-
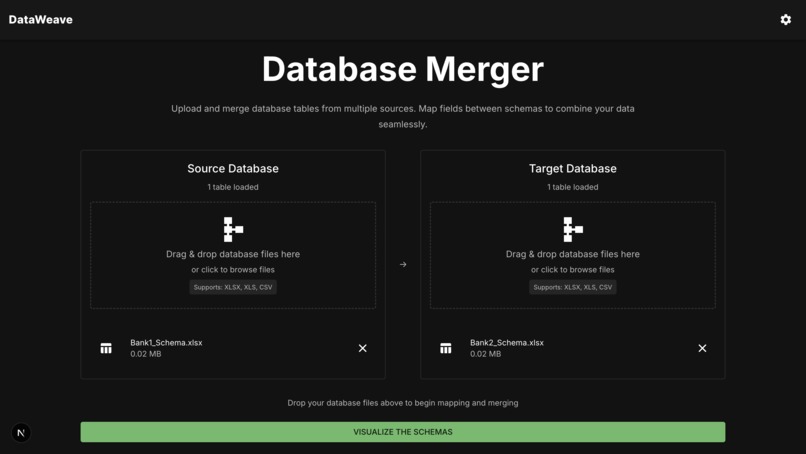
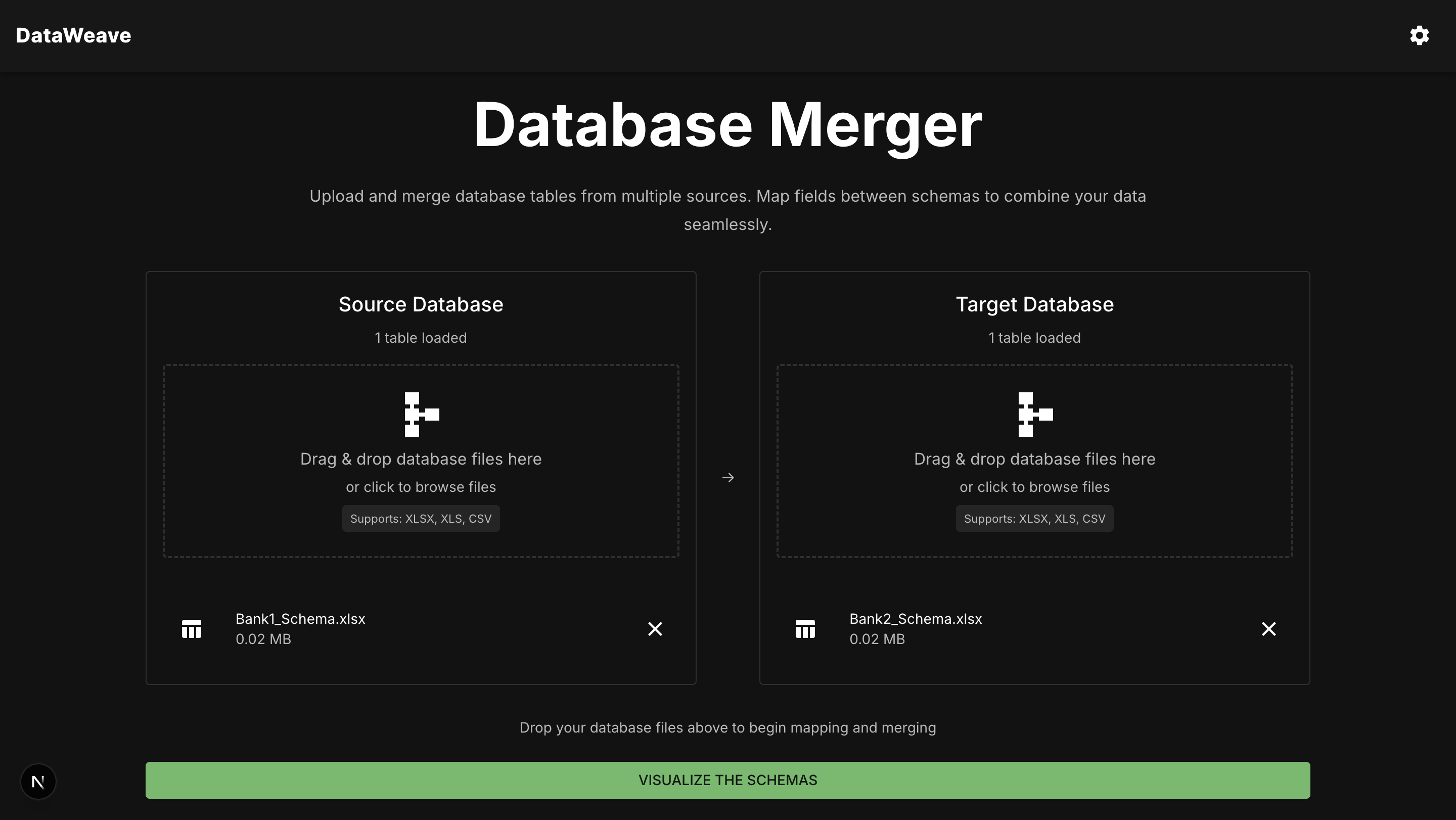
Dataset Upload - Add as many files as required with the database schema
-
