-
-
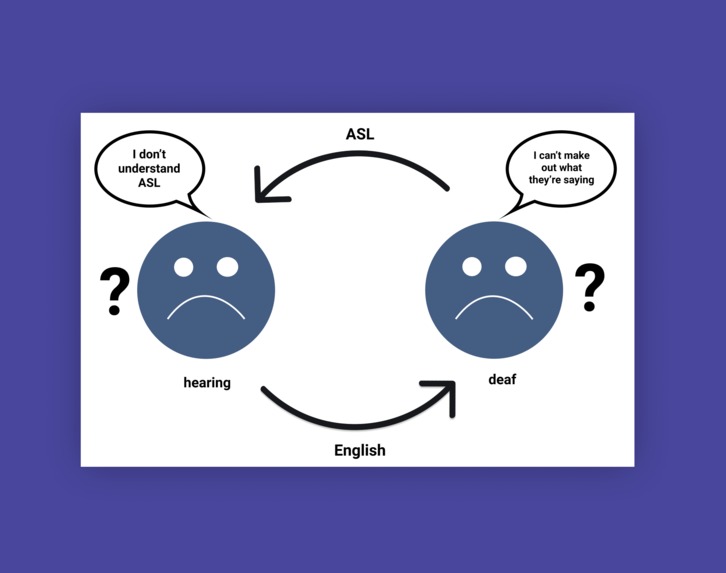
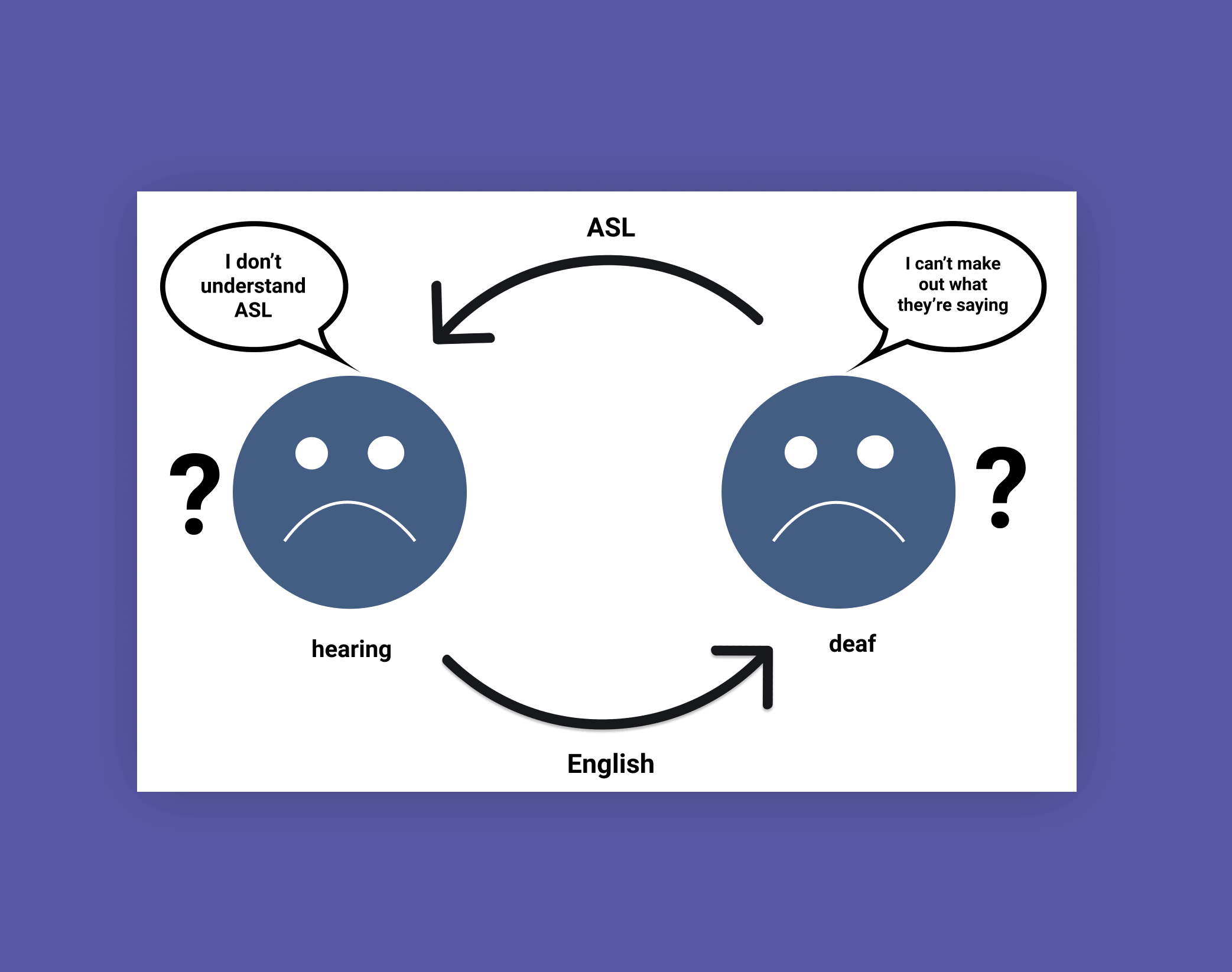
When hearing people speak to Deaf people, the communication cycle breaks down.
