-
-
LightTheme
-
DarkTheme
-
LandingPage
-
NovaDD Dashboard P1
-
NovaDD Dashboard P2
-
NovaDD Dashboard P3
-
NovaDD Dashboard P4
The Story Behind NovaDD
I work in consulting. That means I've sat through enough M&A due diligence cycles to know exactly how painful they are. Weeks of analysts grinding through data rooms, cross-referencing financial statements, flagging contract clauses, chasing compliance gaps. All of it manual, all of it slow, all of it expensive. At some point I just thought - this is exactly the kind of structured, document-heavy reasoning that a sufficiently capable LLM should be able to handle. So when the Amazon Nova Hackathon dropped, I had my idea within about 10 minutes.
What We Built
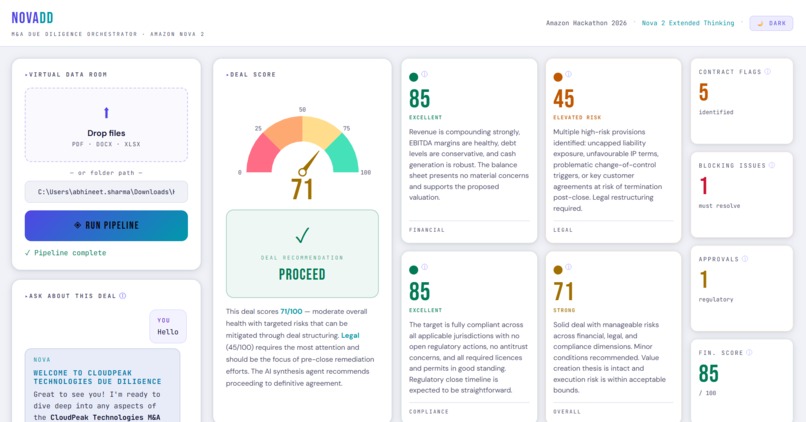
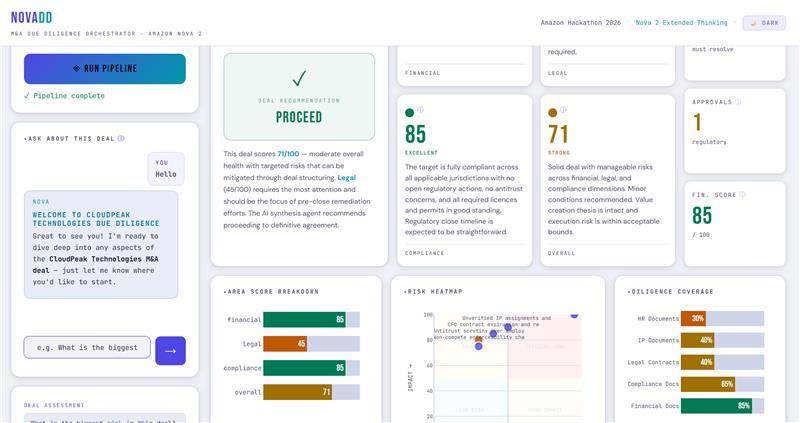
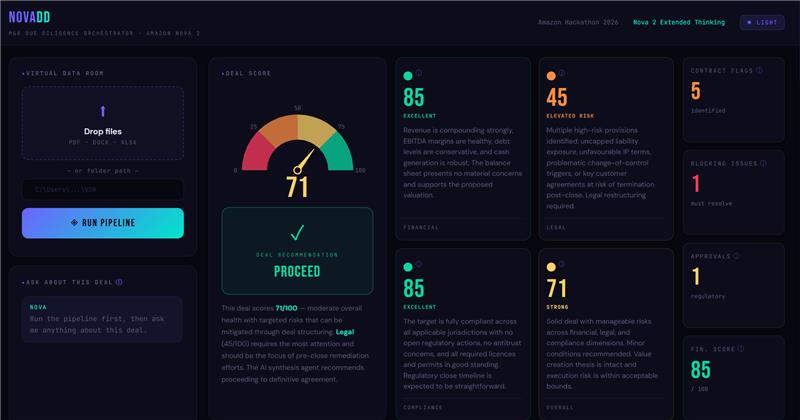
NovaDD is a full-stack M&A due diligence orchestrator. You drop in a Virtual Data Room and a 4-agent LangGraph pipeline powered by Amazon Nova 2 Lite with Extended Thinking tears through it across three parallel workstreams:
- Financial Analysis
- Contract Red Flags
- Compliance Issues
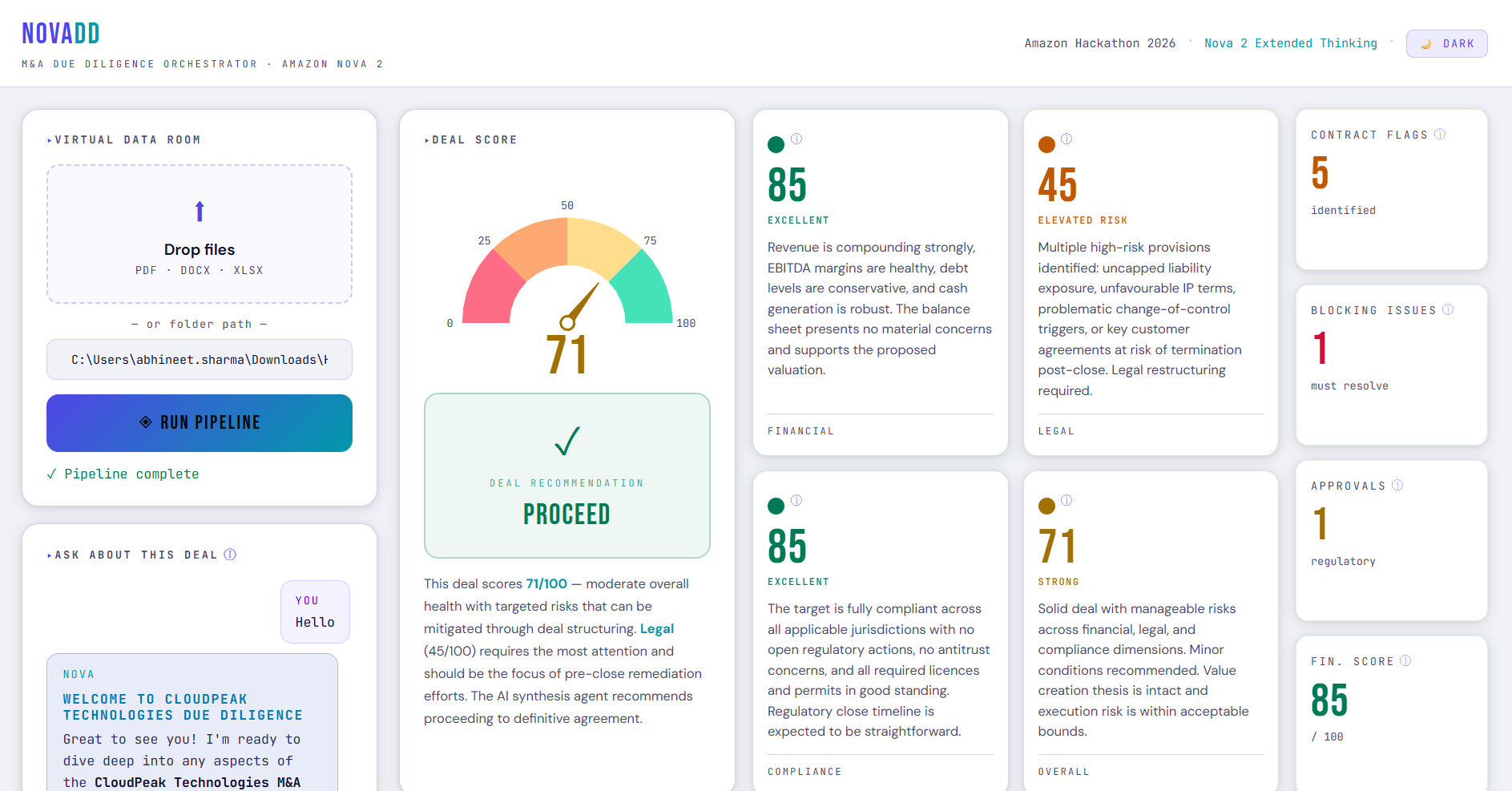
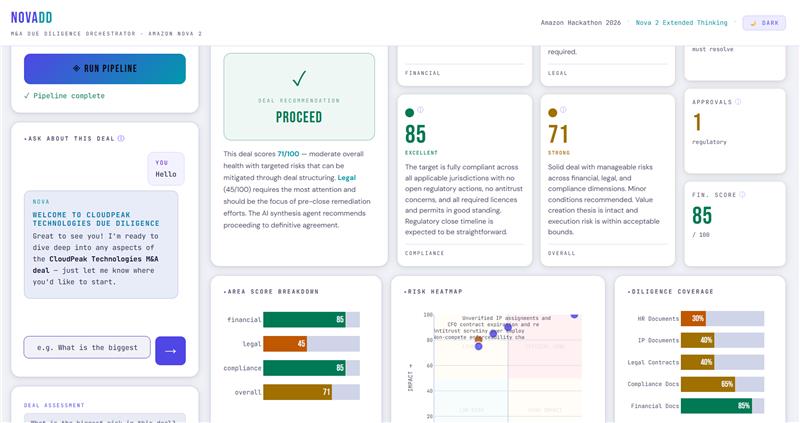
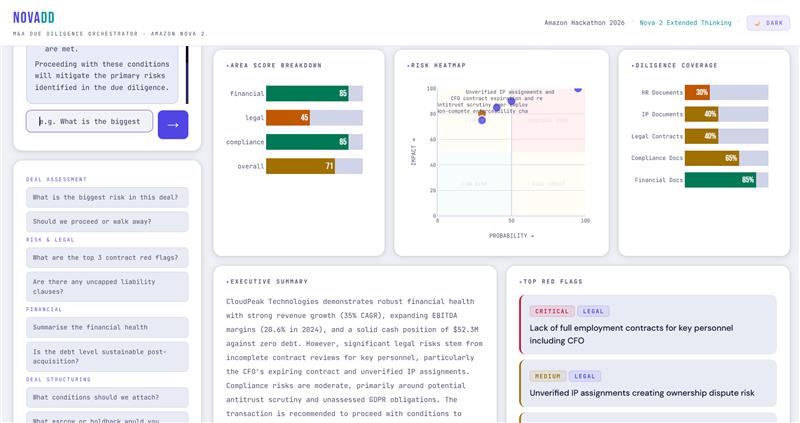
A synthesis agent then collapses everything into a weighted deal score, a risk matrix, and a go/no-go recommendation.
