-
Home Page
-
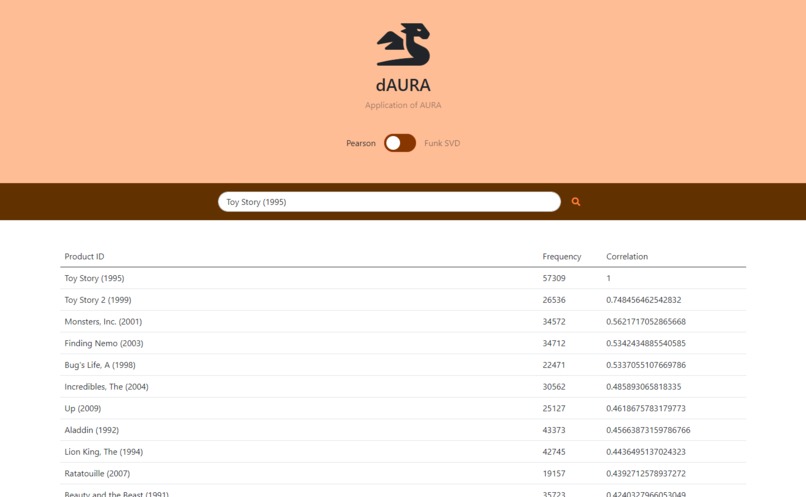
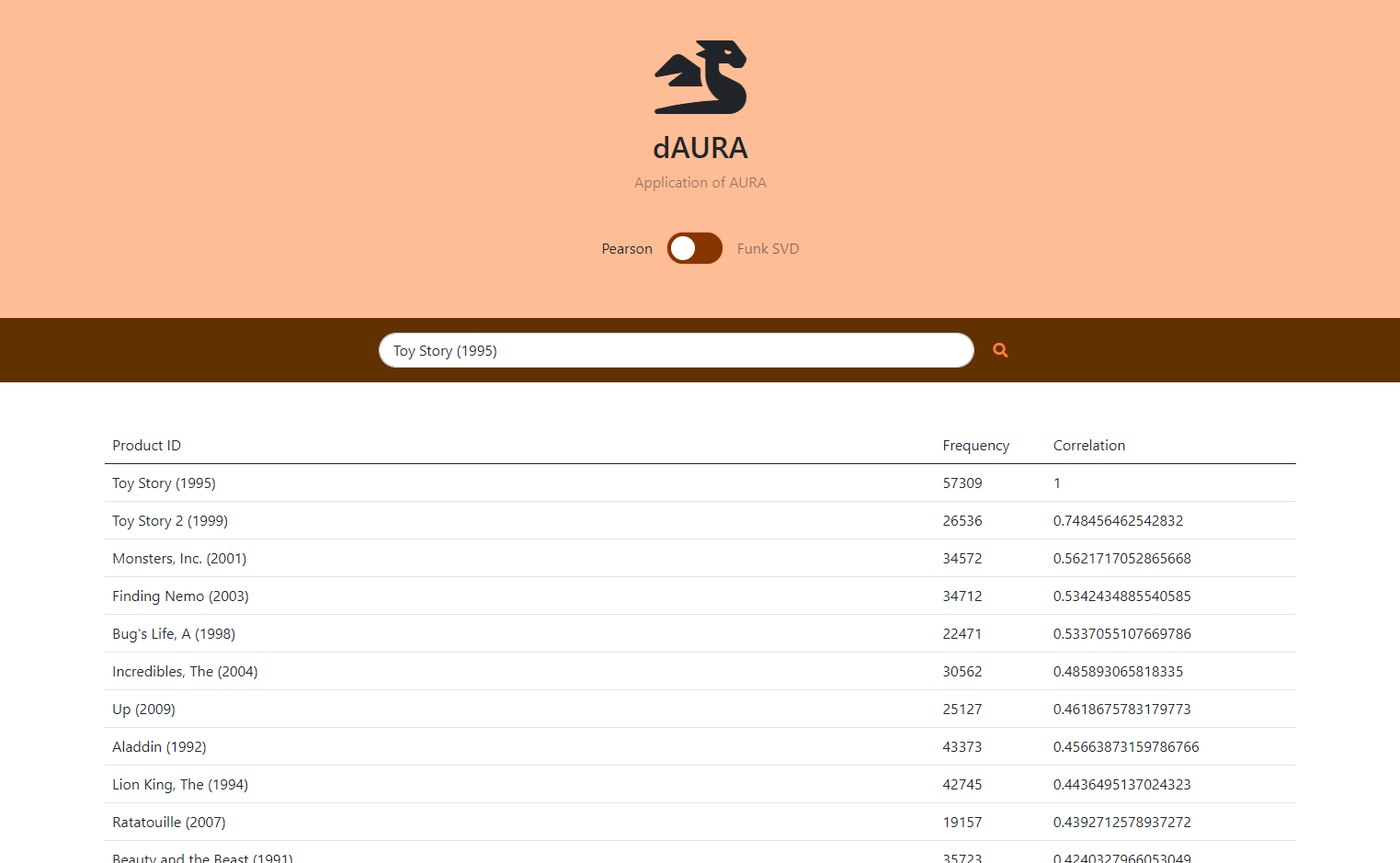
Pearson Coefficient Recommendations without User Preferences
-
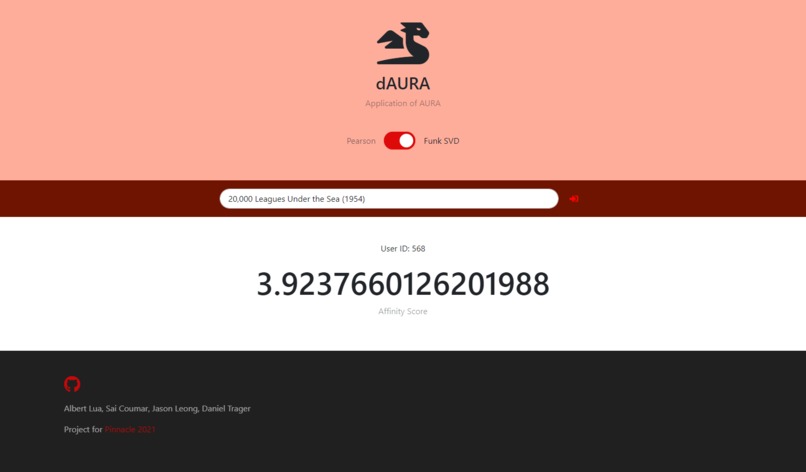
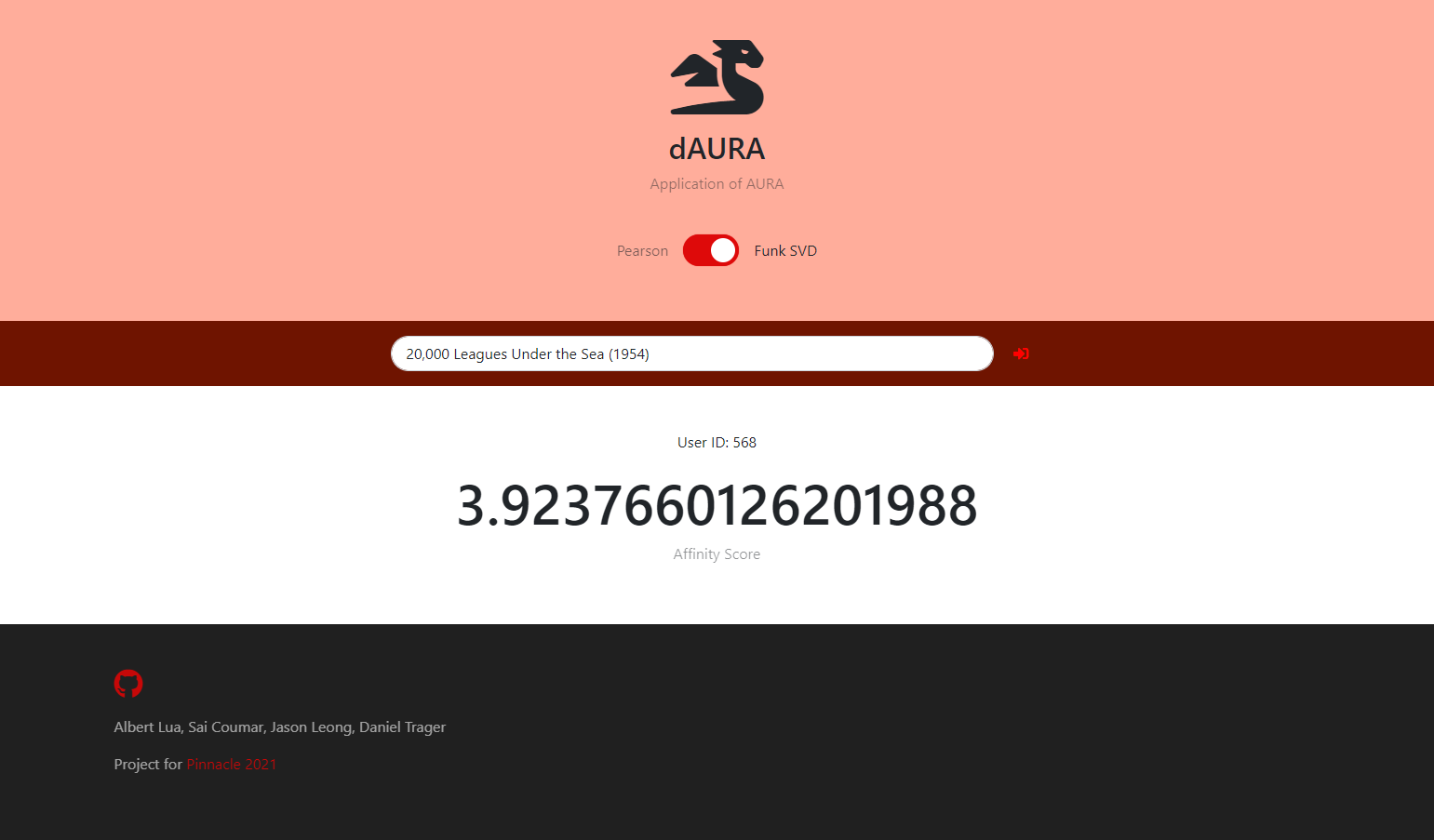
Predicted Rating Based on Your (User 568's) Preferences
-
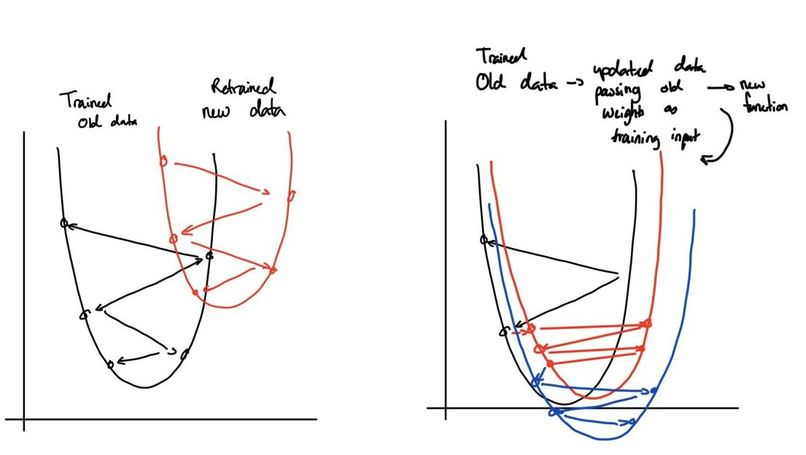
Rough Graphical Visualization
-
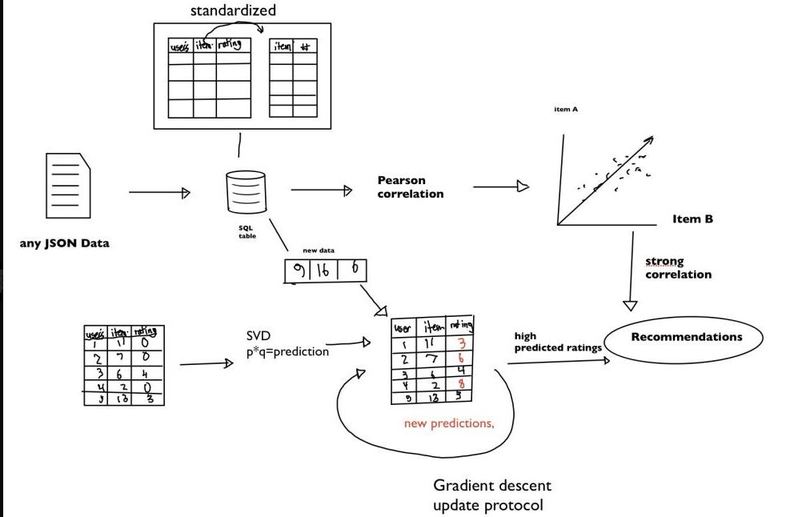
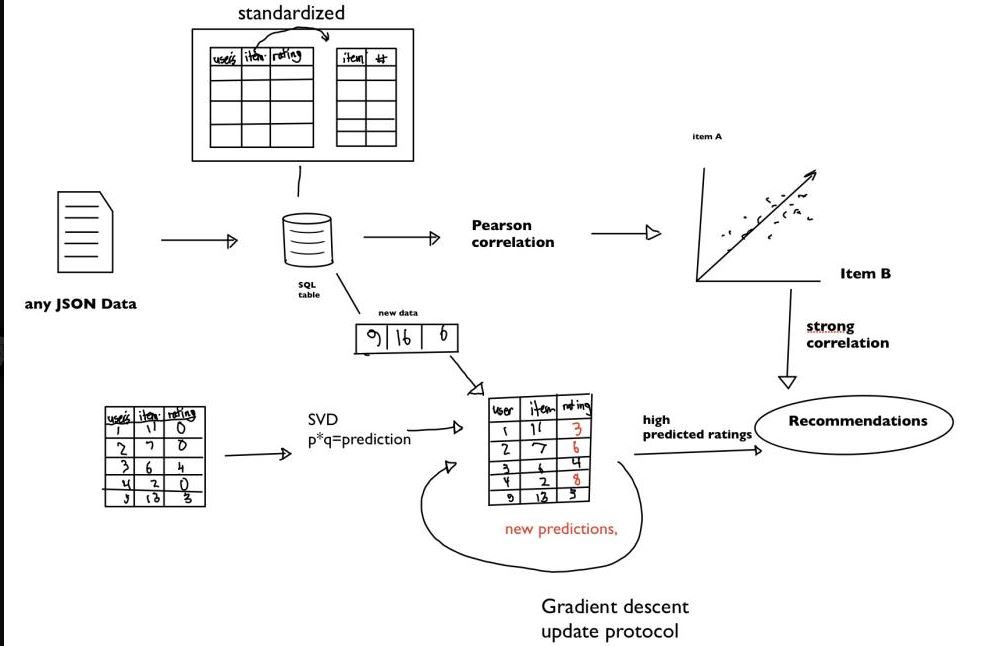
Overall Structure
-
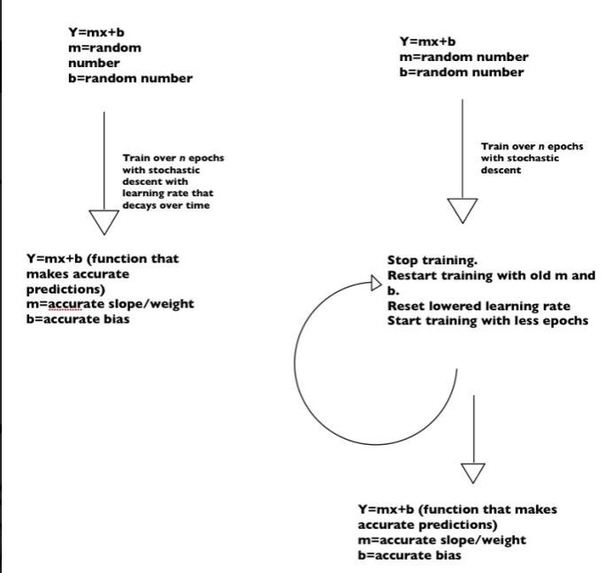
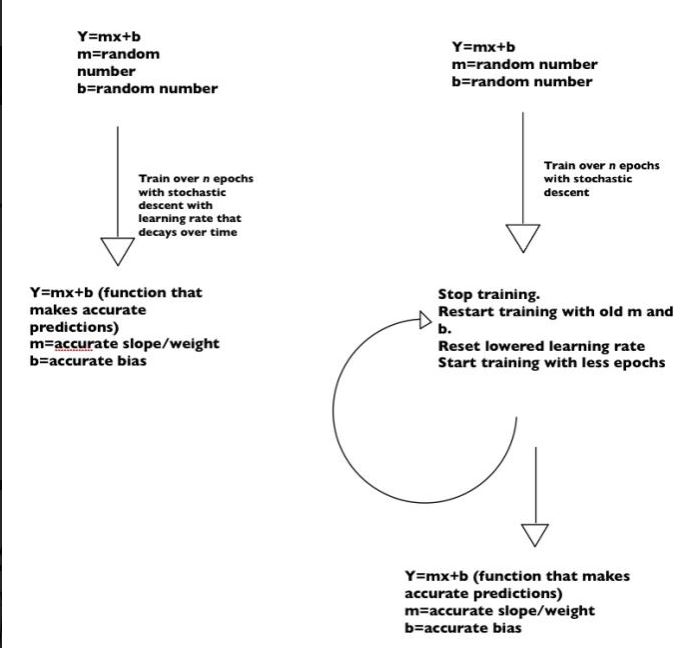
How Sai Coumar's Stochastic Gradient Descent Update Protocol works
dAURA!'s inspiration
dAURA!(Demo, Adaptable, User, Recommendation, Algorithm) is a general recommendation engine designed for efficiency and can be applied to any dataset in a user, item, rating format. We started with Simon Funk's Funk SVD