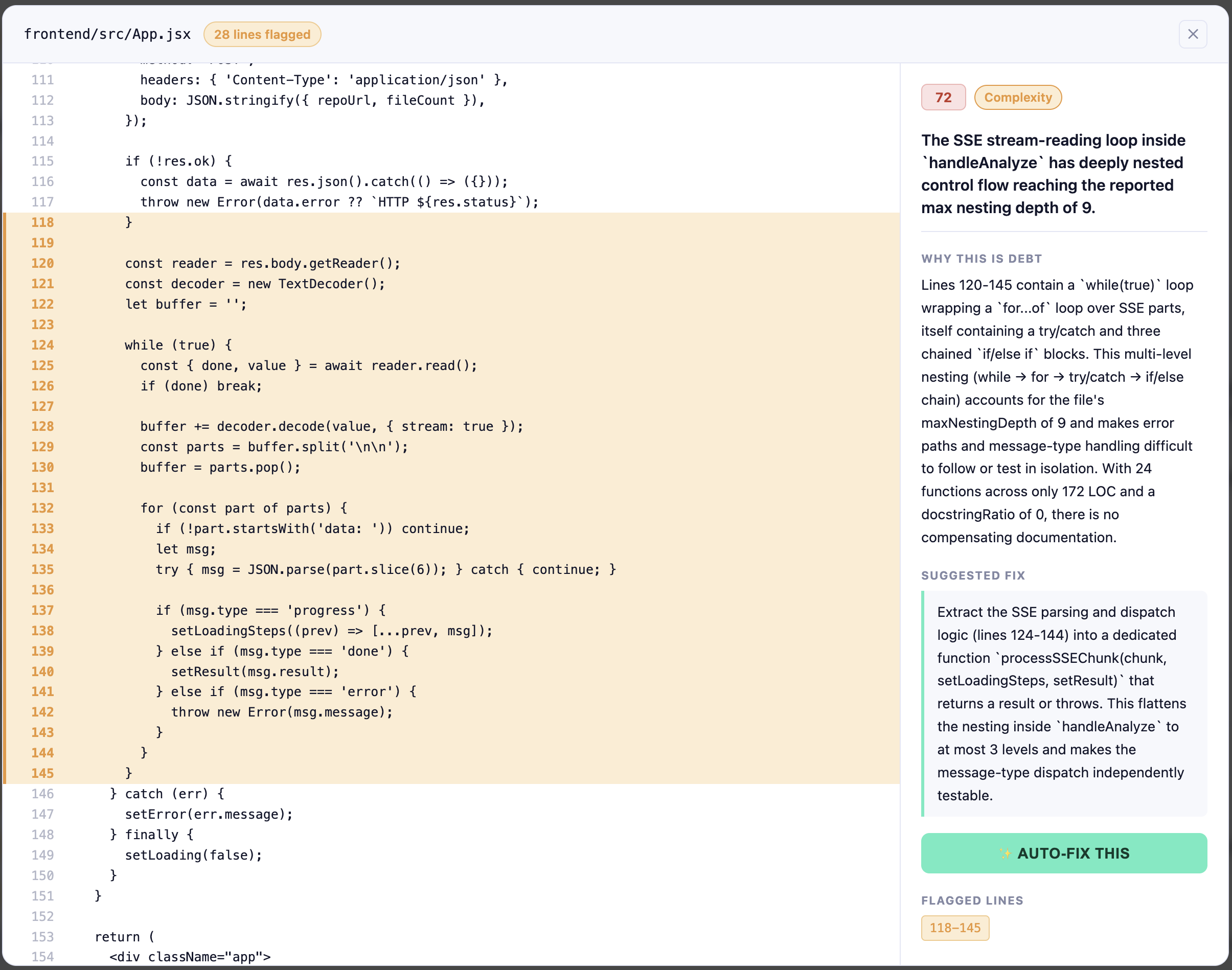
Inspecting a specific debt
-
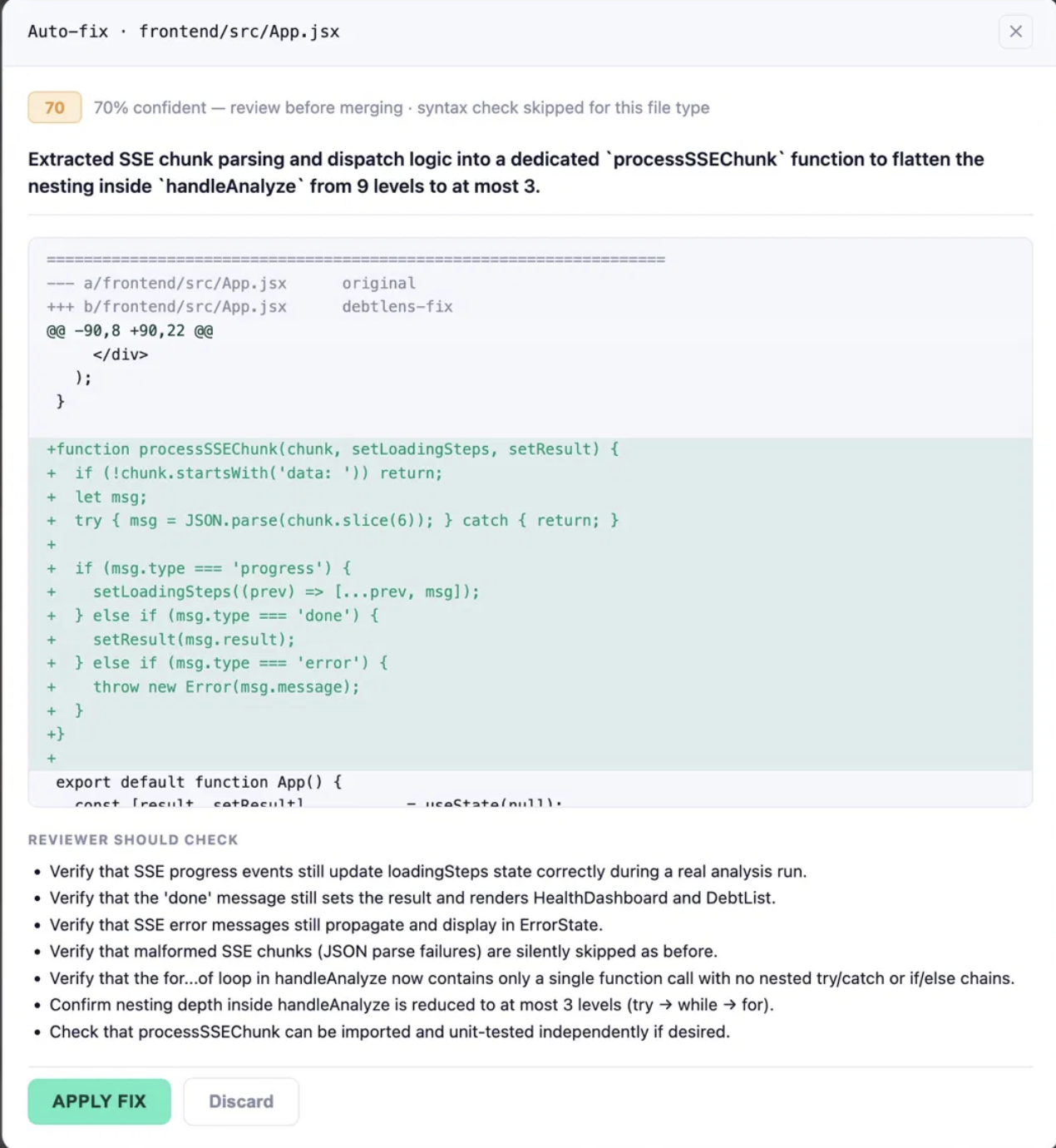
Applying the auto fix
Inspiration
Every engineer has inherited a codebase they didn't write. You open a file, it's 400 lines long, there are no tests, the last dependency update was two years ago, and there's a TODO from 2021 that says "fix this later."
