Inspiration
As AI agents like ChatGPT, Claude, Gemini, and Copilot become embedded in daily workflows, users increasingly paste sensitive data, SSNs, addresses, emails, internal company information, into prompt boxes without realizing the long-term implications.
We faced a core dilemma: Productivity vs. Privacy
Existing redaction tools often send data to another server for processing-which defeats the purpose of privacy.
We wanted a solution that:
- Runs 100% locally
- Requires zero trust in third-party servers
- Integrates seamlessly into AI workflows
That vision became DataShield.
What it does
DataShield is a Chrome Extension that acts as an intelligent privacy layer for ChatGPT, Gemini, Copilot, and Claude.
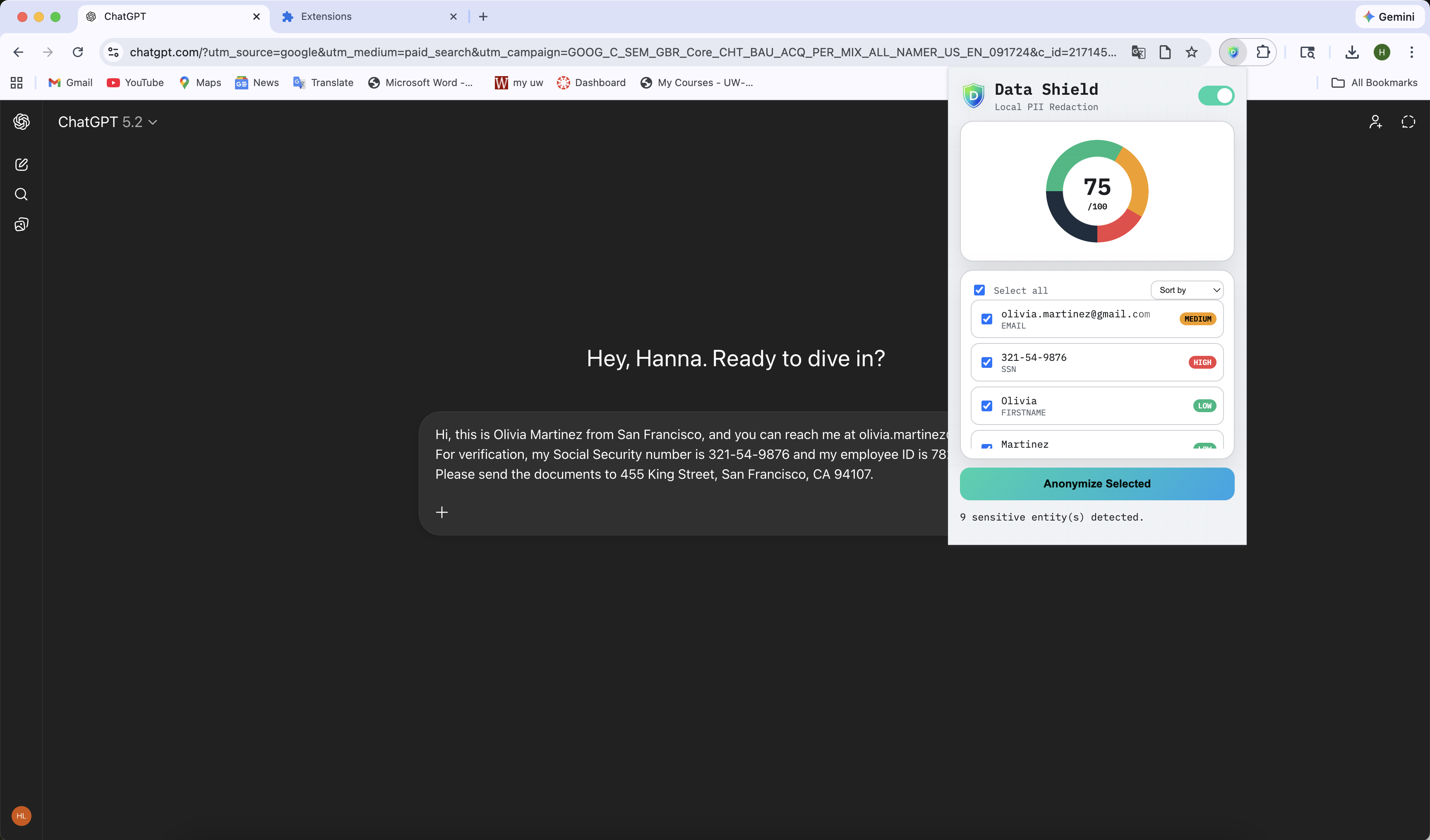
When a user types into an AI prompt box, DataShield provides:
🔎 Total Risk Score: An aggregated risk metric computed from detected PII entities. 📋 Granular Detection: A categorized breakdown of all detected Personally Identifiable Information, including risk level per entity type. 🎛 Selective Masking: Users can choose exactly which detected data points to redact.
