

Inspiration
The idea for DeadLift was born from watching a colleague, Satish, an SDE-T at Amazon Payments, lose hours to the on-call nightmare, constantly pulled away from his actual work to manually triage SRE and DevOps issues that weren't even his responsibility. It's a story of corporate inefficiency that plays out at every large engineering org: skilled engineers reduced to manual routers for stuck messages and legacy system failures. We built DeadLift to give those hours back.
While digging into GCP, we found something even more surprising: official documentation that still recommends a human manually process certain messages instead of using automation.
In 2026, the age of agentic AI, that’s ridiculous. We shouldn't be the "glue" for broken enterprise workflows. We built this to replace manual triaging with autonomous agents, letting engineers actually focus on building.
What it does
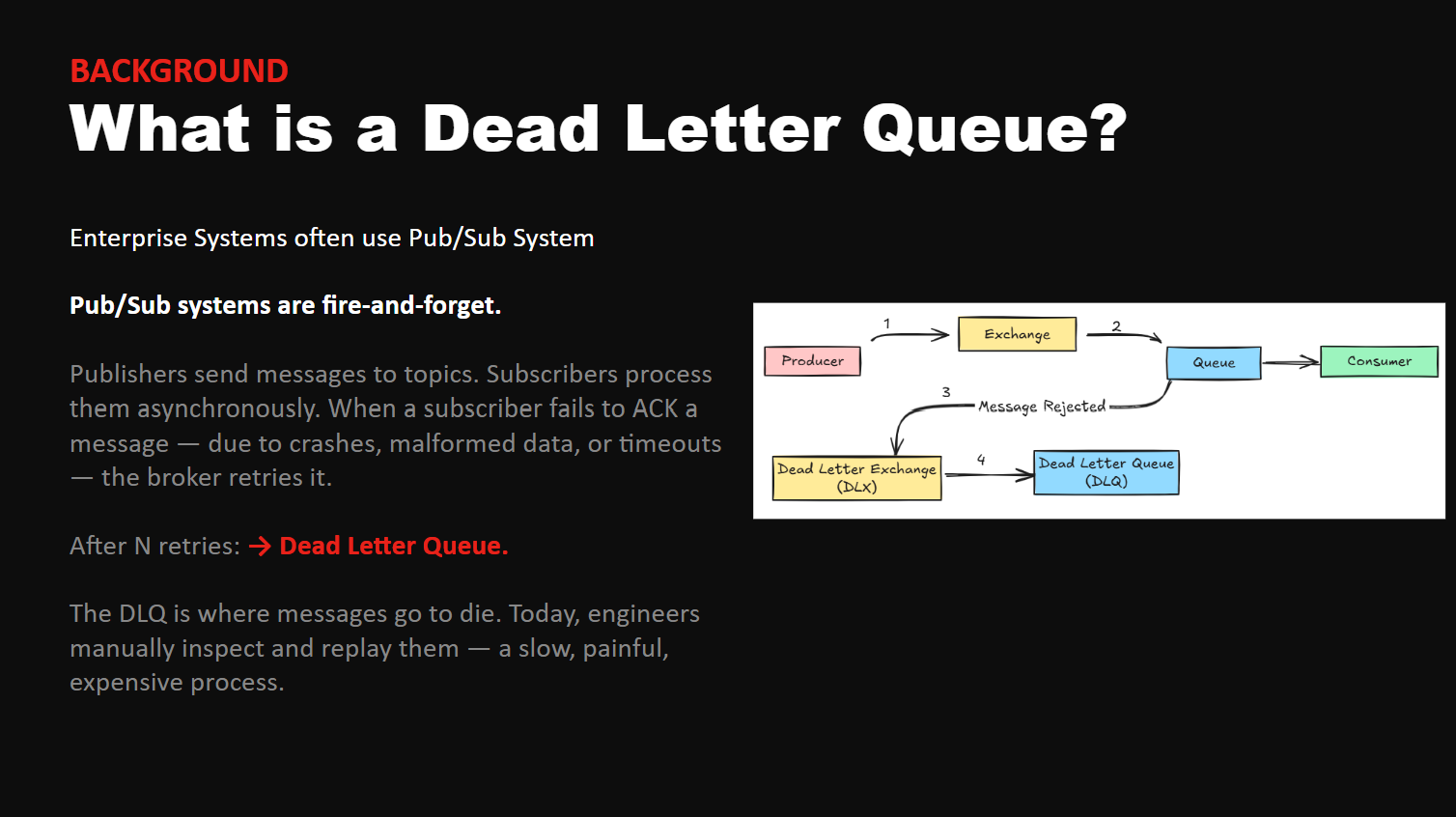
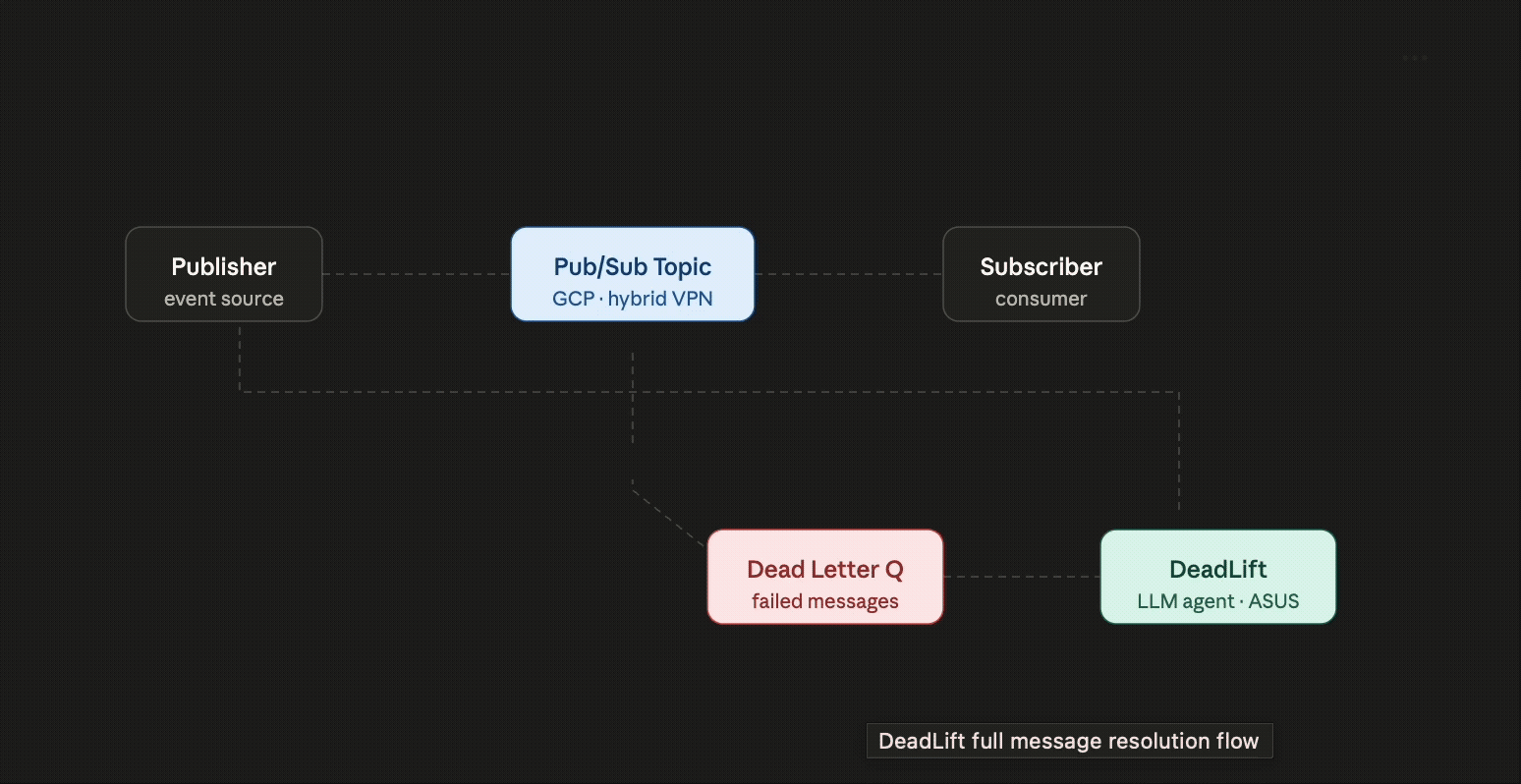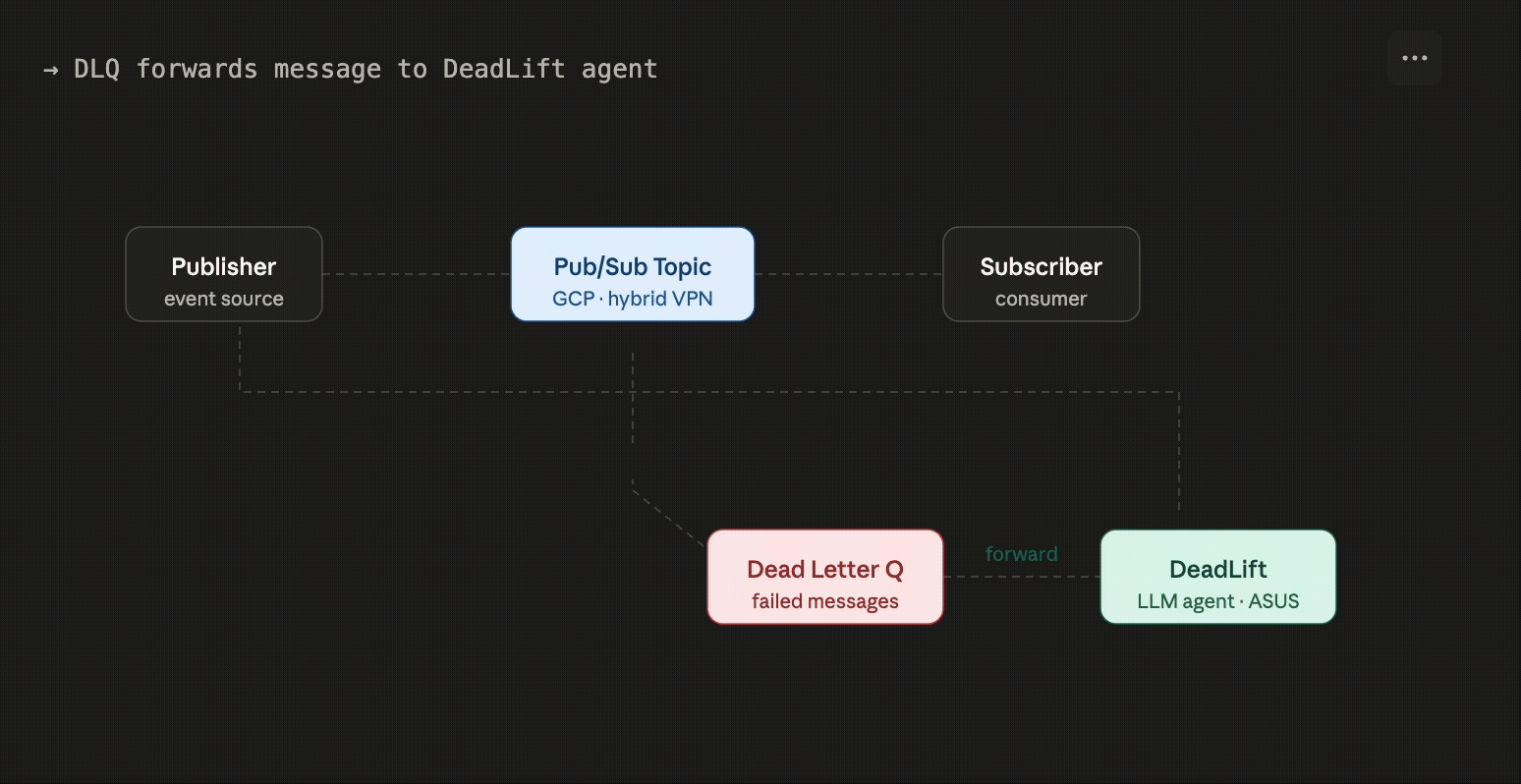