The deal score is computed as:
$$S = (0.40 \times F) + (0.35 \times L) + (0.25 \times C)$$
where F is the Financial score, L is the Legal score, and C is the Compliance score, each on a scale of 0 to 100.
The recommendation thresholds are deterministic:
| Score | Recommendation |
|---|---|
| S ≥ 70 | Proceed |
| 45 ≤ S < 70 | Proceed with Conditions |
| S < 45 | Do Not Proceed |
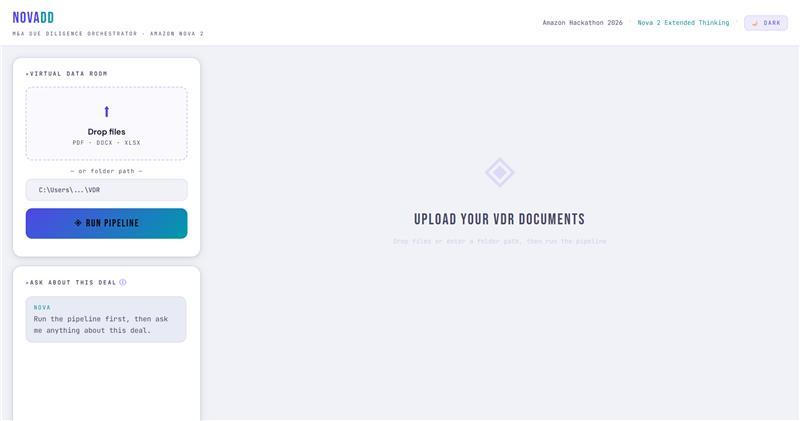
Beyond the pipeline output, NovaDD includes NOVA - a context-aware conversational interface built on top of the diligence report. Once the pipeline completes, you can ask NOVA anything about the deal in plain English:
- "What's the biggest legal risk here?"