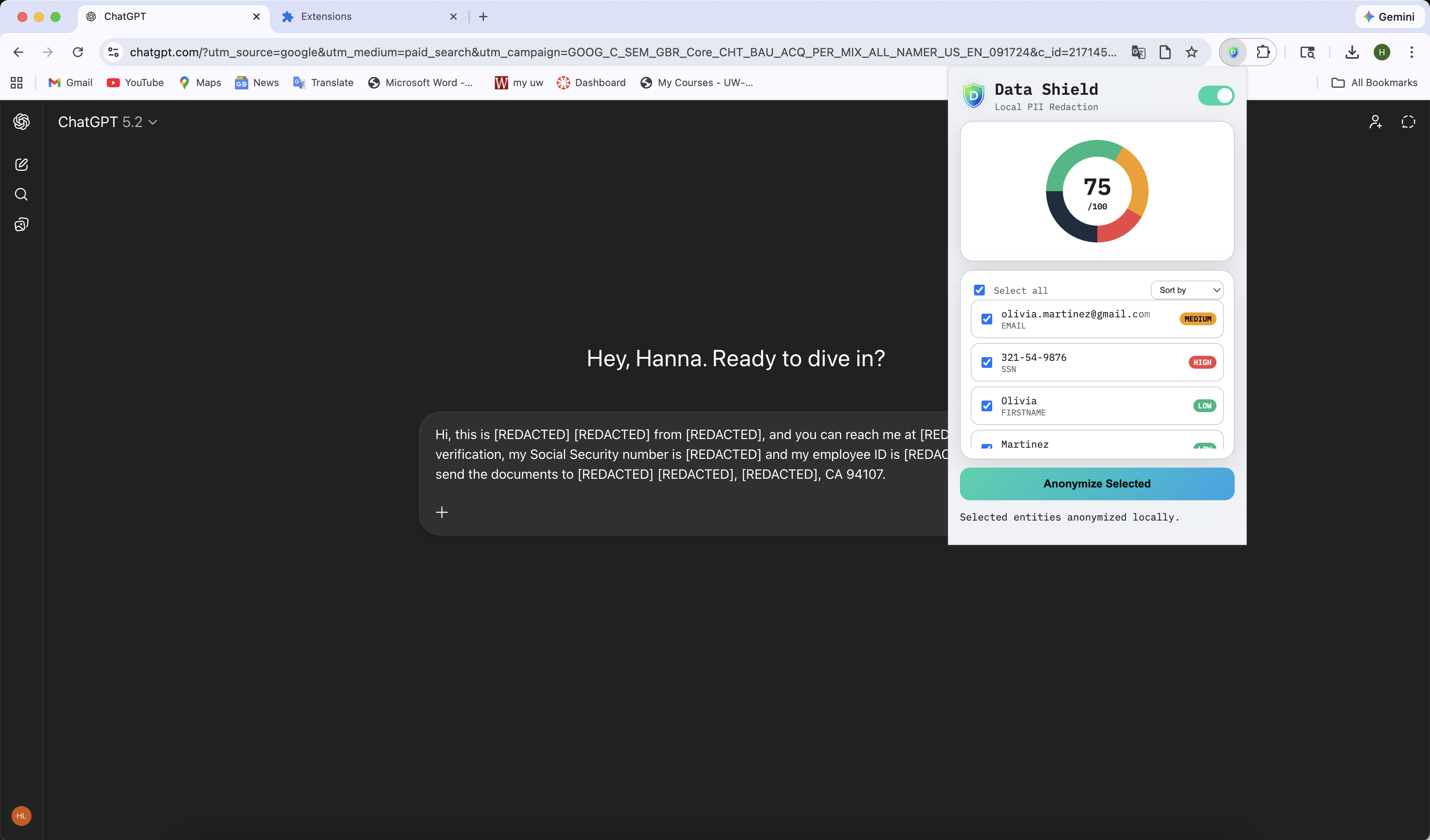
With one click, sensitive text is replaced with masked tokens-before the data leaves the browser.
How we built it
We followed a structured three-stage architecture:
1️⃣ Fine-Tuning the Detection Model To keep inference lightweight and browser-compatible, we chose DistilBERT (distilbert-base-cased) and fine-tuned it for Named Entity Recognition (NER).
Dataset: ai4privacy/pii-masking-200k Subset size: ~20,000 high-quality samples GPU: T4 on Google Colab Target metric: F1 > 0.9
The result was a 54-class PII detection model optimized for contextual understanding.
2️⃣ Extension Development We developed a Manifest V3 Chrome extension featuring:
- Robust content scripts
- Dynamic interaction with modern AI prompt text areas
- A popup UI with real-time entity classification and risk visualization
3️⃣ ONNX-Based Browser Inference To run inference locally in-browser:
- We converted the trained model to ONNX
- Used in-browser execution via ONNX runtime
- Implemented IOB (Inside-Outside-Beginning) tagging logic
- Combined regex + model inference: Transformer → unstructured data, Regex → structured data (e.g., SSNs, phone numbers)
We also built custom token-stitching logic to resolve subword splits (e.g., App + ##le → Apple) without breaking PII classification.
Built With
- chrome
- distilbert
- javascript
- ner
- python
- transformers
- typescript
 Kim")


 Kim")
Log in or sign up for Devpost to join the conversation.