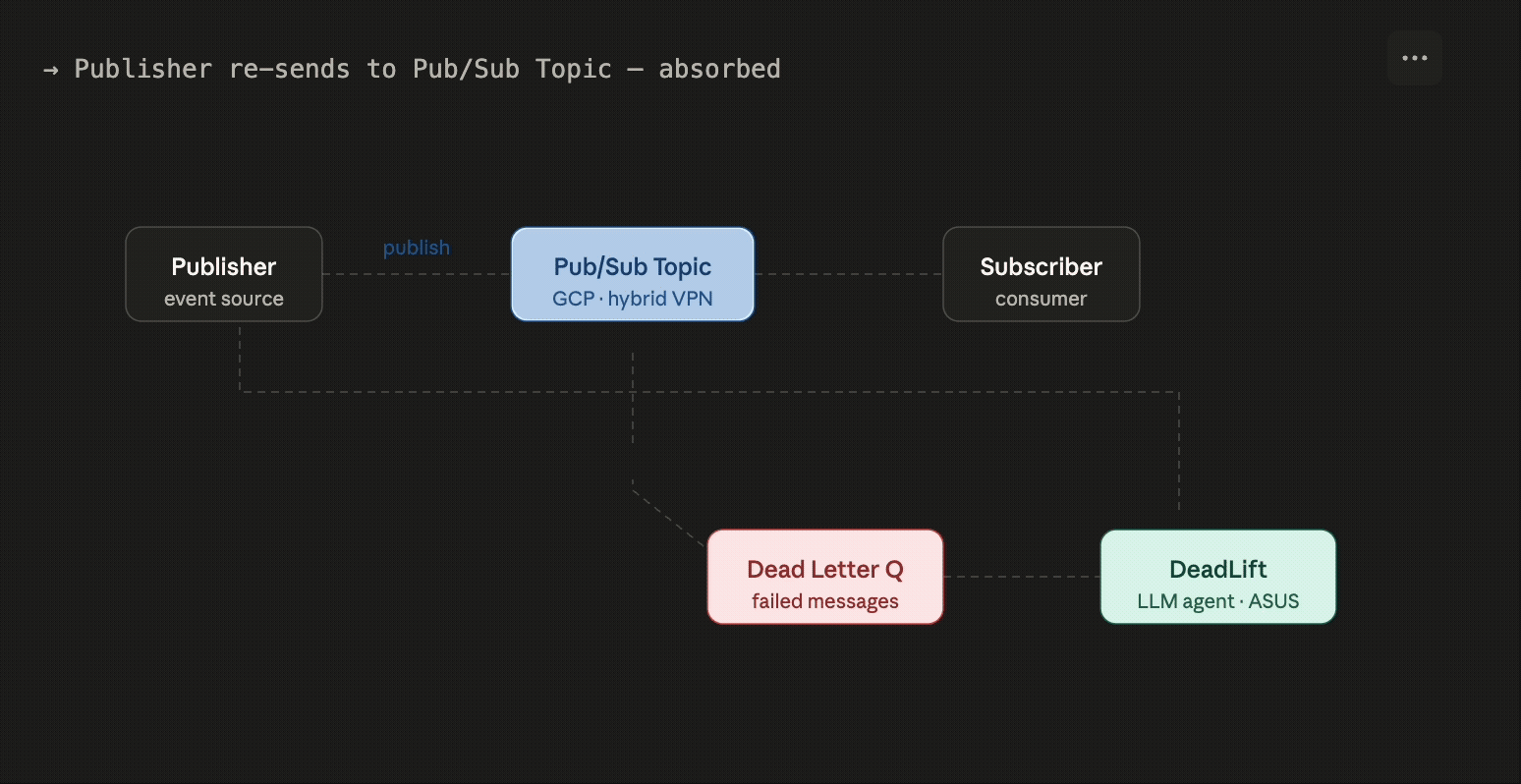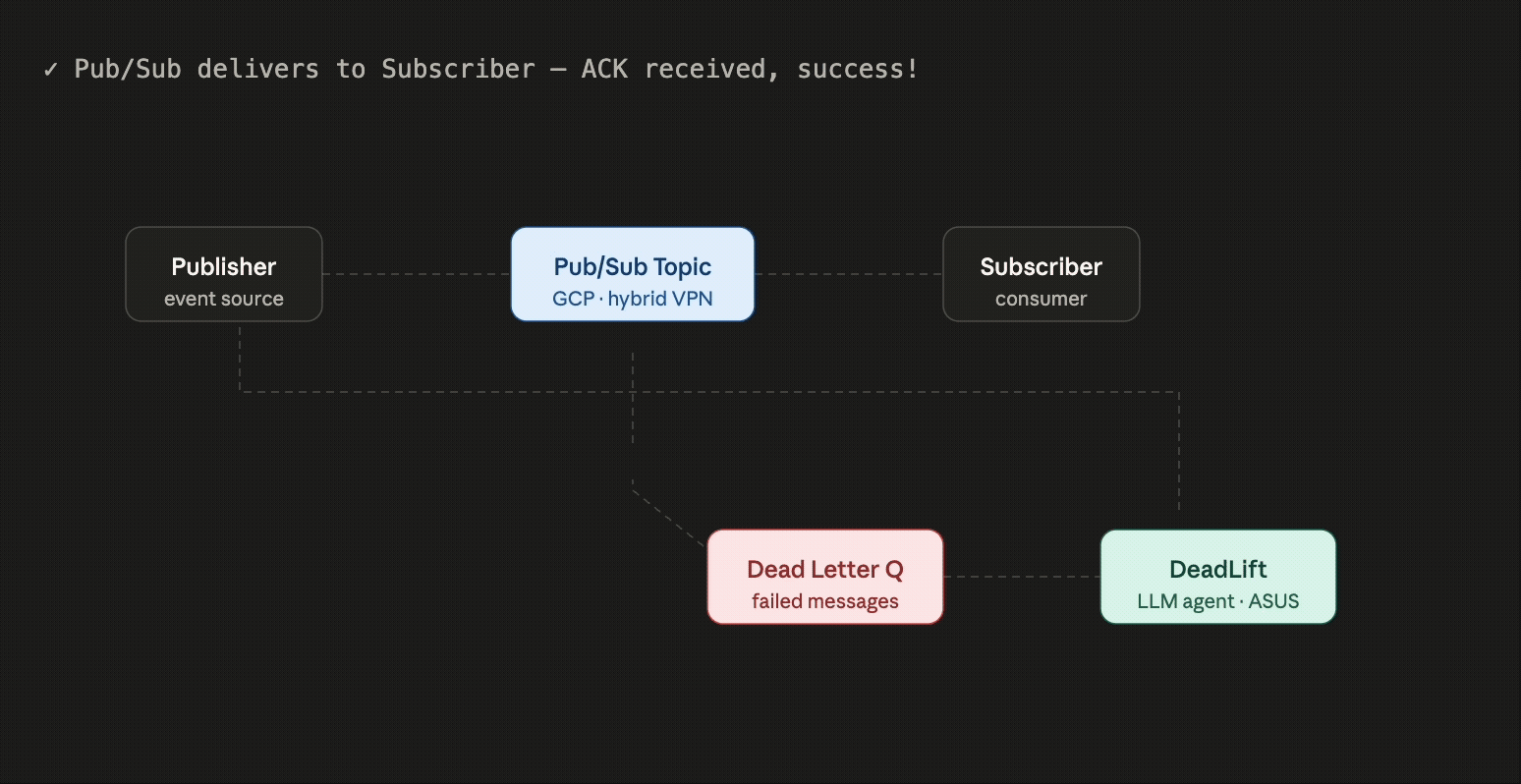
DeadLift is an autonomous on-call agent designed to rescue event-driven systems from the "manual labor" trap. Most enterprise architectures rely on Pub/Sub systems, which are built to be fire-and-forget. However, when a subscriber fails to acknowledge a message due to crashes or malformed data, the broker eventually gives up. After N retries, that message is exiled to a Dead Letter Queue (DLQ).
Currently, the DLQ is a graveyard where data goes to die. Engineers have to manually inspect failed messages, dig through logs, and replay them by hand - a slow, expensive process that kills productivity.
