-
-

Cover Photo
-
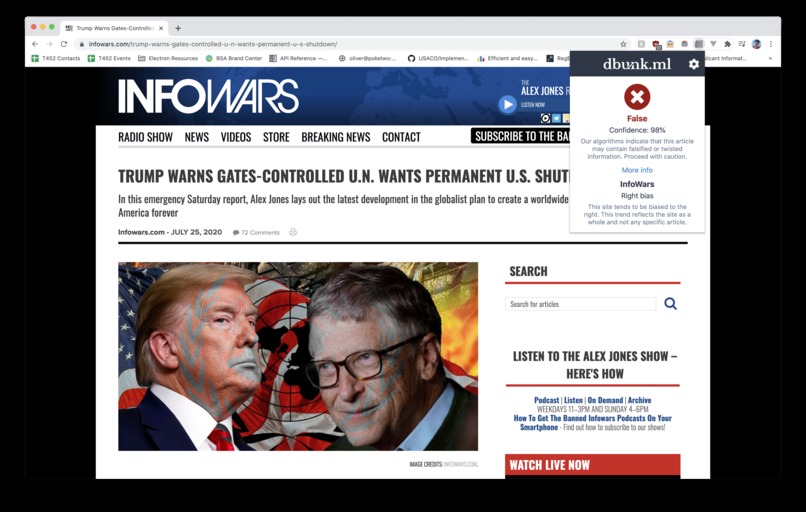
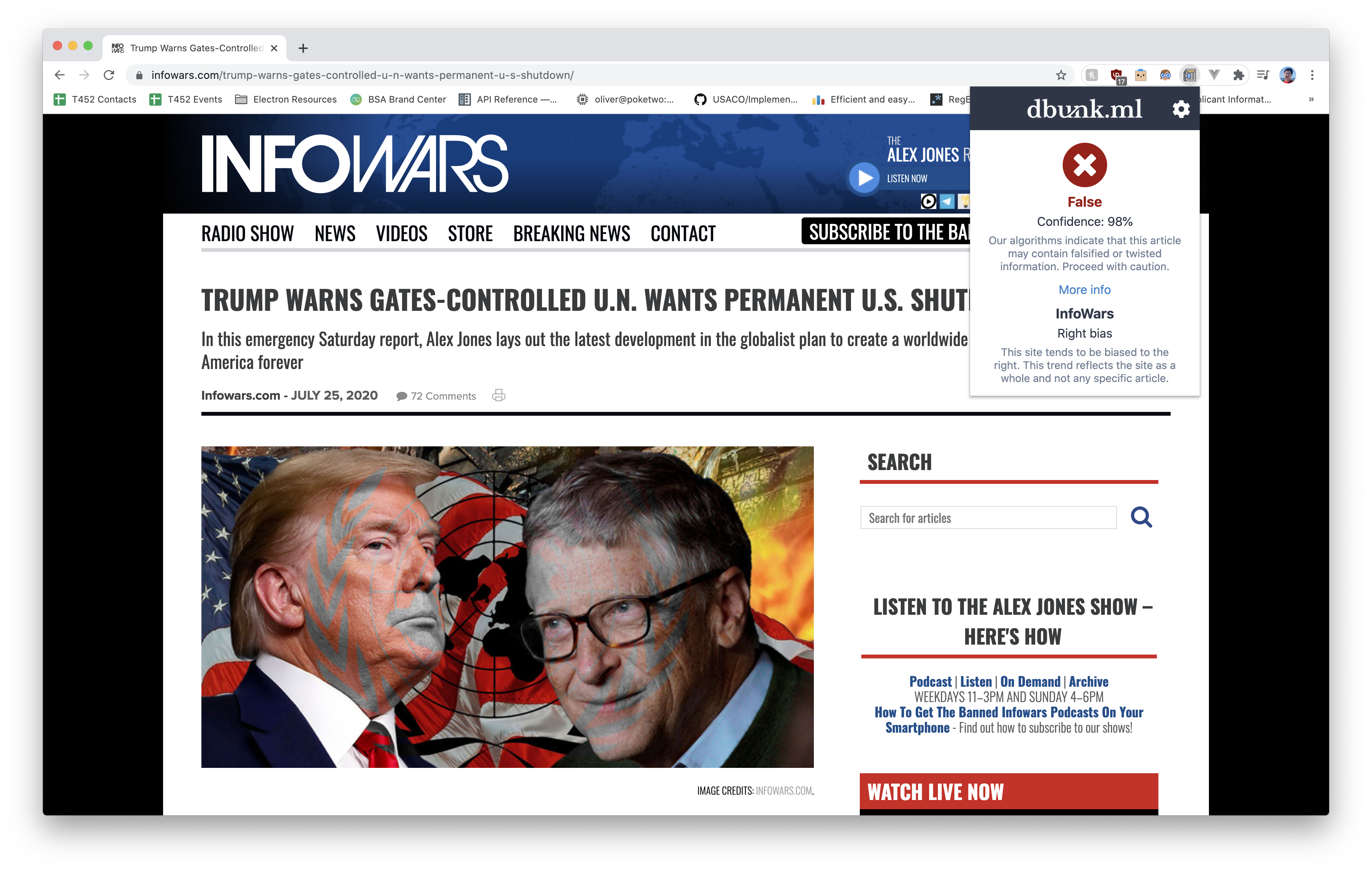
Browser extension detecting fake news
-
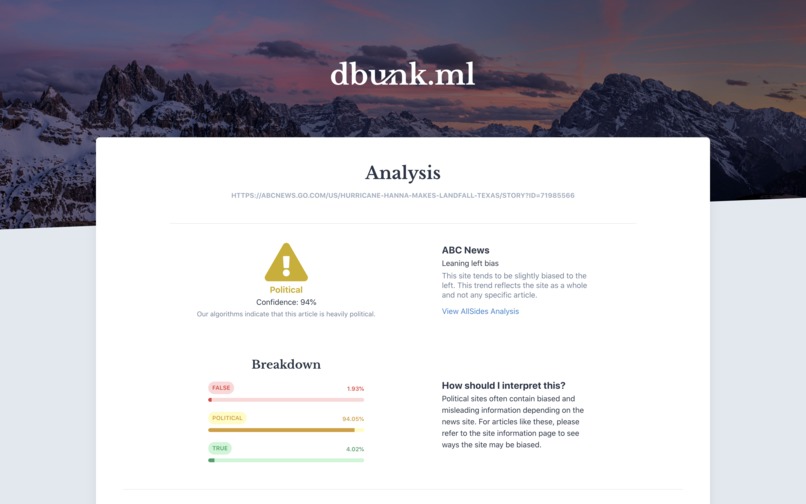
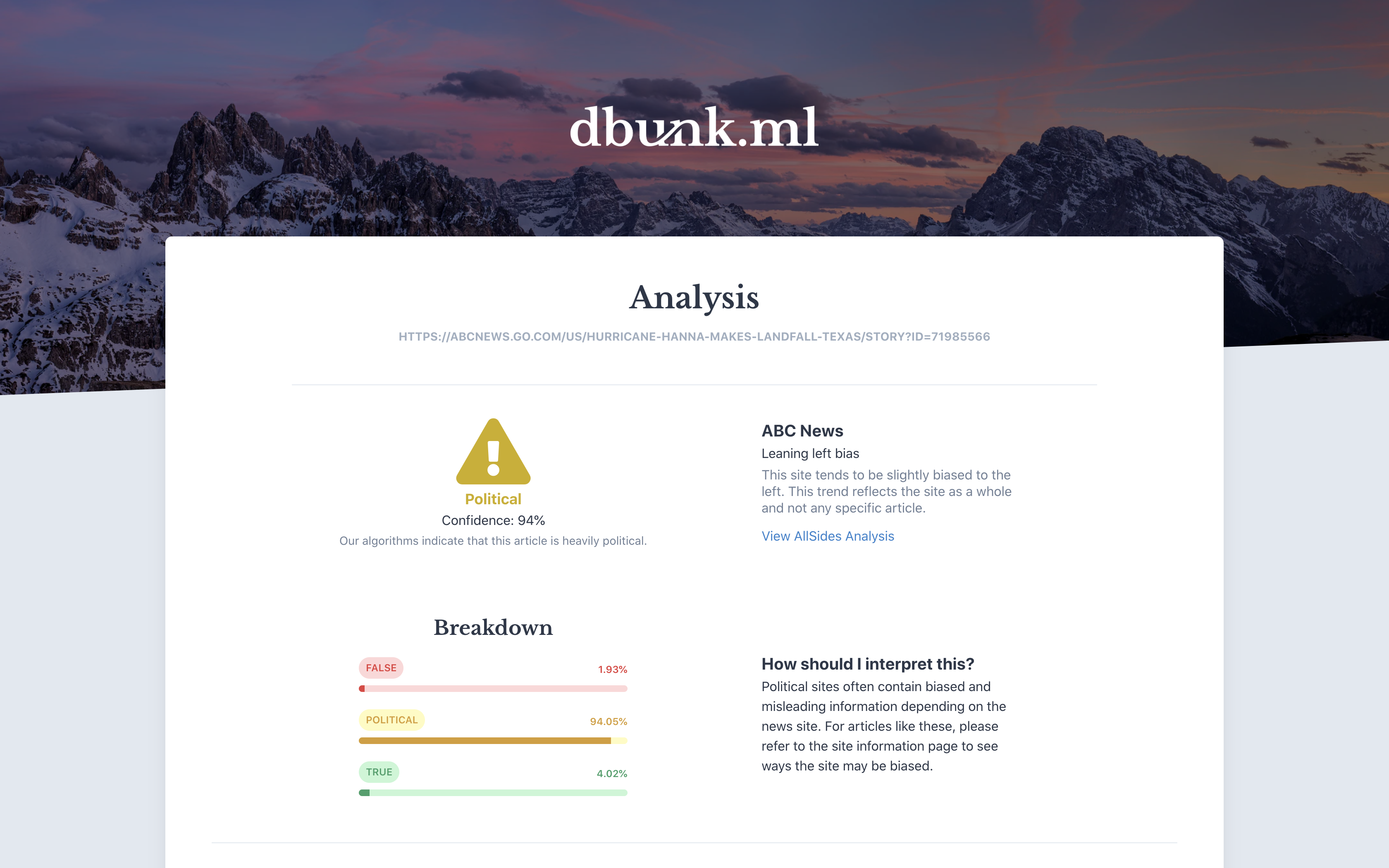
Breakdown analysis of a political article
-

Homepage


dbunk.ml
Inspiration
The advent of the Internet and the Information Age has transformed the way we receive and interact with information. Billions of people worldwide now rely on online news sources to stay up-to-date with current topics, and we are now able to spread information at speeds never seen before.
However, this comes with a catch. Fake news is becoming more and more prevalent on online news sites, and it is increasingly difficult to distinguish credible information from articles meant to spread misinformation. This issue has become a hot-button topic in recent news and election cycles. Often, this requires doing extensive research and cross-checking of sources, which takes an immense amount of time and effort.
