
Dead Man's Switch — Devpost Submission
Inspiration
I need a service that needs to be running all time, but sometimes it crashed, making every service behind it unreachable. No alert fired. Nobody noticed. Hours of downtime on a real production server, documented in real time.
The traditional answer is a monitoring service like PagerDuty or Datadog — expensive, configuration-heavy tools that require you to know in advance what might break. But what if the agent already running on your machine could just... fix it? Not because you told it what to watch, but because it learned from the failure itself?
That question became Dead Man's Switch.
What it does
Dead Man's Switch is an OpenClaw plugin that turns your AI agent into a self-healing infrastructure guardian.
When something breaks — a Tailscale tunnel drops, nginx returns a 502, disk fills up, a process crashes — the agent detects it, consults its playbook, and executes the right recovery script without waking you up. When the fix is done, it tells you what happened out loud, via ElevenLabs voice alerts.
The core behavior has three modes:
- First failure — the agent fixes it silently and logs the incident to
~/.openclaw/dms-fix-log.jsonl - Second failure (same service, within 24h) — it fixes it again, then suggests setting up a cron job that monitors that service every 5 minutes, permanently
- Unknown error (no playbook match) — it searches Tavily for a fix, attempts it, and if successful, appends what it learned back into the relevant playbook
This last behavior — emergent monitoring — is the key innovation. The plugin configures itself from real failures. It gets smarter with every incident it handles.
How we built it
The plugin is built on the OpenClaw Plugin SDK and follows the platform's three-layer model:
index.ts — TypeScript plugin entry
Registers two tools (dms_recover to execute a named recovery script, dms_status to query the fix log) and one hook (gateway:startup) that reads the fix log on every boot and alerts if any service shows a recurring failure pattern.
SKILL.md — the decision brain
A plain Markdown file the agent reads on every invocation. It encodes the diagnostic sequence (always check Tailscale before nginx), the cron creation rules (never create preemptively — only when a pattern is detected), the fix log format, Tavily and ElevenLabs integration instructions, and the self-improvement loop. All intelligence lives in text.
Playbooks (skills/deadmans-switch/playbooks/)
One Markdown file per service: tailscale.md, nginx.md, disk.md, process.md. Each describes what failure looks like, what commands to run in what order, and how to verify the fix. The agent appends new fixes to these files after learning them via Tavily — they are living documents.
Shell scripts (/usr/local/bin/openclaw-skills/)
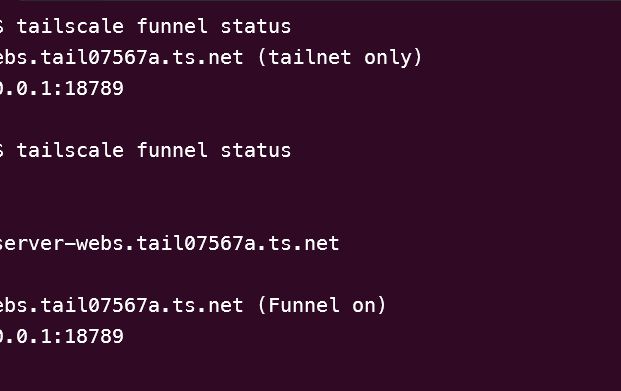
Four privileged Bash scripts installed with NOPASSWD sudoers rules. The agent calls them via dms_recover without prompting for a password. The Tailscale script polls BackendState up to 30 times before enabling the funnel — the fix for the real boot-race-condition bug we documented.
Cron jobs When a recurring pattern is detected, the agent creates an OpenClaw cron session — an isolated agent loop that runs the same diagnostic sequence every 5 minutes, fully autonomously.
External integrations
- ElevenLabs MCP for voice alerts after every recovery
- Tavily for searching fixes to unknown errors not covered by any playbook
Challenges we ran into
The Tailscale race condition was real and had to be solved properly.
The systemd service that enables Tailscale Funnel was starting before tailscaled finished authenticating, producing a NoState error and leaving the funnel in a broken state. The fix — polling BackendState in a retry loop inside a dedicated script — had to be correct, not just plausible. We debugged it on a live server.
Privilege escalation without interruption. Recovery scripts need to run as root, but the agent can't prompt for a password mid-conversation. Writing correct, minimal sudoers rules that scope NOPASSWD to exactly the four scripts (and nothing else) required care to avoid creating a security hole.
The priority ordering problem. When Tailscale Funnel is down, every external website returns 502 — not because nginx is broken, but because the tunnel is broken. If the agent diagnoses nginx first, it wastes time and may reload a working config. Teaching the SKILL.md to always check Tailscale before any HTTP-based check was a subtle but critical piece of the decision logic.
Making playbooks truly living. Getting the agent to append new knowledge back into its own Markdown files in a consistent, readable format — rather than just logging it — required careful prompting in SKILL.md so the self-improvement loop was deterministic rather than creative.
Accomplishments that we're proud of
- Zero configuration monitoring. You install the plugin, and the first time something breaks, it starts learning. No dashboards to configure, no alert rules to write.
- The Tailscale fix is real. This isn't a demo — it's a documented production bug with a script that solves it correctly on a real VPS.
- Playbooks are just Markdown. Any developer can read, edit, or extend them without knowing anything about the plugin internals. The agent reads them too.
- The emergent monitoring loop works end-to-end. Failure → fix → log → pattern detection → cron creation is a complete, tested cycle.
- Voice alerts via ElevenLabs. When the agent fixes your tunnel at 3 AM, it tells you what happened in plain English — by voice, the next time you're near a speaker.
- Published to ClawHub. The plugin is live and installable with one command:
clawhub install deadmans-switch.
What we learned
- SKILL.md is a surprisingly powerful primitive. Encoding diagnostic priority, cron rules, and self-improvement instructions in plain Markdown — and having the agent follow them reliably — works better than we expected. The LLM is good at following structured prose instructions.
- Infrastructure bugs have real root causes. The Tailscale issue wasn't a random flake. It was a race condition between two systemd services with a deterministic fix. Spending time on root cause analysis rather than just retrying the command was the right call.
- Emergent vs. preconfigured monitoring is a real distinction. Every existing monitoring tool requires you to know what to monitor before you start. Dead Man's Switch inverts this: tell it nothing, and it figures out what needs watching from the failures that actually happen on your machine.
- Sudoers scope matters. Writing privilege escalation rules that are minimal and correct is a security-sensitive task that deserves careful review, not a quick one-liner.
What's next for Dead Man's Switch
- More playbooks out of the box — PostgreSQL, Redis, Docker, SSL certificate expiry, memory pressure
- Multi-server support — monitor remote hosts via SSH, not just localhost
- Slack / Telegram channel integration — send incident reports to a team channel, not just voice
- Incident timeline view — a
dms_statusdashboard that shows the full history grouped by service, with fix success rates - Playbook sharing — a community registry where users can publish and install playbooks for their specific stack, similar to how npm packages work but for recovery procedures
- Windows and macOS support — the current plugin is Linux-only; most of the shell scripts could be ported with a platform abstraction layer
Built With
- clawhub
- openclaw
- shell
- typescript

Log in or sign up for Devpost to join the conversation.