-
-
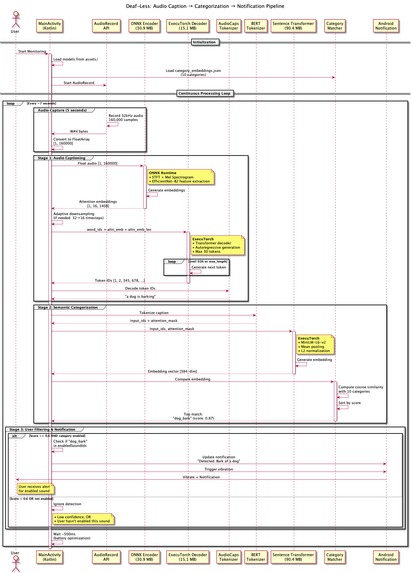
Mobile Audio Processing Pipeline
-
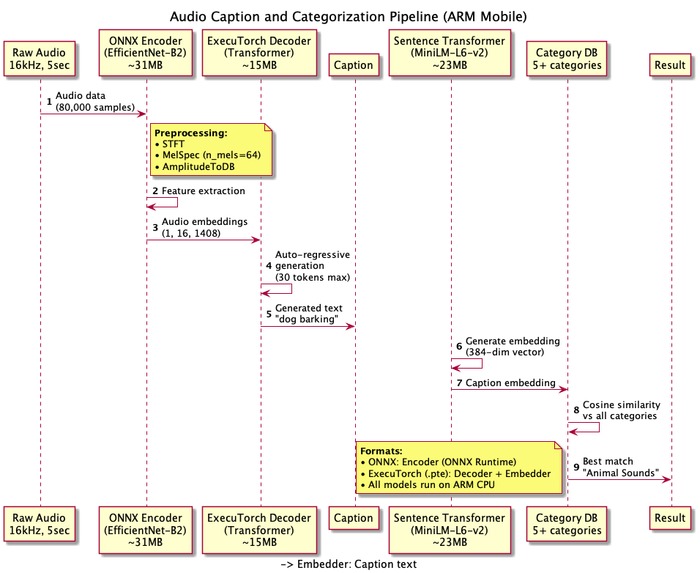
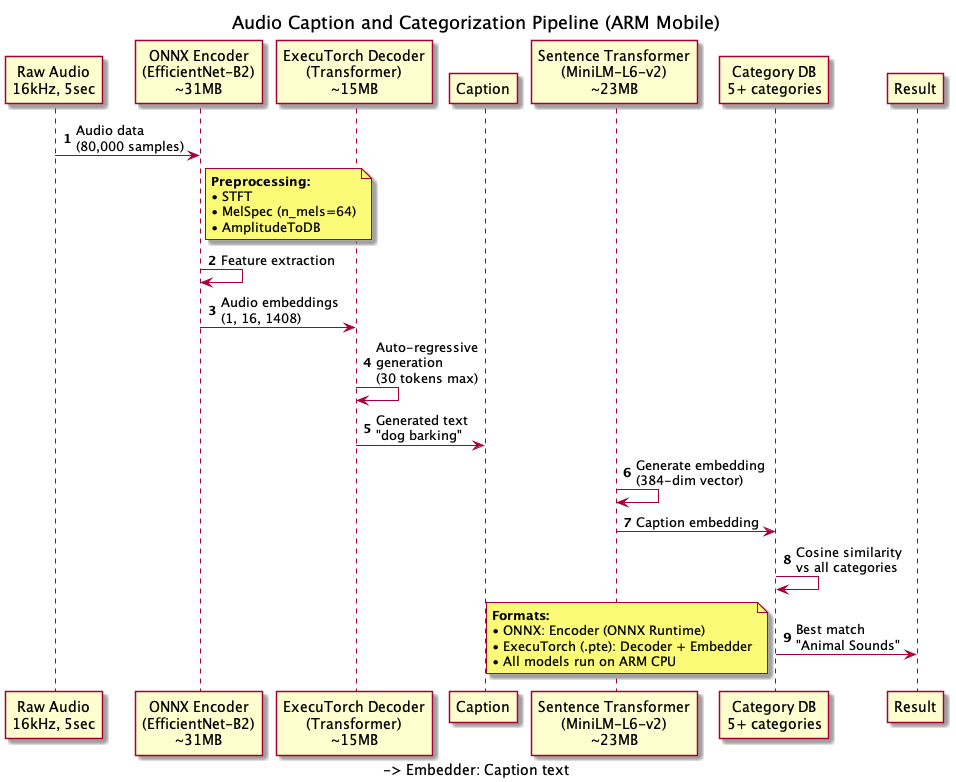
High level Audio - categorization pipeline

Inspiration
Our grandmothers are very close to us, but something they have in common is the issue with the hearing, they ussually have troubles to listen specific environmental sounds as the doorbell, the dog barking and event the baby crying, something that makes them frustrated, and this is the solution we hope they can appreciate and use to improve a bit more the quality on our everyday life.