-

Sign in page
-
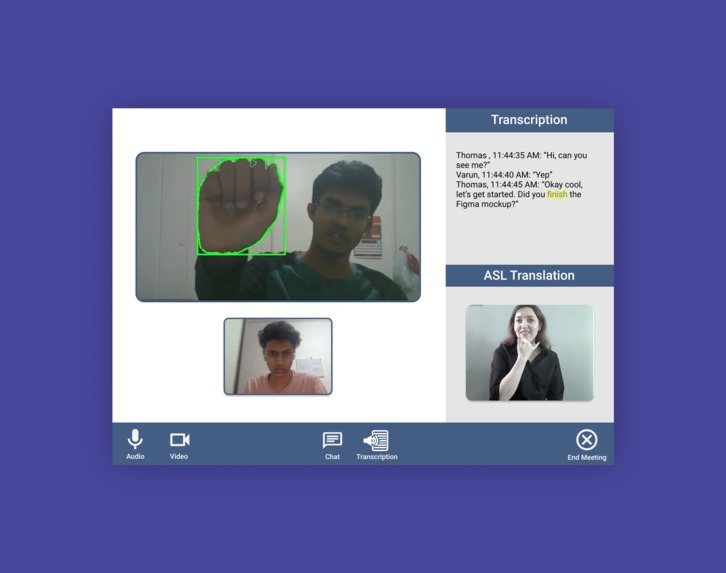
The hearing user speaks and it translates to captions. If the Deaf user doesn't understand they can highlight and receive an ASL definition.
-
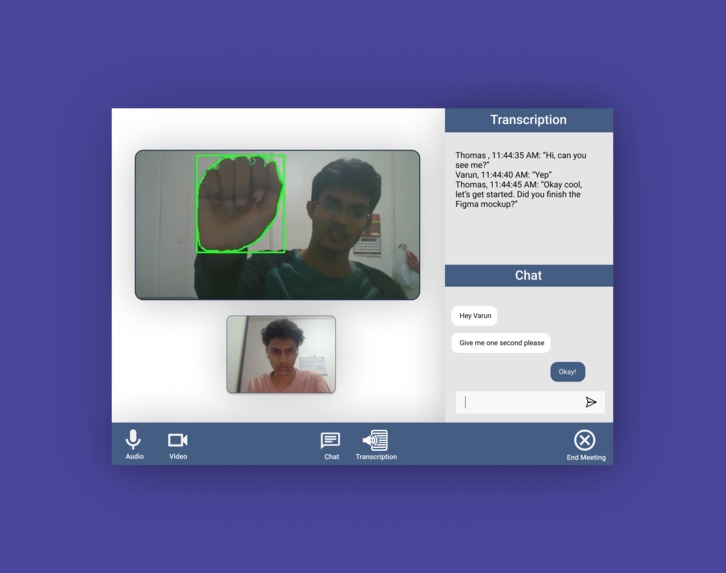
The ASL user can sign, and Computer Vision will interpret it and translate it to english captions.