- "Should I proceed given the CFO situation?"
- "Summarize the compliance exposure."
NOVA has the full diligence report in context and responds with grounded, structured analysis - not generic chatbot output. For a dealmaker who needs to brief a partner or prepare for a negotiation, this is where NovaDD goes from a report generator to an actual thinking tool.
How We Built It
- Backend: FastAPI with Pydantic v2 models
- Pipeline: LangGraph with 4 specialized nodes
- Frontend: Dash with Plotly
- Cache: ChromaDB
- AI: Amazon Bedrock with Extended Thinking enabled on every node
I handled the core architecture and pipeline. Yana ran validation testing across different document sets to stress-test the output quality. Ishan handled model testing and tuning. Jagrit worked on the UI and frontend experience.
Workflow
1. Document Ingestion
- User uploads PDF / DOCX / XLSX files or provides a local folder path
- Extractor pulls raw text using PyMuPDF, python-docx, openpyxl
- Text is truncated to 40,000 characters
- SHA-256 hash is computed as the doc_id
doc_id = hashlib.sha256(document_text.encode()).hexdigest()
2. Cache Check
- doc_id is looked up in ChromaDB
- Cache hit - return stored DiligenceResult instantly
- Cache miss - proceed to pipeline
3. Pipeline Execution (LangGraph)
Node 1 - Financial Analysis
- Input: document text
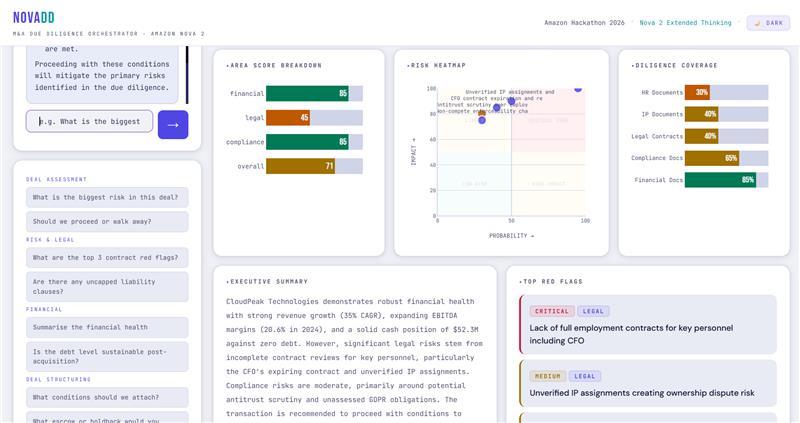
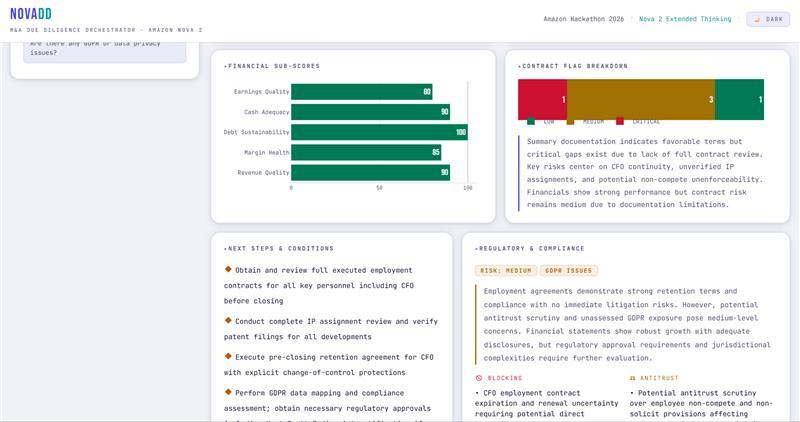
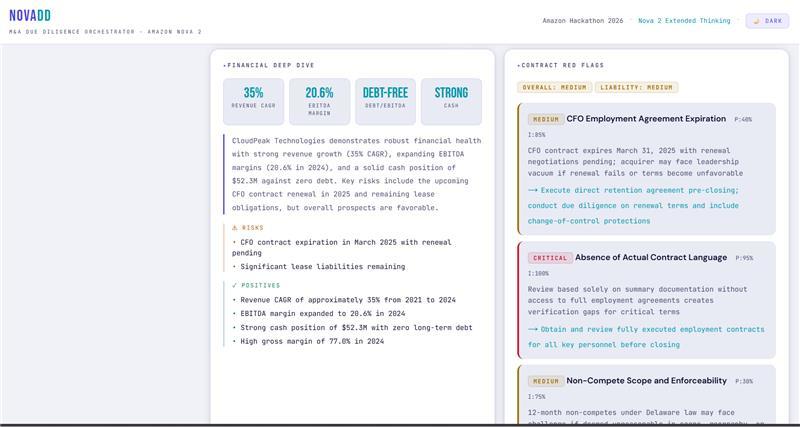
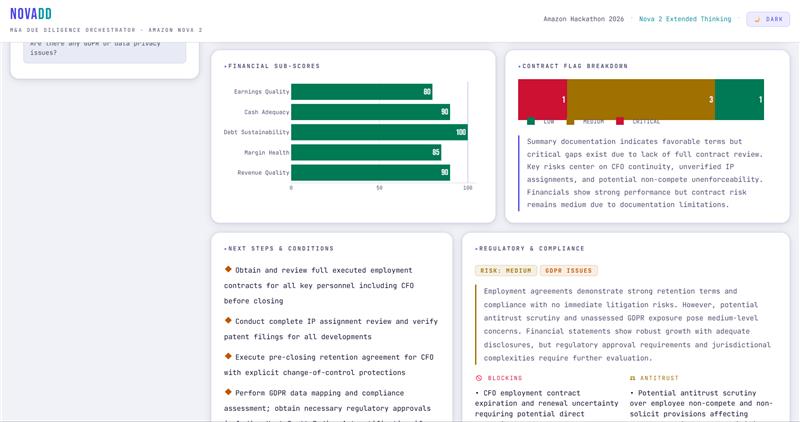
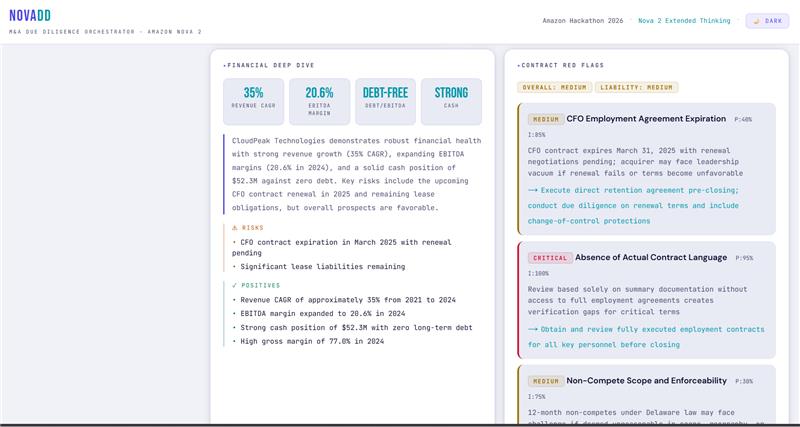
- Output: revenue trends, EBITDA margins, debt structure, cash position, financial red flags, financial score [0-100]
Node 2 - Contract Red Flags
- Input: document text
- Output: change-of-control clauses, non-competes, termination rights, IP ownership issues, legal red flags, legal score [0-100]
Node 3 - Compliance Issues
- Input: document text
- Output: regulatory exposure, antitrust flags, data privacy gaps, pending litigation, compliance score [0-100]
Node 4 - Synthesis & Scoring
- Input: outputs from Nodes 1, 2, 3