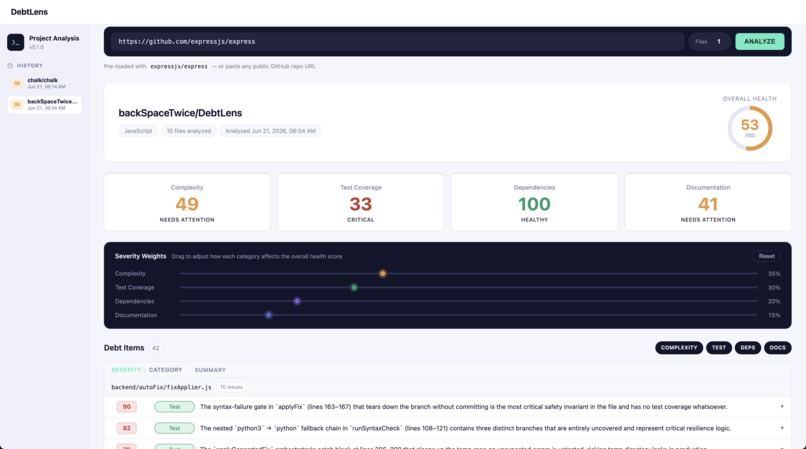
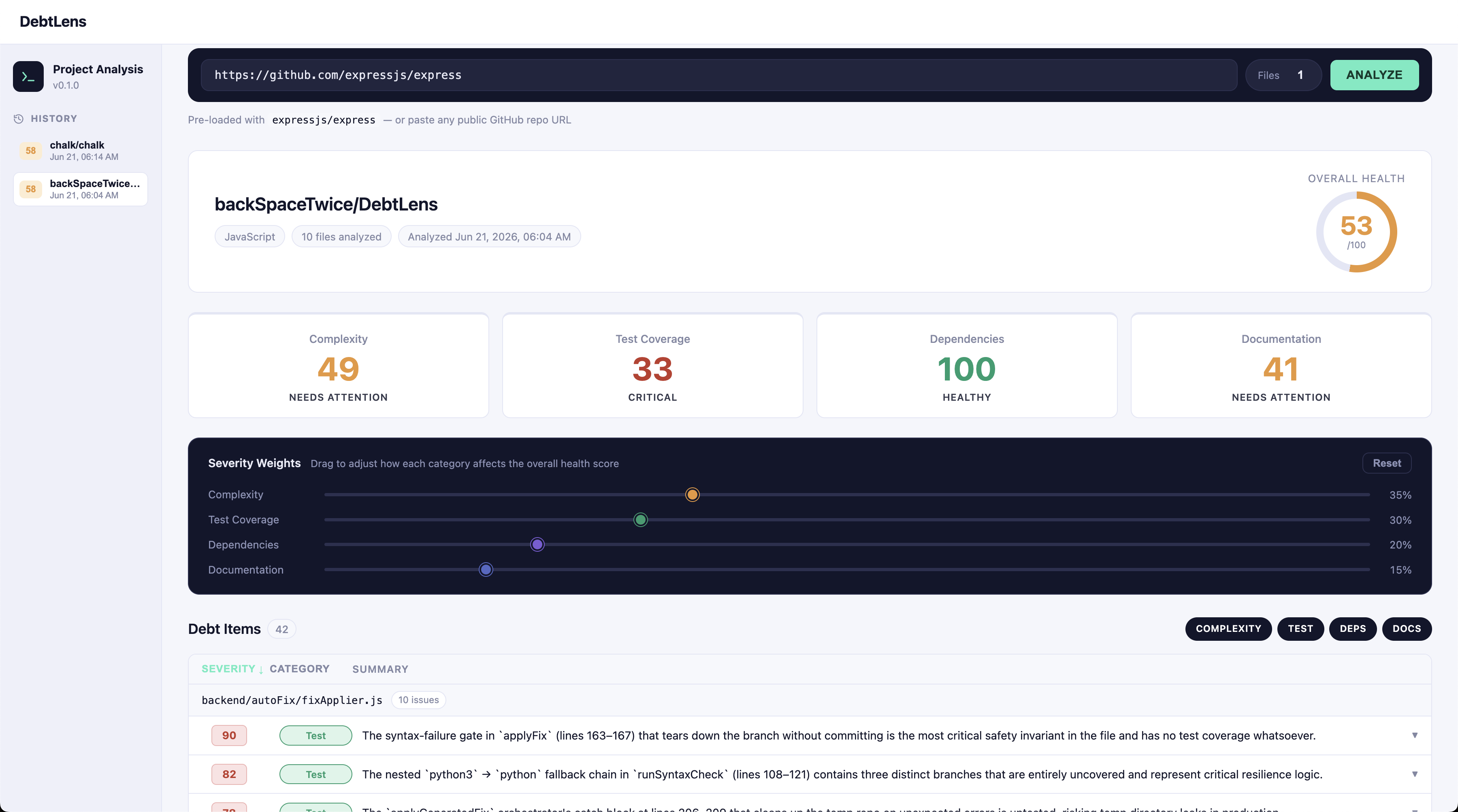
The challenge isn't finding problems. It's knowing which ones matter most, why they matter, and how to fix them. We built DebtLens to do all three.
What it does
The biggest lesson was the difference between decorating with math and building with math. We don't send raw files to Claude and ask "find debt." We compute real static signals first:
severity = 0.35 * C + 0.30 * T + 0.20 * D + 0.15 * Doc
The LLM reasons on top of those signals, not instead of them. Every finding is grounded in specific line numbers you can verify. We also learned that scope discipline is a feature — cutting from seven node types to four debt categories gave us the time to build auto-fix properly instead of shipping seven shallow things.
How we built it
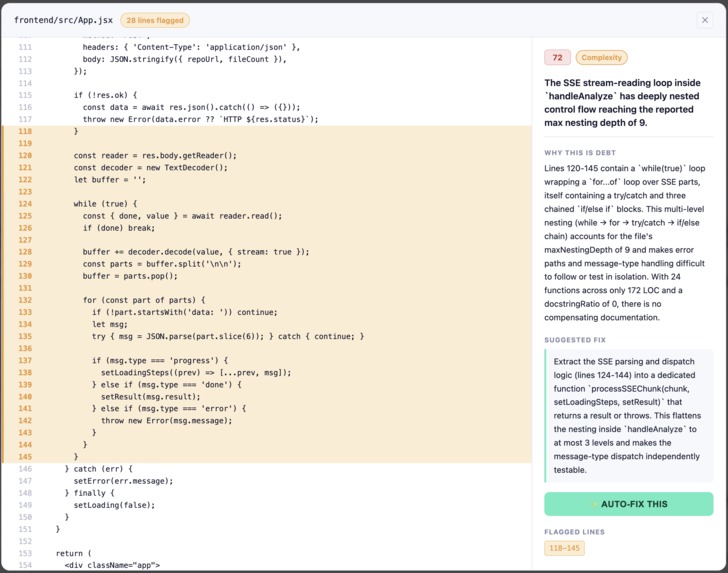