-
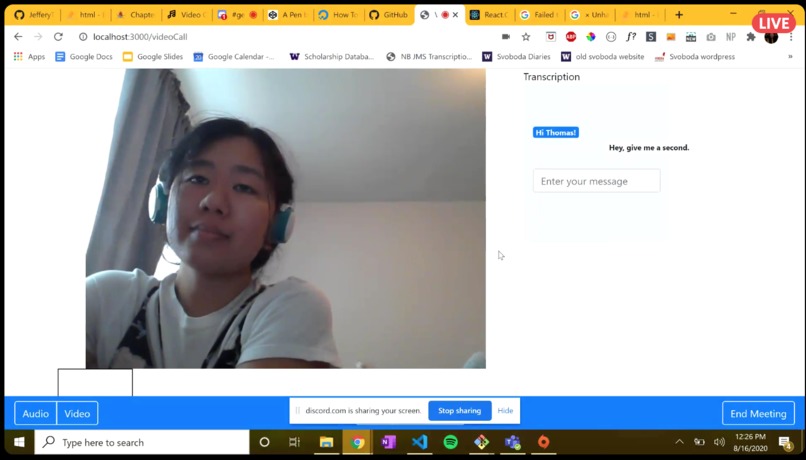
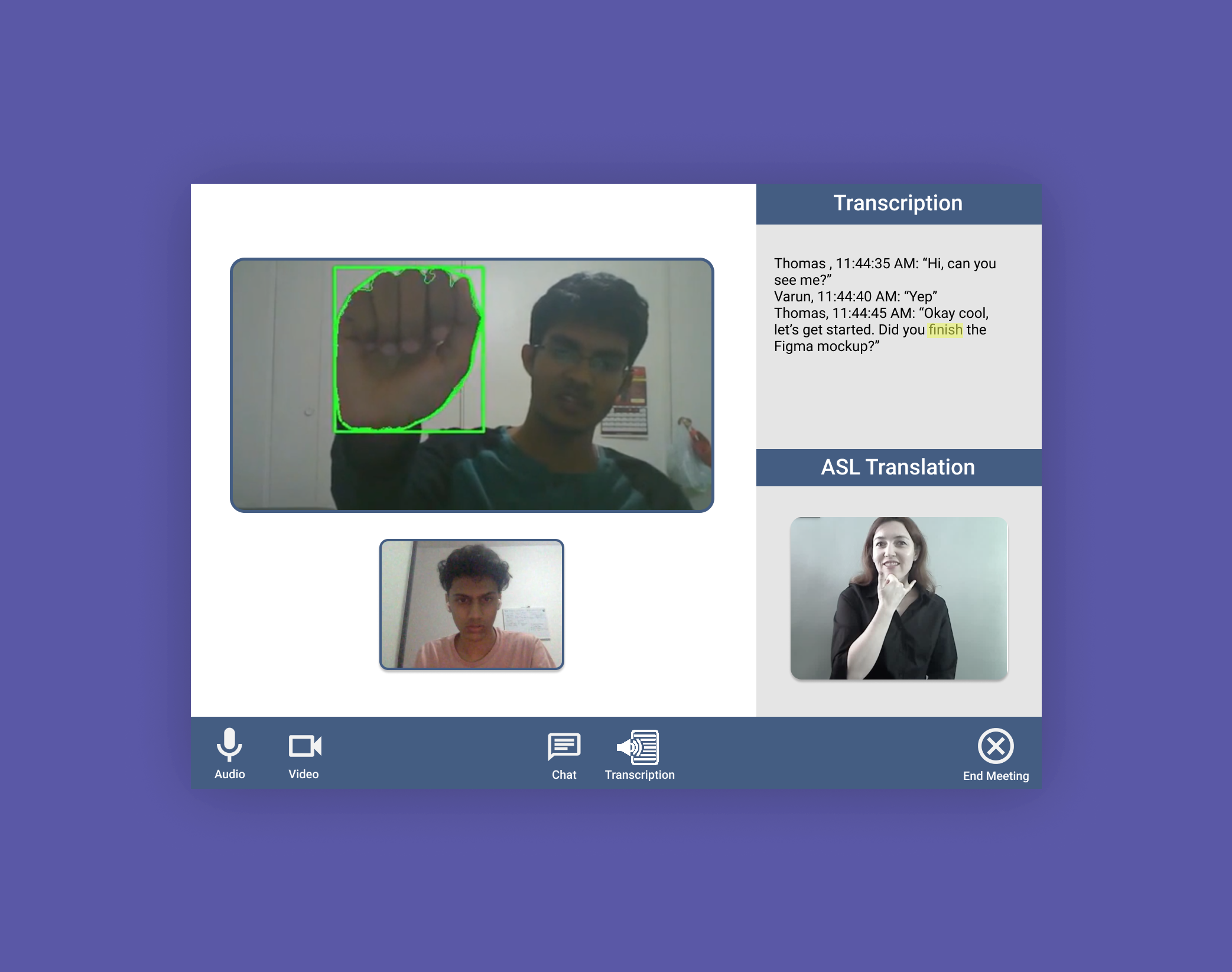
Here's our progress within 24 hours -- real time transcription, video and nav bar.