algorithm and Karl Pearson's PearsonCoefficient Correlation and expanded on those algorithms using innovative optimization techniques to improve upon the efficiency and practical scalability for a general use recommendation system. dAURA is our practical demo application that recommends movies, as proof that our recommendation engine works.
AURA!'s optimization features
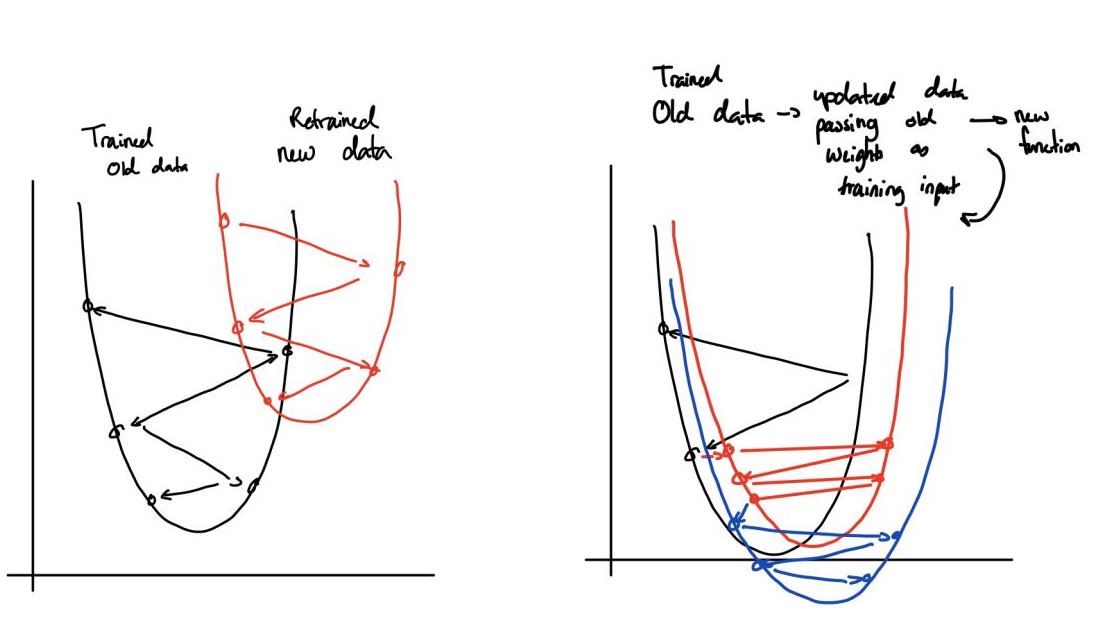
Sai Coumar's Stochastic Gradient Descent Update Protocol: -See diagrams before to follow logic Typically Stochastic Gradient works by making jumps to random points and minimization the difference between the predicted value and actual values. While this is valid, a problem that will happen is that as the real-world data changes, the weights will eventually (theoretically) become outdated. My update protocol is essentially rerunning Stochastic