-
-
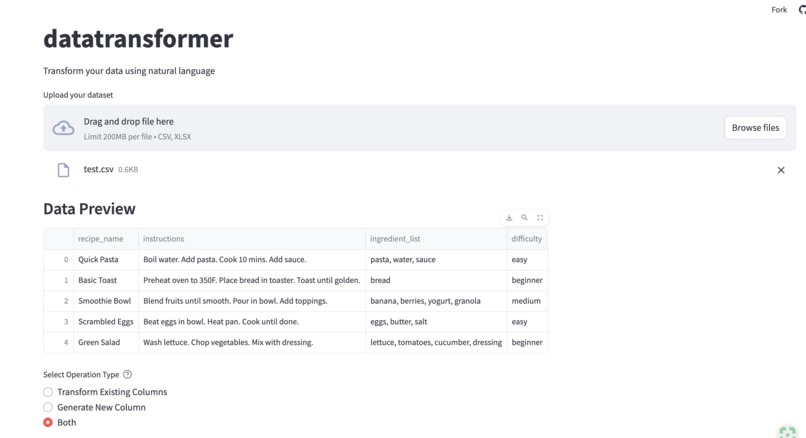
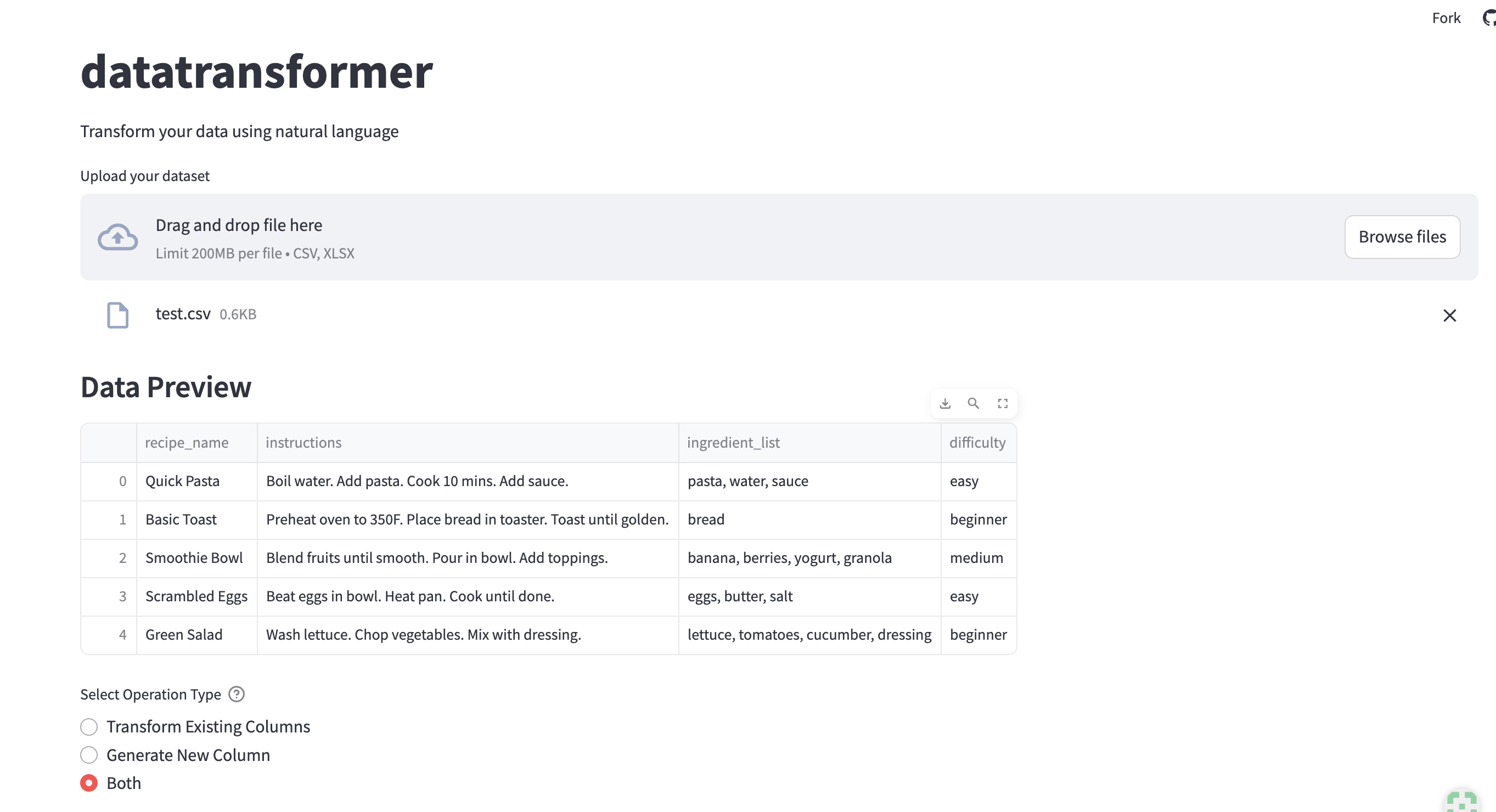
Drag or browse files you want to transform or generate new information
-
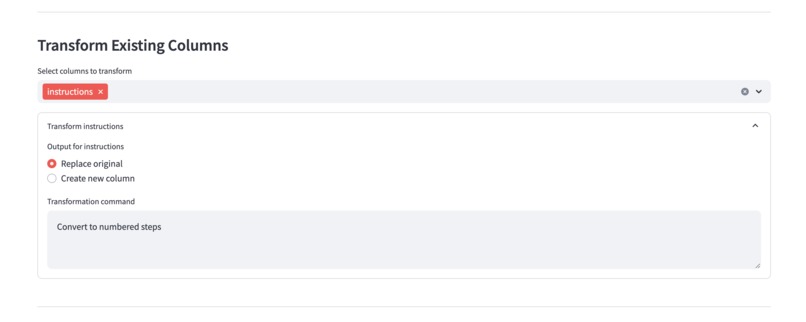
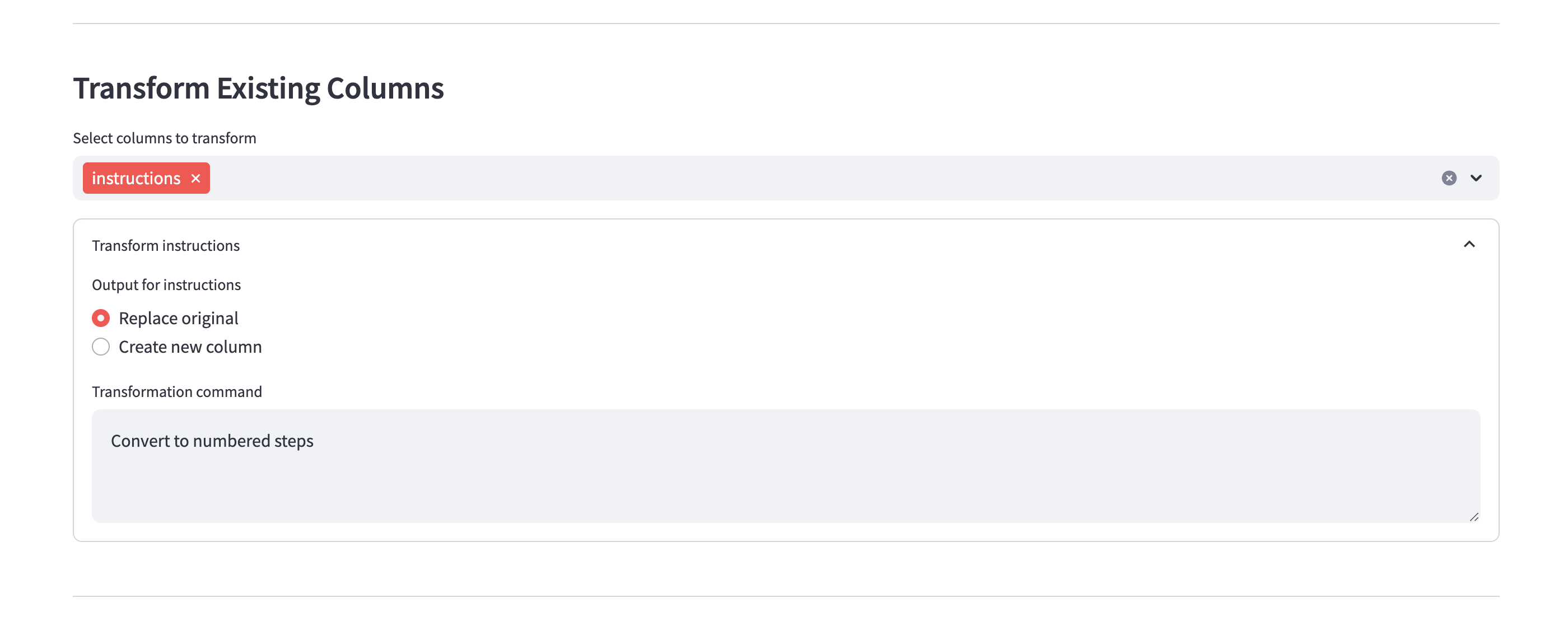
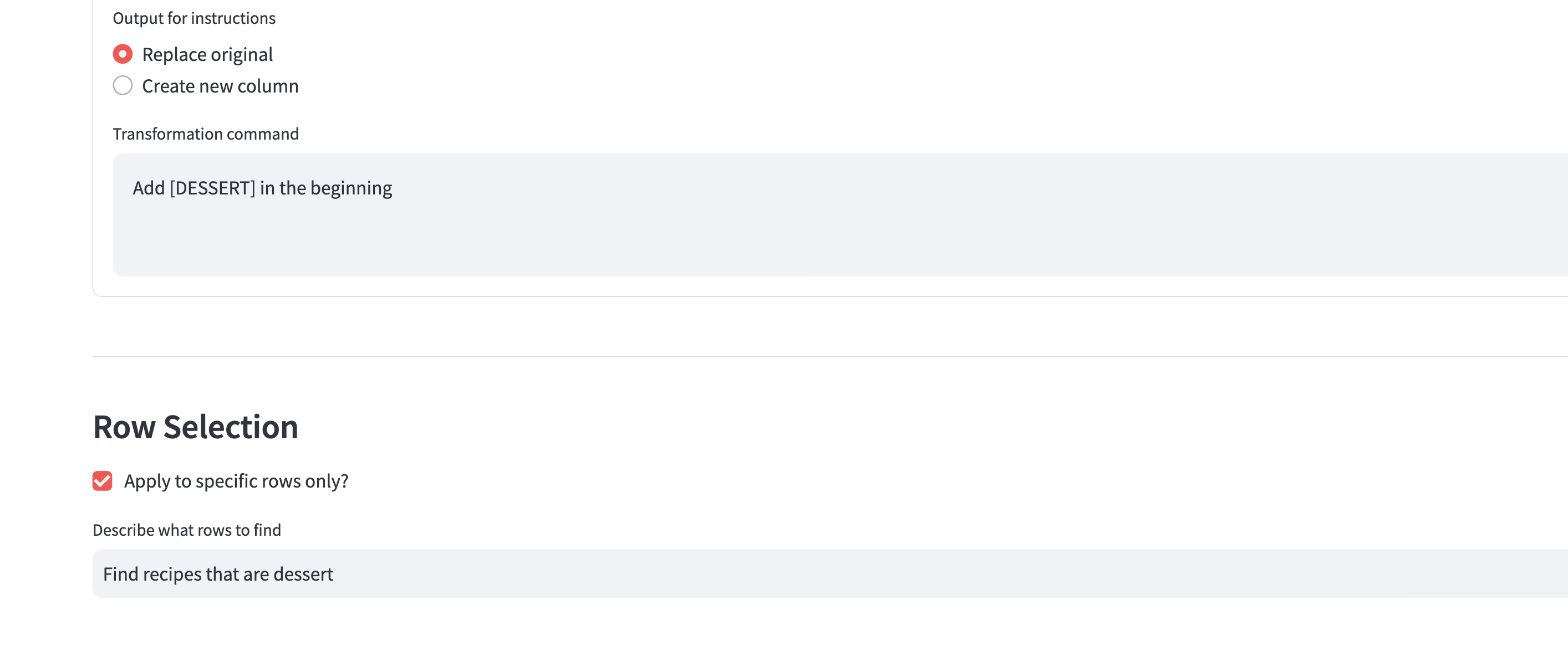
Transform existing column to your desired output based on the original data
-
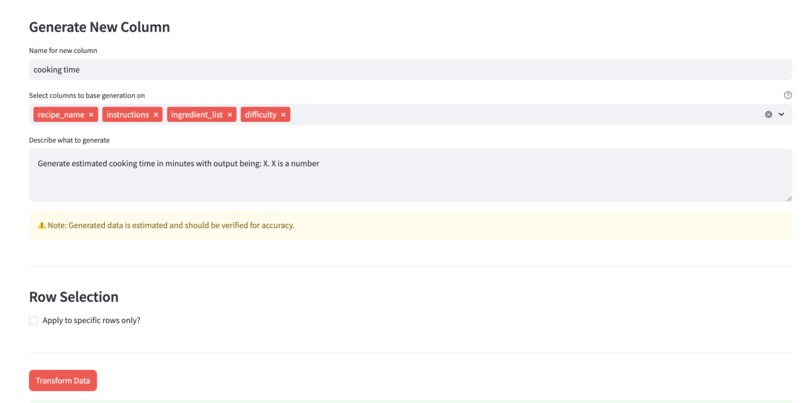
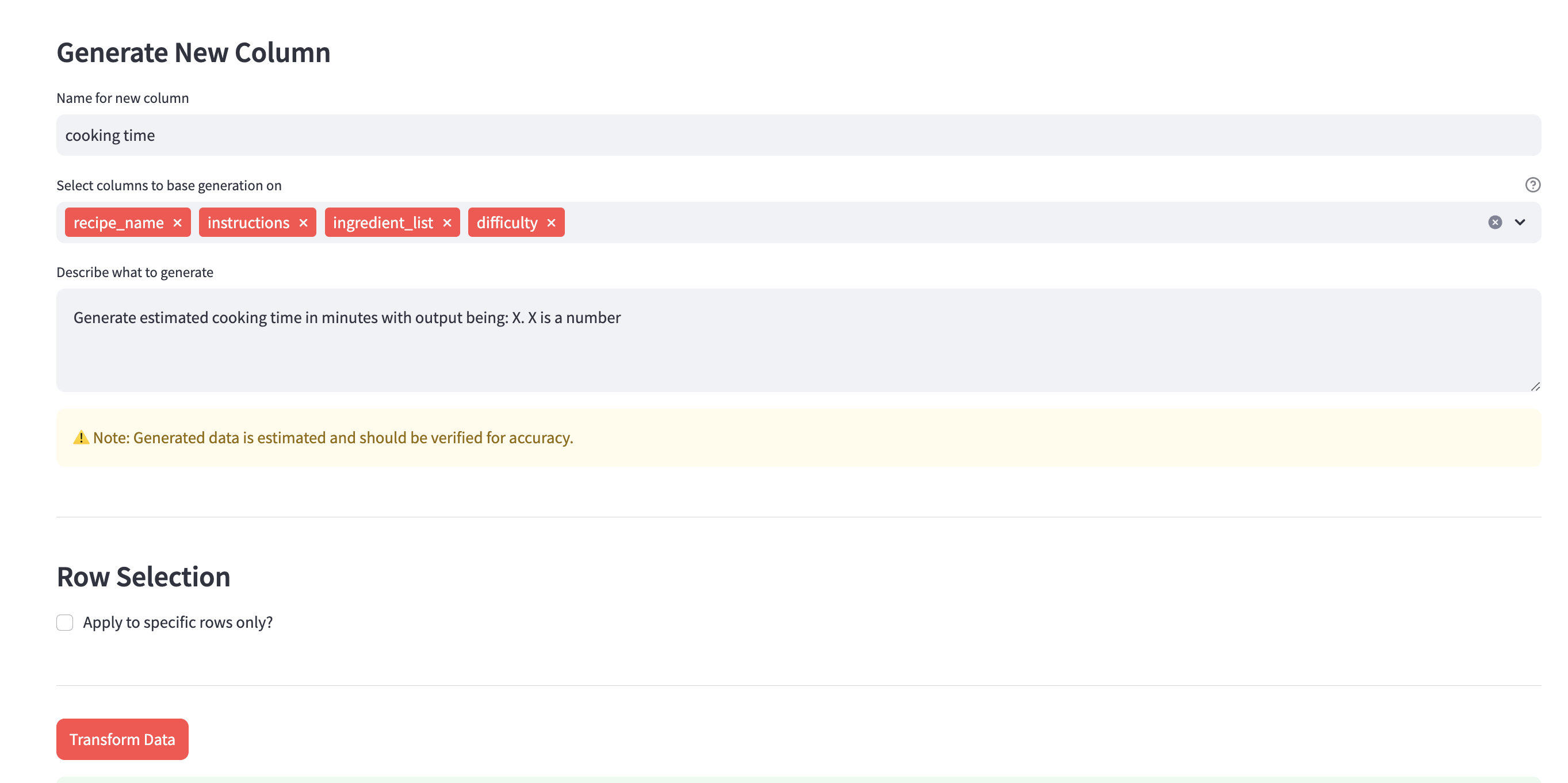
Generate a new column using the context of the selected column in your dataset
-
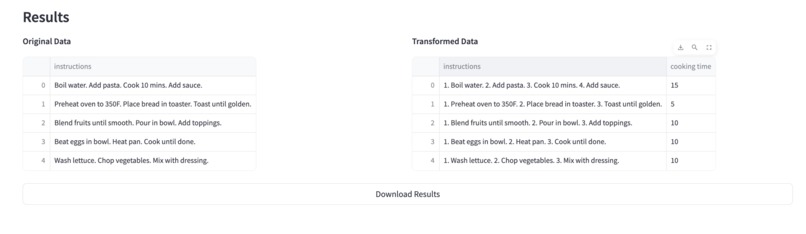
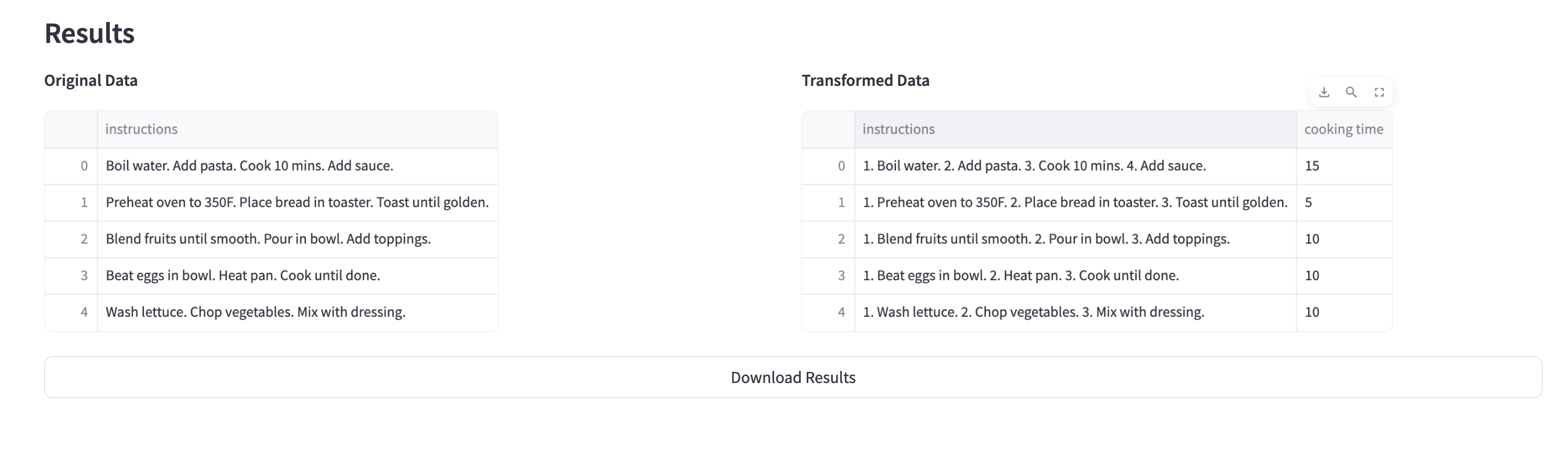
See the preview of the transformed column and download the dataset
-
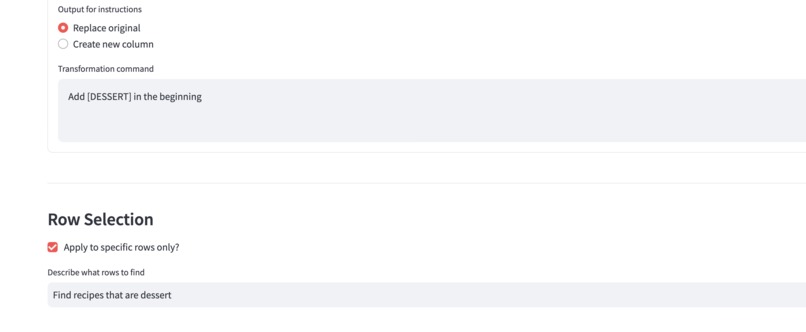
(Optional) Transform only selected rows based on natural language