Inspiration
Video chats (such as Zoom, Google Meet, etc.) are largely English based. Users communicate through speaking. Sometimes, the speech gets captioned so those which are Deaf can understand.
We did some informal research here, here and here
What we found is that captioning services do not take into account that ASL is the native language for many Deaf Americans. Learning written languages (such as English) can occur much later and informally, so naturally, many Deaf americans prefer to receive translation in their native language (through an ASL interpreter). This means that there is a lesser chance for the Deaf user to follow what is happening.
On top of this, even if the Deaf user does understand, that doesn’t mean that they can communicate back -- if the hearing user doesn’t understand ASL, the communication between both parties begins to break down.
What it does
We specifically focused on repairing the challenges of communication between the Deaf user and the hearing user. We needed to help Deaf users understand written English and help hearing users understand ASL.
First, we designed a new type of captioning service for our Deaf users. Captioning is also known as speech to text; however, this could be thought of as speech to ASL. Taking into account that most Deaf users prefer translation through an ASL interpreter, we designed an interface where users can highlight the English text that they do not understand. Upon highlighting, the user is met with a video recording of an interpreter signing that specific word or phrase. This way, the Deaf user would be more likely to be able to follow along.
Next, we designed a new type of system to help hearing users understand ASL. Computer Vision would detect the signs being used and then translate them real time into english (think ASL to English text). This way, the Deaf user would be able to fully communicate using video.
How we built it
We decided to use React for the front end and Java & Python for the backend. A web socket API was used to connect the client to the server so data can be relayed back and forth. Unfortunately, due to time constraints we were only able to create our video chat framework (allowing 2 users to join with a unique ID) & create our captioning software using Pythons Speech Recognition library.
Due to time constraints, we weren't able to completely finish our ideal. However, after the Hackathon, we will continue to add more features. We plan to add a feature where the Deaf user would be able to highlight a specific word or phrase. When that happens, we plan to call an API to send us back a video translation in ASL that is specific to that word or phrase to help our Deaf users understand. We also plan on using YOLO Computer Vision to detect the ASL being signed to help our hearing users understand.
Challenges we ran into
One of our software developers wasn’t able to make it unexpectedly, which was unfortunate. That slowed down the back-end production a lot.
After the designers drafted up interfaces on Figma, the software developers began to move into the development phase. However, soon after the interface was drafted up and the back end was connected we ran into a constraint: Amateur Computer Vision usage isn't able to pick up on ASL to the level we need. It can only determine the alphabet. This is an obvious problem if you empathize with them; imagine trying to speak by only sounding out letters and not words. To add to the complexity; ASL has 5 parameters.
To complete our ideal project, we would need a large database of handshape, palm orientation, location, movement and facial expressions to program YOLO (to which we do not have). By this time, it was 10PM.
We dropped the Deaf video communication idea solely out of time; we wanted to create a working prototype of something. Knowing that our finished project of video calling with ASL captioning would still create a difference, we searched for ASL dictionary API’s but found none at all. Again, similar to the problem we had with our computer vision, we would have to create our own database.
Accomplishments that we're proud of
Within the time constraints, we were able to share our ideas and combine them into an innovative opportunity to redesign our online communication system. We’re proud of how hard we worked together; each person contributed in a unique way which with our different specialties -- such as React, Java and Figma. Overall, we are proud of the entire notion of our project; we know the idea will make a difference.
What we learned
Through our development, we learned how hard development on such cutting edge technologies can be.
When looking at several competitors like https://www.youtube.com/watch?v=8lwQ22yZaD8&feature=emb_title or https://www.youtube.com/watch?v=Qhg8PQjzTQI we see that the technology surrounding Computer Vision within the context of ASL is so complex and difficult, that it takes months to develop an actual working prototype.
Because of the complexities of ASL (5 parameters of ASL) it was impossible to create a dataset of deaf signs with the time limit we had. If we had a team member fluent in ASL it may have been possible.
What's next for Deaf Video Calling
We fully intend to continue development on this idea.
To fully create our ideal, we plan to begin building the ASL database which accounts for all 5 factors of ASL (handshape, palm orientation, location, movement and facial expressions). We plan on using large amounts of user research in order to achieve this.
We also plan on building our database so the user, when highlighting the English captions, can get the ASL translation. After our database gets built, we plan on expanding our caption service to other fields, perhaps live webpage translation, aside from our chat app.
There is a very large gap within our current communication system for the Deaf community and we intend to close it.


Log in or sign up for Devpost to join the conversation.