Gradient Descent, but instead of randomly initializing our starting points, we use our old points, which should theoretically already be close-all changes in data change in increments and the update protocol would capitalize on the lack of disparity between the two increments to justify the algorithm. Also, while our first Stochastic Gradient Descent Algorithm has a learning rate decay, we would boost the learning rate which in practice led to a lowered loss given the same epochs. To test this, we started on basic linear regression with the sckitlearn Boston dataset, and then reapplied the protocol onto SVD. Both times, the loss was lower (by an extremely small amount that would require scientific experimentation to actually prove) and also could update at any point. In the long run, the efficiency should be the same as retraining the data, but for the time between retraining, you would have usable and undoubtedly up-to-date weights.
Pearson Coefficient Recommendation System We developed a Pearson Coefficient for the movielens dataset and generated recommendations that a user can use without having to spend considerable time giving the algorithm their own personal data to base the recommendations. Since it was implemented in SQLite, we were able to optimize for time efficiency as well.
dAURA!'s data handling
AURA portion of dAURA! is built on mostly Python, SQL, and HTML/CSS/JS and JQuery for the front end. We designed it to adapt to the structures of JSON and CSV datasets and convert them into indexed SQL databases that we have more control over. When a user submits a form in our UI, it sends an HTTP request to our Flask server, queries and filters the SQL data and feeds it into our two recommender algorithms. From there we simply output the results on the webpage.
