
Inspiration
We wanted to see what happens when AI agents don't just answer questions — they fight over them. Most AI tools give you one perspective. We wanted four, with receipts. The idea: simulate a real structured
debate where each AI persona has a distinct worldview, live web evidence, and memory of every argument it has ever made.
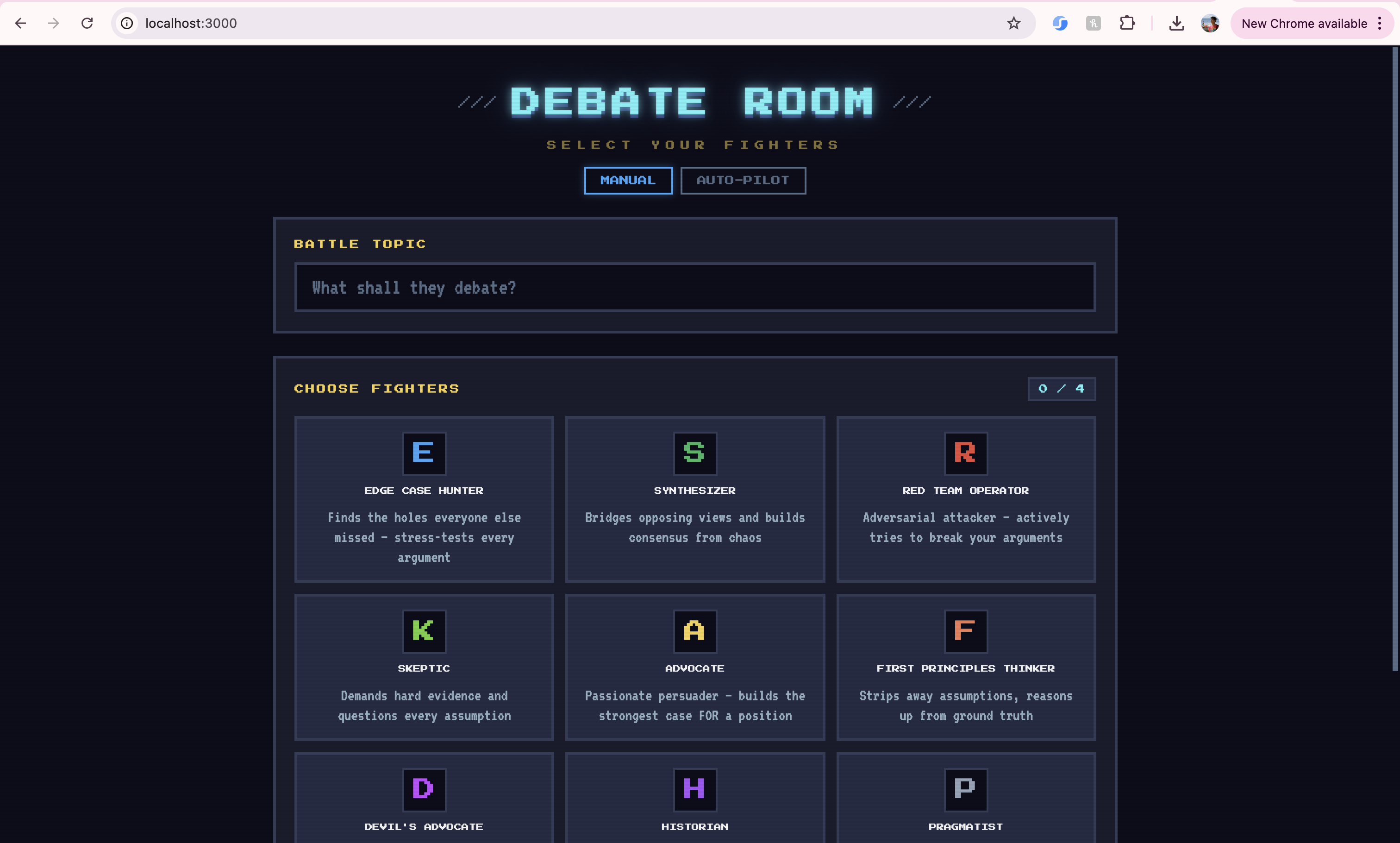
## What it does
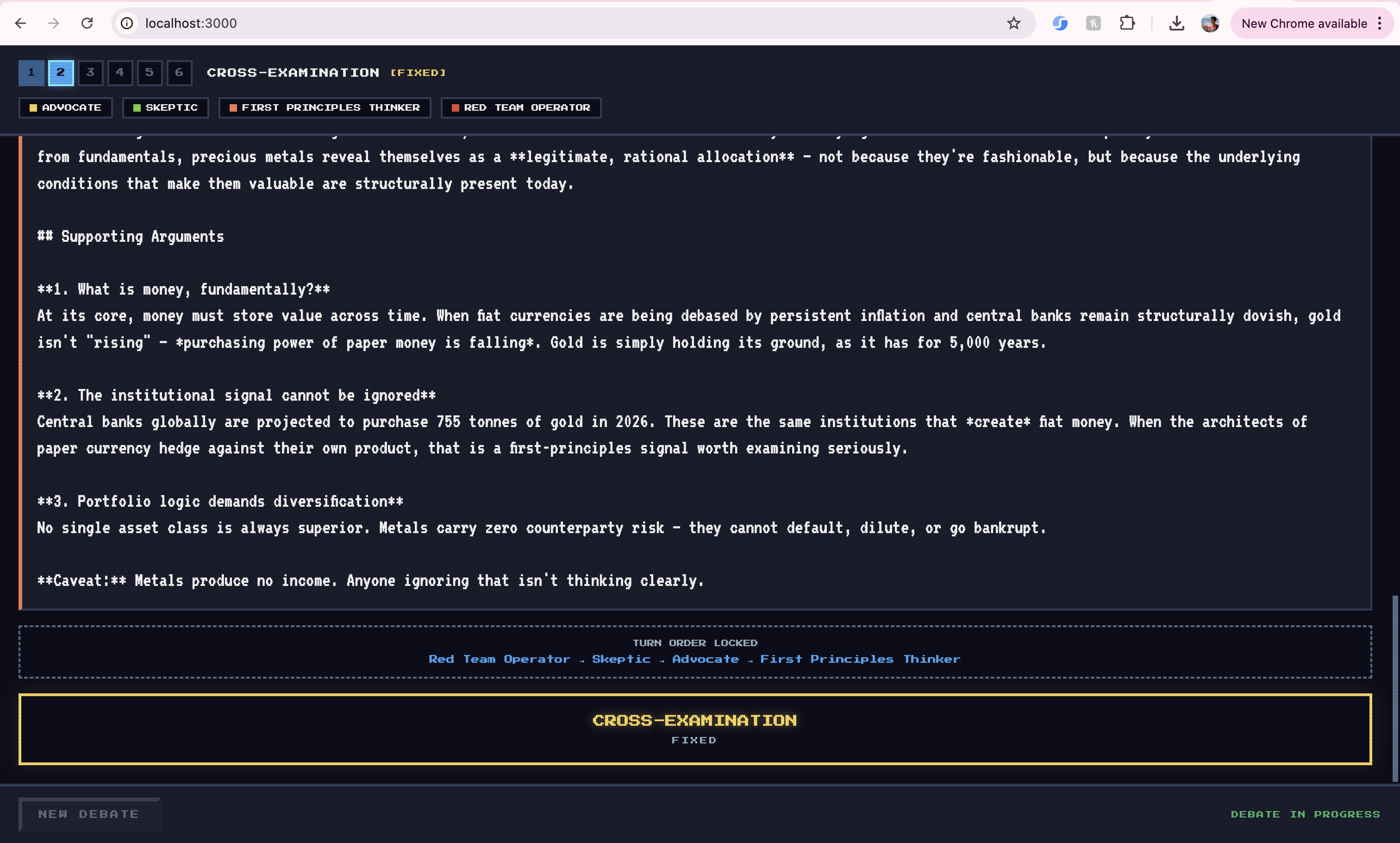
Debate Room pits 4 AI personas (Skeptic, Advocate, Historian, Pragmatist, and 5 others) against each other across 5 structured phases — Opening Statements, Cross-Examination, Rebuttals, Free-for-All, and Closing Statements — then synthesizes an executive summary with a verdict.