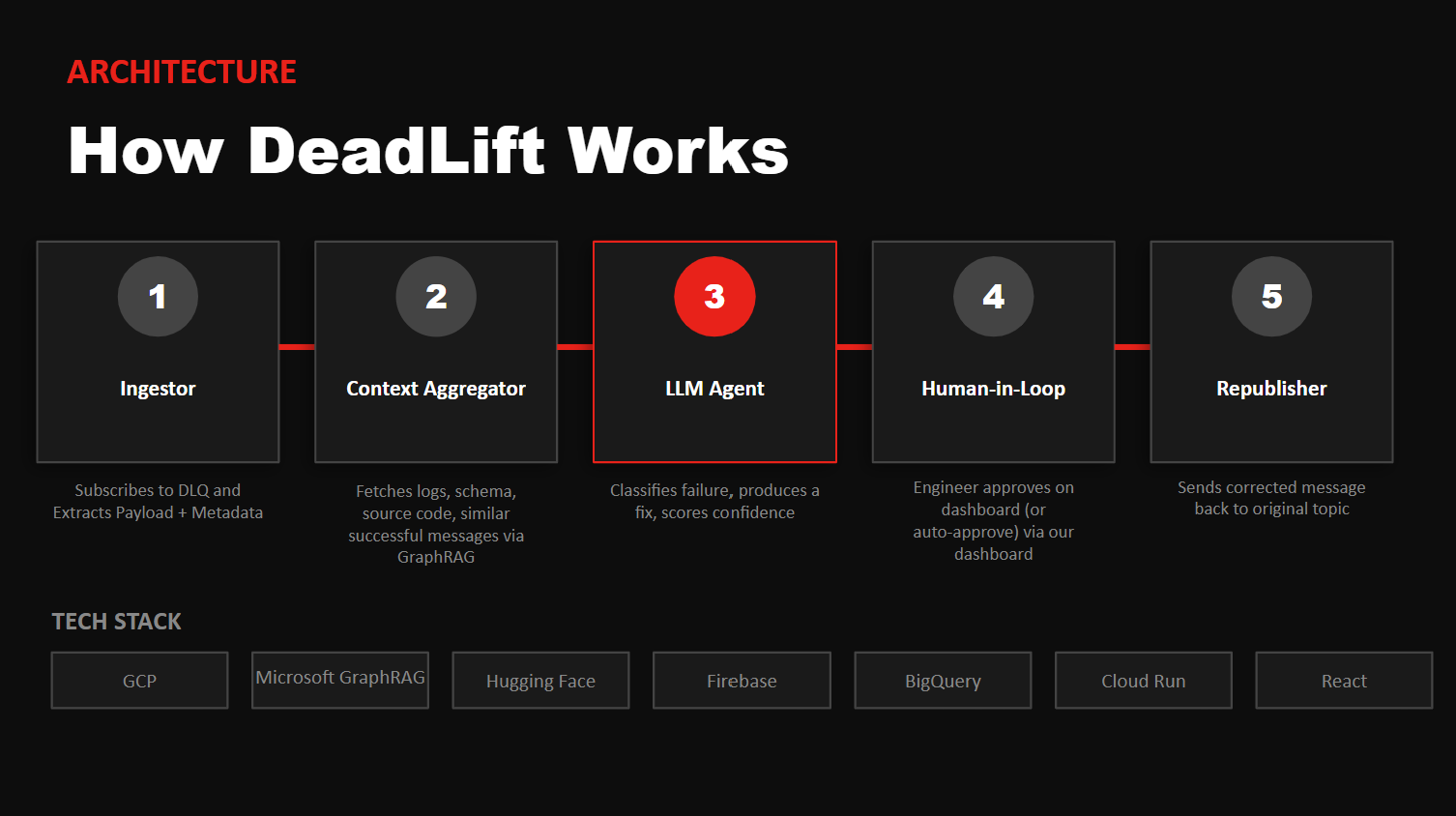
DeadLift solves this by hooking directly into your DLQ and using agentic AI to automate the triage. Our LLM agents analyze the failure, propose a specific fix, and generate a corrected payload. Instead of a dev wasting an afternoon on a broken JSON string, they can simply review the agent's suggestion and re-publish the message with a single click.