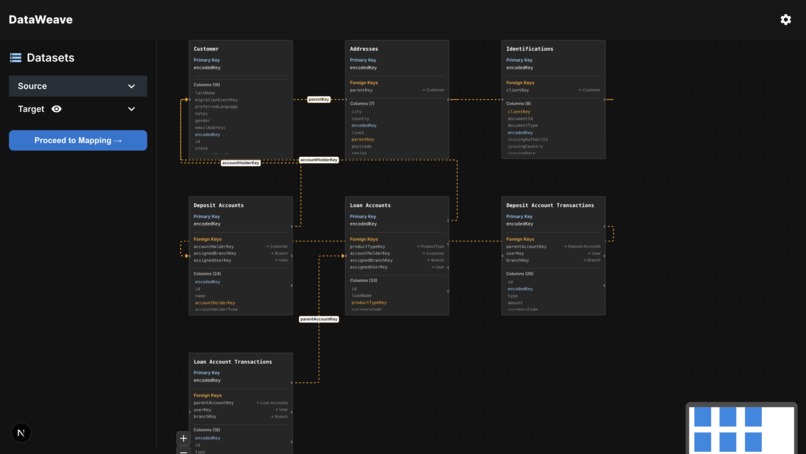
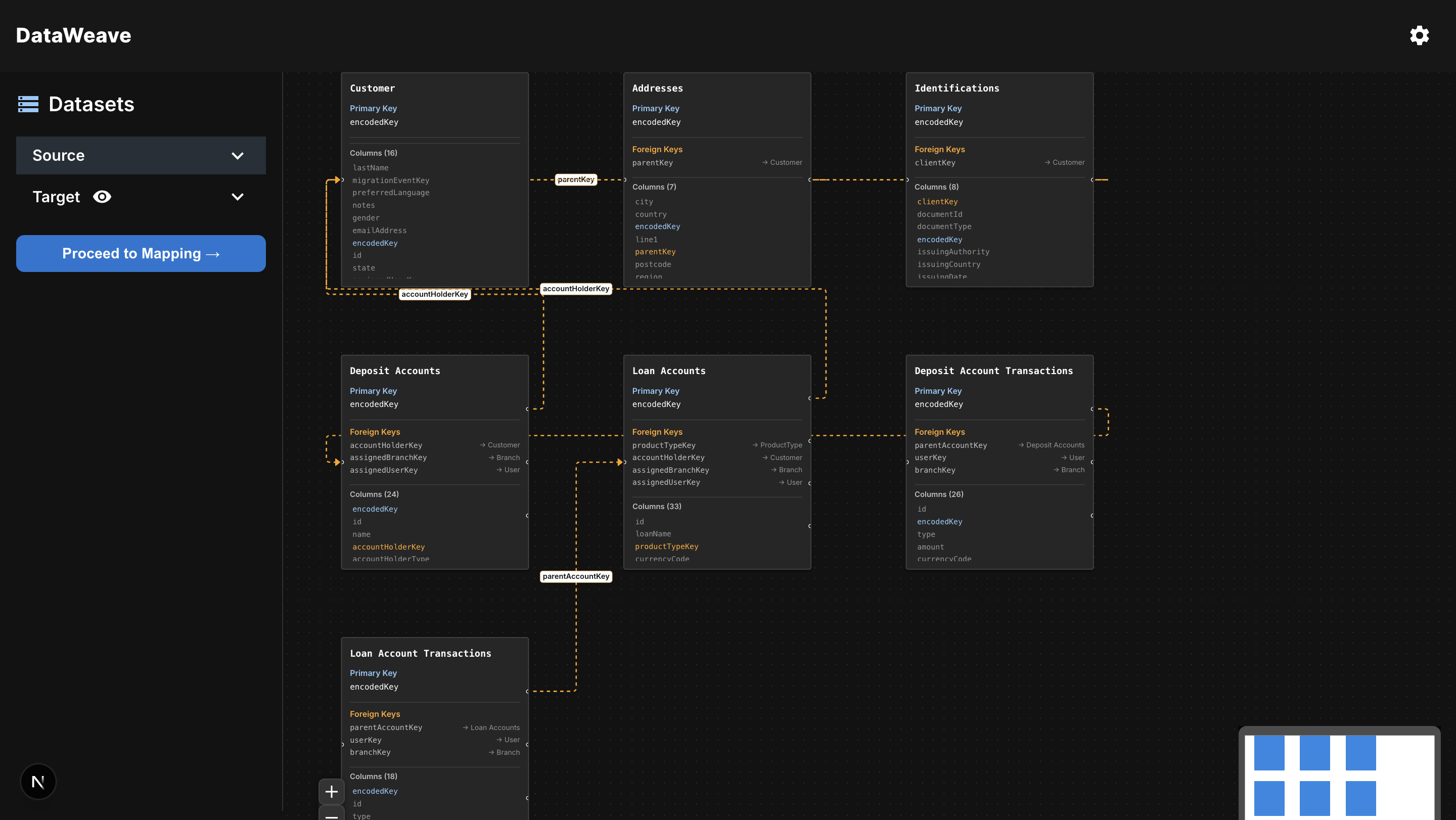
Interactive schema visualizer - drag and explore relationships detected within a database schema.