Furthermore, being able to trust online information is especially important during critical situations like COVID-19. In a time like this, the truthfulness of news has become a public health issue. When citizens rely on news sources to keep themselves safe, it is extremely important that those sources are telling the truth.
We surveyed the residents of Cupertino, San Jose, Saratoga, and nearby cities, and found that over 60% of people expressed concern over fake and real news on the internet. What’s more, nearly 80% of people would be more engaged in current events, activism, and politics if they had a better way to identify credible information. Busy parents and workers expressed to us that they lacked the time and energy to keep up with the news on top of their already packed schedules. We wondered if there was a better, more efficient way to filter out misinformation. That better way did not exist, until now.
Our solution
Introducing dbunk.ml. Leveraging big data, modern machine learning frameworks like TensorFlow, and the massive computational power of Google’s Cloud Tensor Processing Units, we can now train neural networks tens of thousands of times faster than we could before. Using this technology, we tailored our model to 10 million news articles from over 1000 different online news websites in order to classify news articles as completely fake, largely political, or credible. After iterating on network design and training for multiple days, our model can now correctly categorize news articles 94% of the time, a result comparable to that of existing fact-checking watchdogs, but our fully-automated solution lets users know whether or not to trust articles with a single click.
Our state-of-the-art system is displayed using a browser extension that clearly displays the credibility of a certain website. While browsing the web, our extension will automatically detect applicable news sites, and the extension icon will light up. By clicking the icon, the article is then sent to our servers, which analyze the article using our model and send the result back to the user within seconds.
dbunk.ml is:
- Instant. Our extension gives you instant insights into news articles as you browse, with a single click.