How we built it
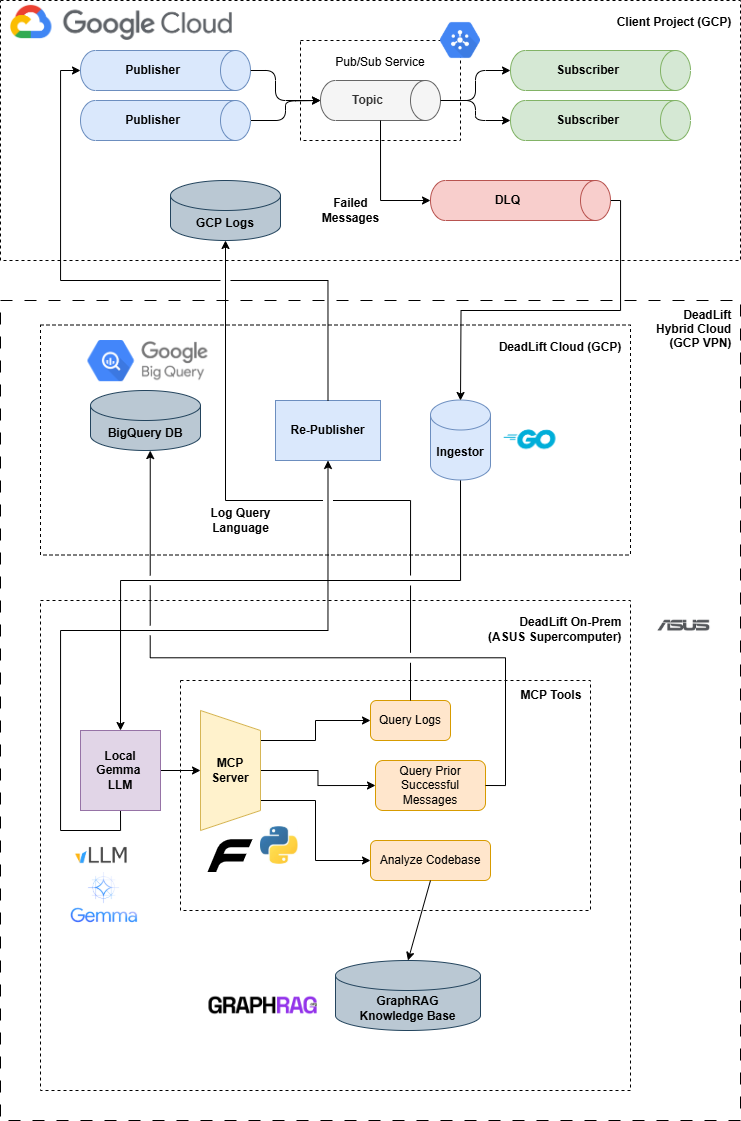
We built DeadLift on a hybrid architecture: Cloud Run microservices on GCP handle ingestion, context aggregation, and orchestration, acting as a proxy to a locally hosted Gemma model served with vLLM, keeping inference on-prem for performance and security. GraphRAG indexes are also maintained locally as user-partitioned knowledge bases, while BigQuery stores historical message context and Firebase manages real-time state. Our dashboard integrates with GCP Cloud Logging and a custom MCP server to give on-call engineers a human-in-the-loop approval flow, enabling a single-click republish of AI-fixed messages back to the original Pub/Sub topic.
Challenges we ran into
- Gemma/vLLM serving: Resolved environment config issues and optimized model weight loading through caching; wired up MCP tools to the locally hosted model with proper service account RBAC and gcloud auth.
- GCP access control: Implementing programmatic permission management and ensuring correct RBAC across services required significant debugging.
- GraphRAG pipeline: Built the end-to-end indexing pipeline from scratch, including user-partitioned knowledge bases and OAuth integration for private GitHub repos.
- Non-deterministic message arrival: Messages traveling through multiple nodes arrived out of order, making distributed debugging significantly harder.
Accomplishments that we're proud of
We're especially proud of delivering a fully no-code, frictionless onboarding experience that lets enterprise teams connect their GCP project, GitHub repos, and Dead Letter Queue without writing a single line of configuration.
What we learned
Building DeadLift taught us how to architect a hybrid cloud system end-to-end - from GCP infrastructure provisioning and access control to creating a production-grade serving harness for a locally hosted open-source model with vLLM. We deepened our understanding of building MCP server tools with a proper test suite, and gained hands-on experience navigating the complexities of asynchronous distributed systems while following a formal SDLC throughout the hackathon.
What's next for DeadLift
Looking ahead, DeadLift has broad applications beyond Pub/Sub, that is serving as a general-purpose SRE on-call automation layer for any event-driven system. We plan to expand platform support to AWS SNS/SQS and MongoDB Atlas Triggers, invest in deeper root cause analysis, and fine-tune Gemma specifically for DLQ message payload remediation. On the product side, we're building out custom auto-approval policies, richer user controls, and horizontal scaling across on-prem machines (aka more supercomputers).
Built With
- agentic-ai
- asus
- bash
- cuda
- docker
- fastapi
- gcp
- github-actions
- go
- google-bigquery
- google-lql
- graphrag
- hugging-face
- hybrid-cloud
- javascript
- mcp
- nginx
- python
- supercomputer
- terraform
- vllm
- vpc




Log in or sign up for Devpost to join the conversation.