-
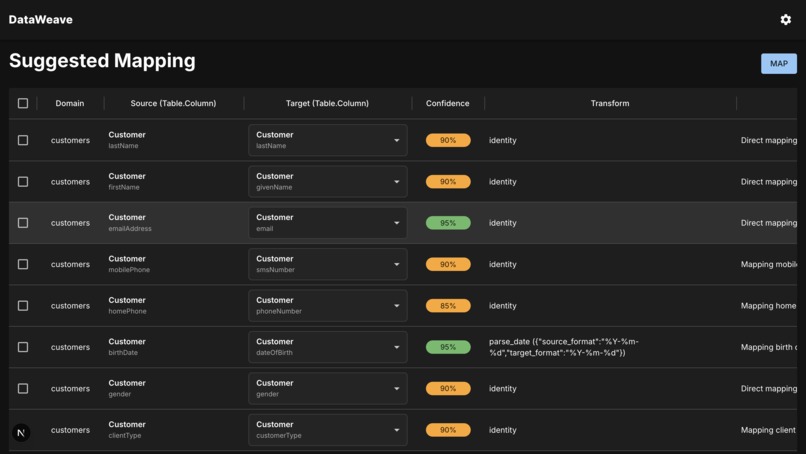
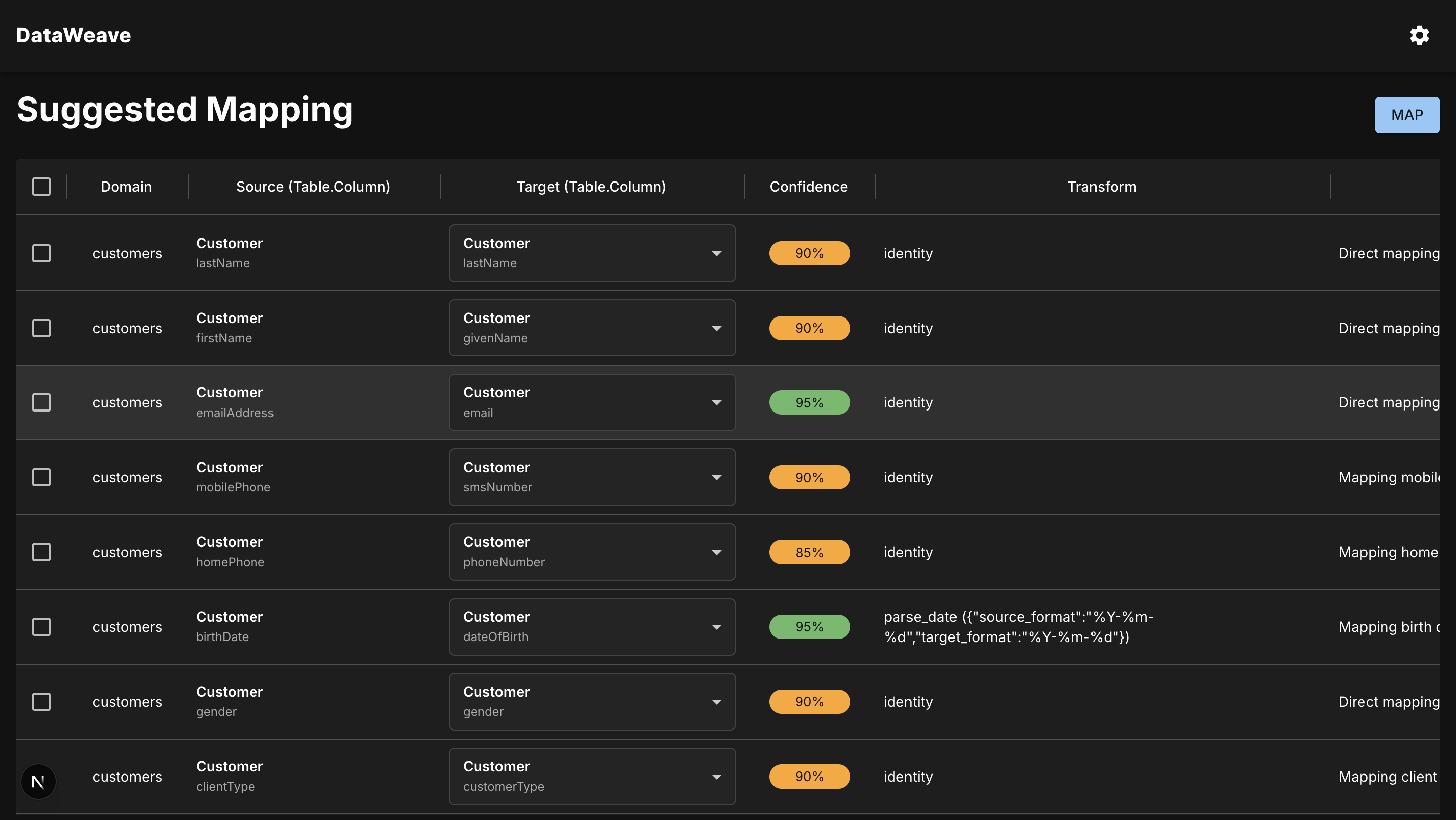
Suggested Mapping interface - view and adjust field alignments between source and target databases with AI-generated confidence scores.
Inspiration
DataWeave was born out of a frustration that every data engineer, analyst, or consultant has faced — dealing with messy, inconsistent, and disconnected data sources.
We realized that while many companies invest in data warehouses and ETL tools, the human-in-the-loop experience- where analysts can see, understand, and guide AI-driven transformations- is missing.
Created for the EY Data Integration Challenge at Hack The Valley X, We wanted to build something that feels as intuitive as Microsoft PowerApps or Notion, but with the intelligence of Gemini and OpenAI models, and the flexibility of Supabase and cloud storage.
What it does
DataWeave is an AI-assisted data integration platform that helps organizations merge, clean, and validate messy datasets - without losing control or transparency.
Users can upload a folder full of Excel or CSV files along with a schema file. DataWeave automatically reads and visualizes all the files, identifies relationships between them (like common IDs or foreign keys), and assists in mapping one dataset to another - even if one is normalized and the other isn’t.
At every step, the user stays in charge: they can tweak schema mappings, validate inferred relationships, and review AI-suggested transformations before finalizing. Once done, DataWeave outputs a clean, unified dataset as a folder of structured CSVs or Excel sheets, along with a new schema file describing all relationships and data integrity rules.
How we built it
Frontend: Built with React + Tailwind, users can drag and drop datasets, visualize table schemas, and inspect inferred relationships. Backend: FastAPI, Gemini API for semantic understanding - interpreting schema files, identifying column correspondences, and suggesting mappings across datasets. Processing: Python (FastAPI + Pandas) parses and processes Excel/CSV files, validates formats, normalizes data, and merges relational tables intelligently. Output: The backend exports a clean, validated folder of merged CSVs/Excel files plus a newly generated schema file describing the unified data model.