- Accurate. Powered by state-of-the-art machine learning technology, our model delivers 94% accuracy across thousands of news sites.
- Detailed. Our algorithms deliver comprehensive analysis and political bias indicators from hundreds of news sites instantly in a simple user friendly interface.
How we built it
We used Python and TensorFlow to train our model on FakeNewsCorpus, a dataset of 10 million news articles from 1000 different news websites. We trained our model using Google's Cloud TPUs, which deliver over 100 Petaflops of performance (that's a huge amount of computational power!) Our model is based on the LSTM architecture, which has proven time and time again to be excellent for text classification and sequences.
We used Flask to build our API which communicates with our machine learning model. Our website and extension is built with HTML, CSS, and JS, and we used Vue.js for reactive framework. We also used the chrome extension API to get the popup, tabs, and to store user settings.
Challenges we ran into
We ran into a lot of trouble throughout the process. The first was the dataset. We first used a dataset hosted on kaggle, which gave us really good results (99.8%) really easily. This sounded too good to be true, so we did some investigating and found that that dataset was really skewed and did not apply to real world articles.
So we went on the hunt for another dataset. This time, we found https://github.com/several27/FakeNewsCorpus, a dataset of 10 million articles from across 1000 different news sites, all clearly classified. It looked amazing! But they didn't have a released version because it was too large, so we had to write code to retrieve the dataset ourselves. It took a while, but we finally got it working.
Now, with this new dataset, our model was originally only getting around 70% accuracy, which is good, but not as good as we hoped. We realized that we were trying to classify into too many different categories, like conspiracy, pseudoscience, and rumors. This was too much for the network to handle and we ended up making it only distinguish between credible, political, and fake news, which proved to be a lot easier for the network to learn. We ended up with a 94% accuracy tested using 1000 real articles from the internet after training for a few days.
That might not sound like much, but it took a lot of iterations to get here. We first tried using just a simple GRU, but it didn't work, so we tried LSTM. LSTM worked better, but it still wasn't doing very great because of vanishing gradients. So we needed to use our own special implementation which solved the problem of the vanishing gradients. Stacking two of these special LSTM layers on top of each other allowed us to achieve better accuracy.
We also needed to fine tune our model many times to prevent it from overfitting (which is where it just memorizes the input data and can't apply it to the real world.) We used regularization and dropout to prevent overfitting, and although the training accuracy went down from 99.3% to 96%, it proved to work a LOT better in the real world than it did before, getting a 94% validation accuracy compared to the before 80%.
Accomplishments that we're proud of
This project started out as a simple idea, but it turned out to actually work really well, even better than we imagined at the start. All those hours and hours of hard work fine tuning the model really paid off! We expected it to work a lot better in theory than in practice, but after testing it on a few hundred links, we realized that it applied really well to the real world.
Many times, hackathon projects turn out to be just a "prototype", which doesn't necessarily work well yet, but we're proud that this time we actually finished a very great product that can already be applied and used by people to help them identify fake news.
What we learned
We learned many things here. Going in, only one team member had a lot of experience with machine learning, one had some experience but not that much, and one had none at all. Everyone was able to learn working on it together. Even the person who did not have any experience at all now knows lots of the fundamental principles and how to tune the model and stuff.
We also learned how to make browser extensions. Before, we thought about making it just a website, but realized a browser extension was perfect. No one had really made a legitimate browser extension (besides just a timer).
Most of all, we learned good ways to work together even remotely. Before, it would have been really hard to work together this efficiently, and at the start, it was really confusing to everyone. But by the end, we'd learned to work together REALLY efficiently and could get everything done quickly.
What's next for dbunk.ml
We want to improve this even more. Right now, some articles can't be analyzed because they are behind a paywall or the news site doesn't let robots view the site to get the text. This is only a really small portion of news sites, but it is still a problem that we need to deal with. We can experiment with taking the text directly from the user's browser instead of just the URL, but that might cause some privacy issues.
We also want to integrate it with more services, such as mobile devices. One idea is to make a browser app that functions exactly like the built in one, but with added news checking features.
Thank you, and welcome to dbunk.ml.
Unfortunately, chrome makes you pay to publish the extension on the web store, so we aren't able to do that. but you can view the code at GitHub.
Built With
- chrome
- machine-learning
- tensorflow






Log in or sign up for Devpost to join the conversation.