-
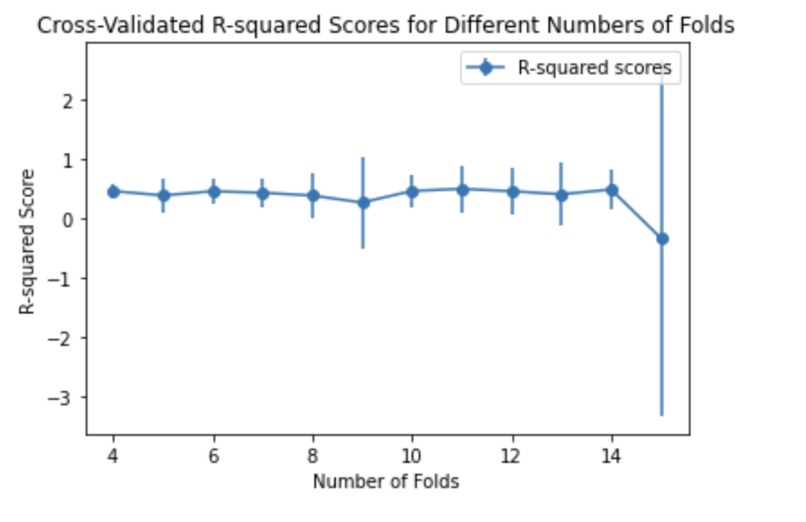
This graph shows the Gradient Boosting Regressor model performs the best at 11 folds.
Inspiration
Our model is inspired by a decision tree. We used an improved version of the model which has higher accuracy and less bias.
What it does
The model predicts the company's domestic sales. We use cross-validation to choose the number of splits for our decision tree such that the R squared value is nearest to one.
How we built it
We used python packages such as pandas, scikit learn and matplotlib.
Challenges we ran into
The domestic and global sales are highly correlated, which might affect the accuracy of our model.
Accomplishments that we're proud of
By trying to fit different categories of data into the model, we chose the set of categories that can predict the firms' domestic sales the best.
What we learned
New ways to clean the data more effectively and alternatives when dealing with NA value data. We also learned how to deal with categorical data more effectively such that it gives us more insights.
What's next for datastrong
We can further explore on other data analytics models such as neural network to improve the accuracy of our model.
Built With
- jupyter
- python

Log in or sign up for Devpost to join the conversation.