Challenges we ran into
Schema differences: Some datasets were normalized while others weren’t, making relational mapping and data merging complex. AI interpretation: Getting the AI to correctly understand schema intent and column relationships required fine-tuning the prompts and context. Balancing automation with human oversight: We didn’t want a “black box.” Giving users full control over each transformation step while keeping it simple took several design iterations.
Accomplishments that we're proud of
Built an end-to-end pipeline that can take raw folders of messy data and produce clean, structured datasets. Designed a visual interface that makes schema relationships understandable - even for non-technical users. Created an AI-assisted schema inference workflow that intelligently finds relationships without requiring explicit joins. Balanced AI automation with human control, allowing transparency and trust in every data transformation step. Added Data Cleaning algorithms to further improve the quality of the data going into the new dataset
What we learned
We learned how powerful AI becomes when combined with human judgment in data workflows. While AI can infer relationships and clean data faster than any human, the user’s ability to validate and tweak those results is what makes the output reliable.
What's next for DataWeave
Deeper AI Integration: Enhance the schema inference layer using large context Gemini models for multi-table reasoning. Smart Validation Rules: Automatically detect data quality issues and propose fixes. Connectors for Snowflake, BigQuery, and APIs: Expand DataWeave to handle not just files but live data sources. Team Collaboration: Enable shared workspaces for data engineers and analysts to collaborate in real-time.


Log in or sign up for Devpost to join the conversation.