Inspiration
As developers, I often encounter public datasets that are almost perfect for our needs, but not quite. Imagine finding a great recipe dataset, but realizing you need to add complexity ratings, estimated cooking times, or dietary categories. Traditional approaches would require writing complex code or manual labeling - both time-consuming and inconsistent. Furthermore, some datasets can be messy. Imagine these scenarios: product descriptions with mixed formats and incomplete information or log entries needing standardization and categorization.
I realized that while many projects focus on natural language to SQL (which helps query data), there's a gap in actually enriching and transforming the data itself. What if we could use AI not just to query data, but to understand it deeply enough to generate new insights and transformations?
What it does
This is where DataTransformerAI comes in - it's not about querying existing data, it's about intelligently enriching it. By combining Snowflake's Mistral LLM with distributed processing, we can analyze context across multiple columns to generate new, meaningful data that wasn't explicitly present in the original dataset. Furthermore, it can transform your old data into your desired output (even filter rows using human-like search criteria). I also ensure that data integrity is maintained and that the transformed or newly generated data is as close as possible to the ground truth of the actual data itself.
How I built it
I architected the solution with three main components:
- Frontend Layer: Built with Streamlit for an intuitive user interface
- Processing Layer: Implemented distributed processing using Redis for scalability
- AI Layer: Leveraged Snowflake's Mistral LLM for natural language understanding and data transformation The system uses a distributed architecture where tasks are split into chunks and processed in parallel, with results aggregated back to provide a seamless user experience.
Challenges I ran into
- Learning to utilize various technologies of the Snowflake platform and Streamlit deployment (my first time encountering both)
- While Redis runs locally and provides 3x faster processing, deployment costs were a consideration so I didn't deploy it. I implemented a fallback to single processing with batch operations for deployment. As a result, the deployed version processes large datasets very slow (500 rows takes 15 minutes).
Accomplishments that I am proud of
- The app successfully executes natural language commands for data transformation
- Learned to use new tools: Snowflake Cortex, Mistral-large2 LLM, and Streamlit for UI
- Gained experience with distributed processing (even though it's not in the deployed version)
- Created a tool I can use for other projects (I'm currently building a recipe recommendation app and need to transform data) - doing this manually would be time-consuming, and SQL alone isn't powerful enough
What I learned
- My first solo hackathon wasn't as daunting as I anticipated
- Tool Integration: Gained firsthand experience in leveraging Snowflake Cortex, Mistral LLM, and Streamlit, expanding my technical capabilities with new platforms and tools
- Distributed Systems: Developed an understanding of implementing and optimizing distributed task processing, including managing bottlenecks and ensuring reliability in task aggregation (though the deployed version isn't distributed)
What's next for DataTransformerAI
- Support more formats (including non-relational like JSON)
- Enable combining datasets to generate data that relies on ground truth from multiple sources
- Improve scalability and processing speed
- Implement transformation history tracking

Log in or sign up for Devpost to join the conversation.