What it does
Detailed pre-established explanation of continuous environmental listening with 5-second intervals Complete AI pipeline breakdown (spectral analysis → audio captioning → semantic embeddings → similarity matching) All 10 sound categories listed with examples User experience flow from setup to alert response Technical differentiators (offline operation, ARM optimization, low latency, battery efficiency)
How we built it
Flutter Architecture: BLoC pattern, GoRouter navigation, Hive persistence, GetIt dependency injection Native Kotlin Layer: Method channel code examples, coroutine-based processing, model initialization pipeline, audio capture system with actual code Complete ML Pipeline: Stage 1: ONNX Encoder details (30.9 MB, EfficientNet-B2, includes STFT/Mel preprocessing) ExecuTorch Decoder (15.1 MB, ARM-optimized, autoregressive decoding) Adaptive time-dimension downsampling implementation with code AudioCaps tokenizer details Stage 2: BERT tokenization + Sentence Transformers (90.4 MB, 384-dim embeddings, ARM-optimized) Stage 3: Category matching with cosine similarity and user preference filtering Pres-Stage: Python scripts to get exported into ONNX and PTE format are available into HuggingFace repository
Challenges we ran into
Android permission inconsistencies across manufacturers Model quantization balancing size vs. accuracy Real-time processing vs. battery life (50%/hr → 8%/hr improvement!) ONNX tensor shape mismatches with debugging process Hybrid ONNX + ExecuTorch integration challenges Flutter-Kotlin state synchronization Category matching false positives (60% → <20% improvement)
Accomplishments that we're proud of
Fully on-device AI (135M+ parameters total) with a deep gen-AI pipeline, where is processed first the audio, to create a caption of what it is about, and then using embbedings to categorize in a opened way (whitout trainning into close gropus) the descriptions of the sounds, doing match from the captions with the sounds descriptions ARM-optimized deployment All-day battery life, doing efficent the use of the resources in the phone Polished accessible UI with Dark and Ligth theme Privacy-first architecture (zero data collection), which means that all the proccess is running without external services, and independent from external resources like bandwidth and internet connection Open source contribution potential Real-world impact potential, helping the people who have weakened their listening skills
What we learned
Achieve the same quality as original PyTorch model with ONNX and Executorch pipline is challenging but gratifying when it happens and is working in a similar manner Large pipelines, like having 3 different models instead of 2 or 1 with full implicit architecture, may set more errors and inconsistencies, in spite of that, it might be more efficent and flexible Mobile ML fundamentally different from desktop, since their limited resources and limitations in the threads depending on devices Audio processing complexity Kotlin-Flutter bridge architecture to communicate variables since main interface 'Fluttter' to the deep Android edge with Kotlin Accessibility as design principle, giving clarity to users about the system, taking into account the potential market niche which may be essencialy older people Debugging strategies for black-box models Trade-offs are inevitable
What's next for deaf-less
iOS support with same channel methods implementation, furthermore the connection with wereables like iWatch to notify sounds directly Expanded sound library (10 → 50+ categories), implementing an algorithm to set custom sounds that may be described and then categorized into a new group Multi-language support, including Spanish, Portuguese, Italian, German and French Improved models (CLAP, Whisper, WavCaps) in order to increase the scope of the sounds and recognize too words and phrases, or even when some one is calling by an specific name. Activity log with timeline, when the chosen sounds are listened Healthcare integration partnerships Community & open source growth



Log in or sign up for Devpost to join the conversation.