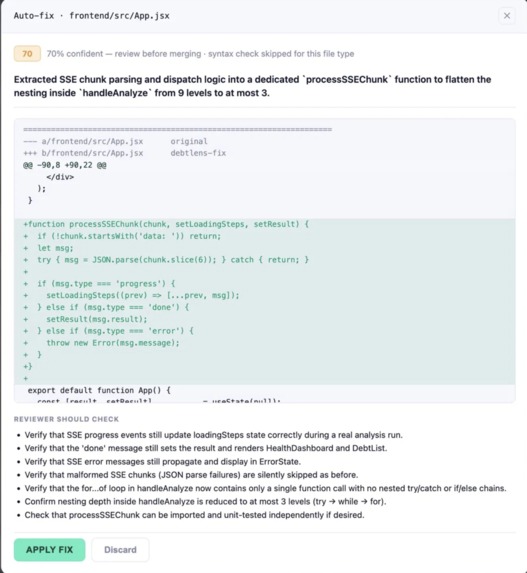
Three layers, each independently verifiable: Static Analysis — the backend computes raw metrics per file (nesting depth, LOC, test file existence, dependency age) before touching the LLM. The LLM gets structured signals, not raw source. Schema-Constrained Extraction — Claude must cite specific line numbers to report a finding, or return nothing. Line references are validated server-side. No hallucinated findings reach the UI. Auto-Fix Pipeline — a second LLM call generates a complete file rewrite with a self-reported confidence score. Two gates run before the user sees anything: a confidence floor ( < 65\% ) drops the fix, and a syntax check (node --check, py_compile) deletes the branch on failure. On Apply, the branch pushes to GitHub and opens a pre-filled PR. On Discard, the temp directory is deleted entirely.