- Output: weighted deal score, risk matrix, recommendation, executive summary, conditions precedent, next steps
4. Scoring
$$S = (0.40 \times F) + (0.35 \times L) + (0.25 \times C)$$
| Score | Recommendation |
|---|---|
| S ≥ 70 | Proceed |
| 45 ≤ S < 70 | Proceed with Conditions |
| S < 45 | Do Not Proceed |
5. Result Storage
- DiligenceResult stored in ChromaDB against doc_id
- All subsequent runs with the same documents return instantly
6. NOVA Chat
- User queries the report in natural language
- Full DiligenceResult passed as context to Nova 2 Lite on every message
- Responses are grounded in the actual deal analysis
- Supports follow-up questions, summaries, negotiation prep, partner briefings
The Hardest Part
LLM Non-Determinism
Running the same document set twice could produce meaningfully different scores and risk assessments. For a due diligence tool that's supposed to inform real investment decisions, that's not acceptable. The fix was caching - a SHA-256 hash of the document content mapped to ChromaDB:
doc_id = hashlib.sha256(document_text.encode()).hexdigest()
Same documents always return the same cached result. It also cut repeat run times from 2-4 minutes down to under 1 second.
AWS Account Setup
Getting Amazon Bedrock access, enabling the Nova 2 Lite models in the right region, and sorting out permissions took longer than it should have. Not a glamorous problem but an honest one - if you're building on Bedrock for the first time, budget time for this.
What I Learned
- Extended Thinking is genuinely different. There's a noticeable quality gap between Nova 2 Lite with Extended Thinking enabled versus without. The model catches things in contracts and financial statements that a standard completion would miss. For document-heavy analytical workloads, it's worth the extra latency.
- A static report, no matter how detailed, still leaves questions on the table. The ability to ask follow-up questions in natural language - and get answers grounded in the actual document analysis rather than generic LLM knowledge - is what makes the difference between a tool people read once and a tool people actually use.
Accomplishments We're Proud Of
