-
-

Search
-

Log In
-

Register
-
Loading
-

Features
-

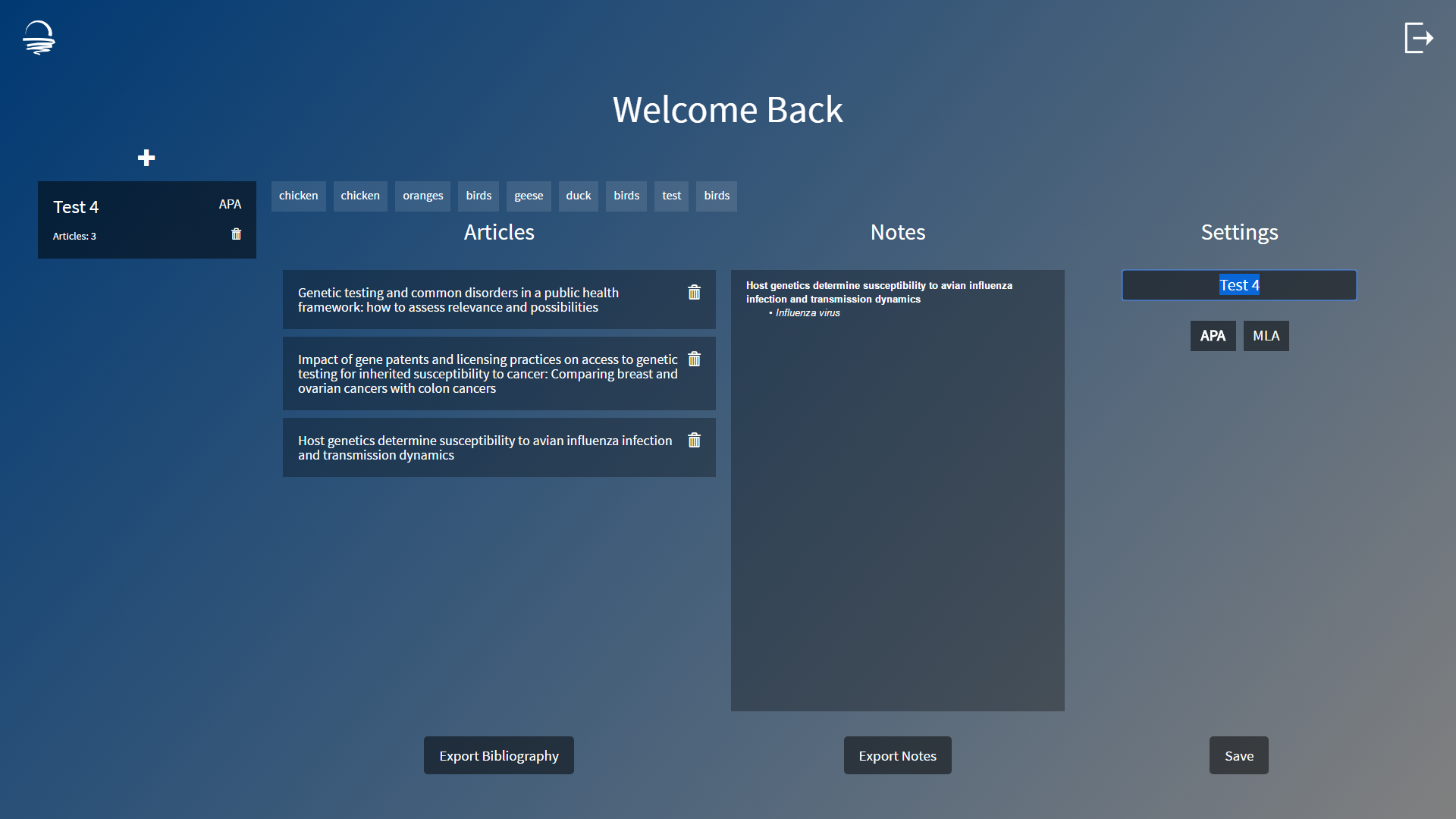
Article Display
-

Automatic Citation
-

Notes Panel
-

Keyword Highlighting
-

Project Display
-

Project List
-

Read Saved Articles
-

Results
-

Add Project










Inspiration
As students of a research oriented high school, we often found it difficult to find time to pursuing research projects while keeping up with school work. To solve this dilemma, we decided to build a web application that would focus on mitigating the time-consuming factors of the research process.
What it does
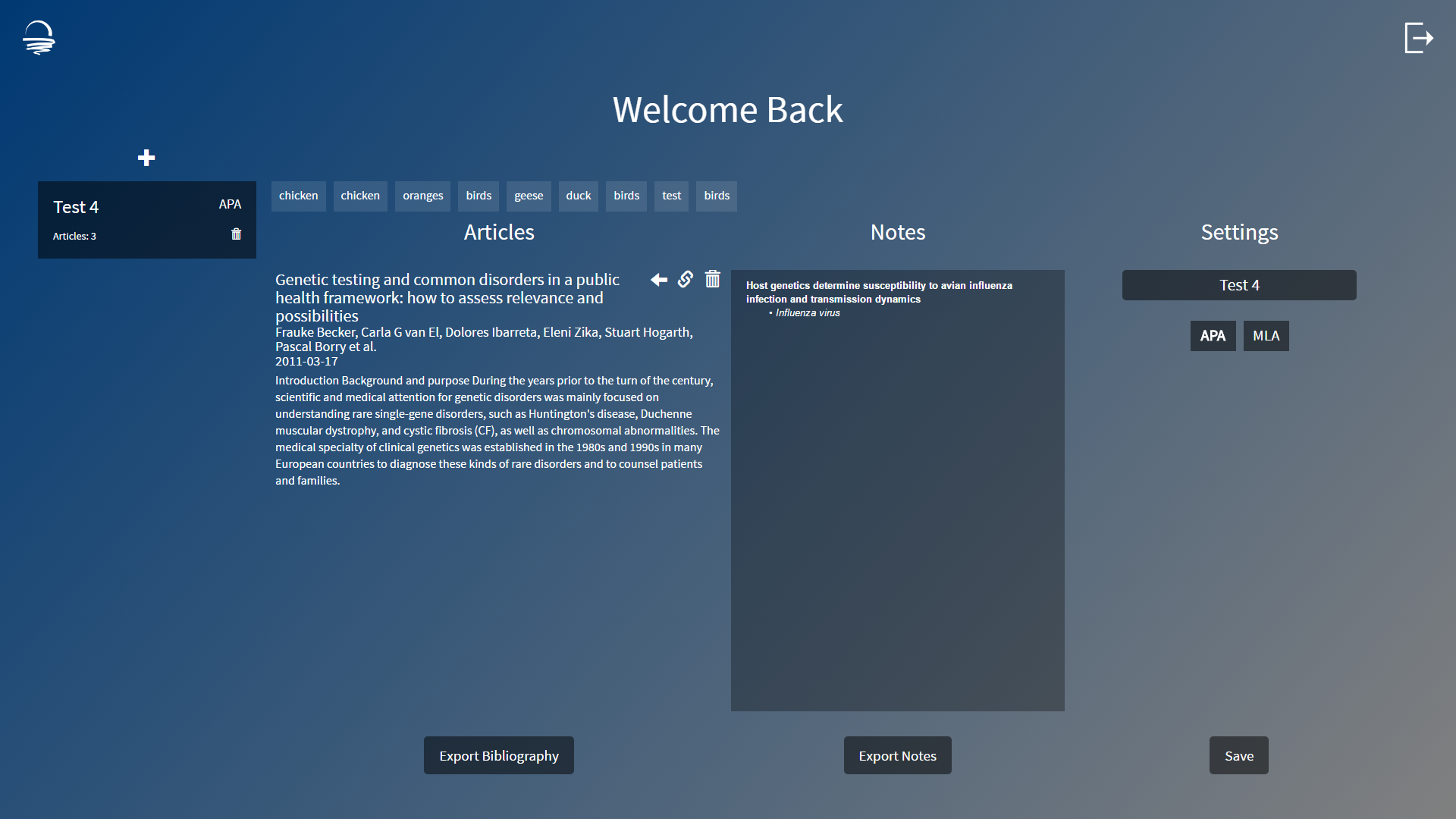
Dawn would help researchers by offering related topics to research, highlighting key parts of an article, display related academic articles sourced from many reputable publishers (i.e. Nature), take notes on an article, define words in articles, give citations for articles, add articles to projects (which are like playlists), and produce a bibliography and/or notes page for a project. Most importantly, this can all be done on one website, without having the need to switch tabs, windows, etc.
How we built it
To build the web application, we used HTML, Javascript, CSS, and Node.js. To add the main functionalities for our application, we implemented the IBM Watson API, Firebase, Aylien API, Easybib API, and Nature API.
Challenges we ran into
There were a two main challenges that we ran into while creating Dawn. The first problem was the fact that the APIs we used requires money to be used extensively due to the large number of requests we made. The second challenge was creating accounts for users to save notes, projects, etc. This was a challenge primarily due to the fact that it was our first time building an accounting backend for a website.
Accomplishments that we’re proud of
We’re especially proud of our UI and UX. We spent a considerable amount of time pondering the most effective way we could present our idea.
What we learned
- Handling requests for APIs
- Creating a Highlight and Define function for the articles’ text
- Using Firebase to create and manage accounts that store data
- Using Modal Boxes
What's next for Dawn
First, we would like to create a better experience on Dawn by integrating more APIs which would allow users to access a larger number of articles. Second, we would like to create a cloud word processor that would help with academic language, check for plagiarism, and other features that can potentially help researchers output better research papers. Third, we would like to create a system to classify articles as read, important, irrelevent, and unread. This way, researchers can filter out unimportant articles from future searches for a certain project, see which articles were important and require further reading, and know which articles the researchers have read.







Log in or sign up for Devpost to join the conversation.