Inspiration
Life is full of emotional ups and downs—academic stress, heartbreaks, burnout—and we often seek comfort in scents, words, or music. What if an AI could combine all of these and respond to your emotions like a real friend?
We were inspired to build a multi-modal emotional support system that doesn’t just understand your feelings but responds through personalized sensory care. By integrating language understanding with aromatherapy knowledge, music generation, and TTS voice comfort, we created a full-stack wellness pipeline.
What it does
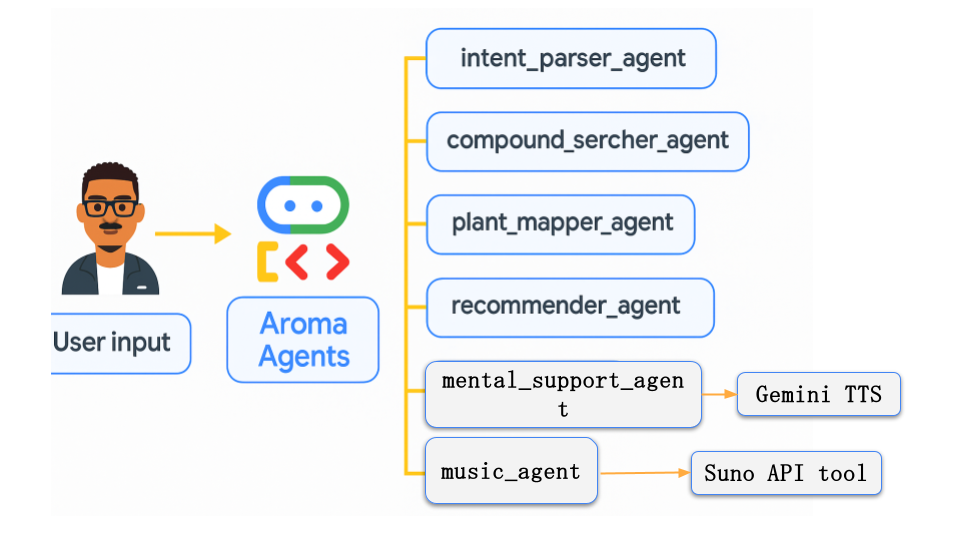
Aroma Agents is a multi-agent emotional wellness system powered by LLMs using the Google Agent Development Kit (ADK). Given an emotionally charged user input like:
"I just failed my final exam and I feel completely overwhelmed. I wish something could help me calm down."
The agent chain will:
- Detect emotional context and intent.
- Recommend suitable aroma compounds (e.g., linalool, menthol).
- Map compounds to natural herbs (e.g., lavender, peppermint).
- Suggest how to use them (tea, diffuser, massage).
- Generate a gentle comforting message and synthesize it into speech using Gemini TTS.
- Compose a healing-themed song and use Suno API to generate and download MP3 audio.
The entire experience is seamless, empathetic, and deeply personal—blending language, olfaction, voice, and music in one healing loop.
How we built it
- Built using Google ADK's
SequentialAgentand modularLlmAgentandFunction Toolcomponents. - Integrated Gemini 2.0/2.5 XXX for language and TTS synthesis.
- Used Suno API for song generation and audio download.
- Each agent's input/output is structured via Pydantic schemas.
- Hosted with local ADK runtime;
.envfile manages API credentials. - Music and audio saved to local file paths for playback or integration.
Challenges we ran into
- Audio Synthesis Consistency: Gemini TTS returned different formats (raw vs. mp3); we had to normalize and dynamically convert output to WAV when needed.
- Suno Polling: Suno’s music generation API has delayed outputs; we built a robust polling orchestrator with fallback status handling.
- Multi-modal integration: Coordinating textual, musical, and vocal outputs required careful agent chaining and fallback logic.
- Emotional intelligence: Prompt tuning for the Mental Support Agent took iteration to balance tone, clarity, and comfort.
What we learned
- How to build composable multi-agent pipelines using Google ADK.
- Best practices in emotional prompt engineering and safety-conscious messaging.
- Real-world orchestration of multi-modal outputs (text → scent → audio → song).
- Using structured input/output schemas across agents to enforce flow reliability.
What's next
- Web or mobile deployment: Make the system accessible via a public-facing web or mobile app for real-world usage and testing.
- Incorporate local herbal databases: Although this demo used LLM-generated outputs, we already have access to a rich offline dataset of herbal compounds and plant mappings. Future versions will integrate this structured data directly.
- Herbal product integration: Provide real-time links to online shops for recommended herbal products, or suggest ways to identify and collect natural herbs in the user's local environment.
- Multilingual emotional support: Gemini TTS currently supports 26+ languages including Japanese, Chinese, and Portuguese. We'll integrate language control logic between agents to enable multilingual support dynamically.
- Multimodal grounding: Explore integrating visual inputs—such as interpreting facial expressions or gestures—by connecting with tools like Google VEO 3 or NotebookLM for enhanced contextual awareness.
- Personalization via feedback loops: Implement a journaling and feedback mechanism so the agent can continuously adapt to individual users’ emotional patterns and preferences over time.

Log in or sign up for Devpost to join the conversation.