- Getting Extended Thinking to produce consistent, structured JSON across all 4 agents. Nova 2 Lite has a tendency to reason extensively and then output JSON that's slightly malformed - missing quotes, trailing commas, truncated fields. We integrated
json-repairas a post-processing layer on every single Bedrock response:
from json_repair import repair_json
parsed = repair_json(raw_nova_output)
- The caching system eliminated non-determinism entirely. Same documents, same result, every time. For a due diligence tool, that's not optional.
- NOVA chat being context-aware to the specific deal. It's not a generic chatbot - it has the full diligence report in context and can answer deal-specific questions with actual grounding. Ask it about the CFO retention risk, the antitrust exposure, or whether to proceed - it knows the deal because it has read the deal.
- Shipping a production-grade modular architecture within a hackathon timeframe. The codebase is structured the way you'd structure it if you were actually going to maintain and scale it.
Impact
M&A due diligence at mid-market consulting firms typically takes 3 to 6 weeks and costs anywhere from $50,000 to $200,000 in advisor fees. NovaDD compresses the initial document review layer down to minutes.
- The immediate use case is first-pass screening. Before any human analyst touches the data room, NovaDD has already surfaced the red flags, scored the deal across three dimensions, and flagged the conditions that need negotiating. That's not replacing the analyst, it's giving them a ~10x head start.
- Longer term, the same pipeline architecture applies to any domain where large volumes of structured documents need to be synthesized into a decision - loan underwriting, vendor risk assessments, regulatory audits. The document types change, the agents change, the core pattern doesn't.
Built With
- amazon-bedrock
- amazon-nova-2-lite
- amazon-web-services
- chromadb
- dash
- extended-thinking
- fastapi
- json-repair
- langgraph
- openpyxl
- plotly
- pydantic-v2
- pymupdf
- python
- python-docx


Log in or sign up for Devpost to join the conversation.