Obstacles dAURA! encountered
For the entire engine, it was hard to validate each part of the algorithm and we needed to evaluate them independently and piece them together. Another issue was that some datasets were missing product names, which made our UI less intuitive. However, our demo implements the MovieLens dataset which does have movie names.
Accomplishments that we're proud of
-Implementing Stochastic Gradient Descent, FunkSVD, Pearson coefficient function from scratch -Expanding it with Sai Coumar's Stochastic Gradient Descent Update protocol -Combining a jQuery frontend with a Flask backend and using ajax -Using SQL for data management instead of a csv file
What the HackDuke2020 Team learned
-Advanced SQL -Combining a flask back end with a jQuery Front end -Web scraping and it's advantages and disadvantages -Implementing FunkSVD, SGD, and Pearson coefficient functions from scratch -Using sckikitlearn to achieve the same task
The Future for dAURA!
Future plans for dAURA! would be to implement a login system so users would be allowed to store data inside the system; If users were able to store their past ratings for shows they have watched, we would be able to give them personalized recommendations with SVD instead of demonstrating on random users. Note: the Pearson algorithm does not have this issue. Another goal for dAURA! is that we would improve the accuracy of our SVD Algorithm. Lastly, the final goal for our recommendation engine is that we would want to make it into an API that would allow the implementer to use our algorithms in only a few lines of code.





Log in or sign up for Devpost to join the conversation.