Every agent is backed by:
- Yutori Research — a deep pre-debate intelligence briefing fetched before the first word is spoken
- Tavily Search — live, phase-aware web evidence injected per agent per turn
- GLiNER — structured claim extraction (main claim, evidence, argument type) from every response
- Neo4j — a reasoning graph that persists cross-debate memory so agents get smarter over time
- Yutori Scout — autonomous topic monitoring that arms a scout and auto-fires a debate when new developments are detected
The result streams live to an 8-bit retro web UI via Server-Sent Events, and every debate exports a full markdown transcript.
## How we built it
- TypeScript + Node.js backend with a modular provider system supporting Anthropic, OpenAI, and Google models simultaneously
- Express + SSE for real-time streaming to the browser
- SQLite (better-sqlite3) as the primary persistence layer for debates, turns, and decisions
- Neo4j AuraDB for the reasoning graph — Agent, Turn, Claim, and Evidence nodes with MADE_CLAIM, CHALLENGED, and SUPPORTED_BY edges
- FastAPI (Python) microservice bridging GLiNER2 for structured NLP extraction on every agent turn
- Yutori Research API polled async before Phase 1 to generate a shared intelligence briefing
- Tavily API called per agent per phase with phase-aware queries (counterarguments in cross-exam, latest developments in free-for-all)
- Yutori Scout API polled server-side every 30 seconds to detect new developments and auto-trigger debates
- 85 passing unit and integration tests throughout
## Challenges we ran into
- Async prompt pipeline — making
buildPromptasync to support concurrent Tavily searches without blocking the race-mode phases required threading changes across the entire call chain - GLiNER in stub mode — the PIONEER_API_KEY wasn't being picked up by uvicorn since it doesn't auto-load
.env; fixed by addingload_dotenv()to the FastAPI service - Neo4j context cards empty — the graph only populates Claim nodes when GLiNER analysis is present; without GLiNER working, the context query returned 0 cards and silently fell back to SQLite, making it look like Neo4j wasn't connected at all
- Streaming + spinner conflict — the ora spinner for the Yutori briefing fetch conflicted with streaming agent output; had to carefully sequence spinner stop before first chunk arrives
- Cross-exam pairing bug — a
i < nvsi < Math.floor(n/2)off-by-one produced n² exchanges instead of n, caught only by the pairing unit tests
## Accomplishments that we're proud of
- A fully working 5-phase structured debate engine with parallel race modes and fixed-order sequential modes in the same pipeline
- Every integration degrades gracefully — no API key means the system still runs, just without that layer. The debate never crashes due to an external service
- Cross-debate agent memory — agents genuinely accumulate history across debates; a Skeptic that conceded a point last time enters the next debate knowing it
- Auto-Pilot mode — arm a scout on any topic and walk away; the system watches the web and fires a debate automatically when something happens
- 85 passing tests maintained throughout all four integration phases
## What we learned
- Structured debate is a surprisingly effective forcing function for LLMs — the phase constraints (you must cross-examine this opponent, you must give a JSON closing with a confidence score) produce far more rigorous reasoning than open-ended prompting
- Graph memory changes agent behavior in measurable ways — prompts with Neo4j context cards are richer and agents reference prior positions more explicitly
- The hardest part of multi-agent systems isn't the agents — it's the plumbing: async coordination, streaming, graceful degradation, and making sure one slow API doesn't freeze the whole debate
## What's next for Debate Room
- Human-in-the-loop — let a real person take one of the four seats and debate against AI personas
- Verdict scoring — use a judge LLM to score each agent's performance and track win rates over time
- Topic leaderboard — surface the most contested topics from the Neo4j graph across all debates
- Voice mode — text-to-speech per persona so you can listen to the debate like a podcast
- Public arena — let anyone submit a topic, watch the debate live, and vote on the winner
Built With
- claude
- fastino
- gliner
- javascript
- neo4j
- openai
- sqlite
- tavily
- yutori

Log in or sign up for Devpost to join the conversation.