Challenges we ran into
JSON compliance. Claude occasionally responded to the auto-fix prompt with prose instead of JSON. Fix: strengthened system prompt plus a resilient parser that extracts the first & to last } as a fallback before throwing. Scratch repo isolation. DebtLens never has a full clone — only file content from the API. We build a scratch git repo containing just the file under fix, apply the rewrite, run the syntax gate, and push only that branch to GitHub on Apply. ESM syntax checking. node --check on ESM files in a bare scratch repo fails because Node defaults to CommonJS. Fix: inject a minimal {"type": "module" } package.json into the scratch repo before checking. Prompt specificity. Generic suggestions produce useless auto-fixes. We treated extraction quality as a hard gate - no auto-fix pipeline until every refactorSuggestion referenced exact line numbers and function names specific enough to act on without clarification.
Accomplishments that we're proud of
The auto-fix pipeline working end to end on a real repo — branch isolation, confidence floor, syntax gate, and GitHub PR in one flow. That's not a demo feature, that's a production-grade safety architecture built in a hackathon timeline.Getting the LLM to reason on top of static signals rather than replacing them. Every finding cites real line numbers validated server-side. No hallucinated debt items reach the UI.Treating extraction quality as a hard gate before building auto-fix. We didn't start Step 9 until every suggestion was specific enough to act on without clarification. That discipline is why the auto-fix produces meaningful diffs instead of noise.
What we learned
Scope discipline is a feature. Cutting from seven node types to four debt categories gave us the time to build each one with real depth — and enough runway for auto-fix. The difference between decorating with math and building with math. A severity formula means nothing if the inputs aren't grounded in real computed metrics. We built the static analysis pass first precisely so the LLM had something concrete to reason about. Prompt compliance is an engineering problem, not a prompt problem. When Claude returned prose instead of JSON, the fix wasn't just a better prompt — it was a resilient parser that extracts { to } as a fallback. Robust systems don't rely on perfect model behavior.
What's next for DebtLens
Model flexibility. Engineers should be able to bring their own model — Claude, GPT-4o, Gemini, or a self-hosted Llama variant for teams with strict data privacy requirements. The LLM call is already isolated to a single module, so swapping the provider is an interface change, not an architectural one. A settings panel would let users paste in their own API key and select their preferred model without touching the codebase. Private repo support via GitHub OAuth, so teams can scan their actual production codebases rather than only public repos. IDE integration — a VS Code extension that surfaces debt items inline as you edit, rather than requiring a separate analysis run. Trend tracking — re-scan a repo over time and show whether the health score is improving or degrading sprint over sprint. Debt that's growing is more urgent than debt that's stable. Team dashboards — aggregate scores across multiple repos so engineering leads can see which codebases need the most attention at a glance.

Log in or sign up for Devpost to join the conversation.