-
-
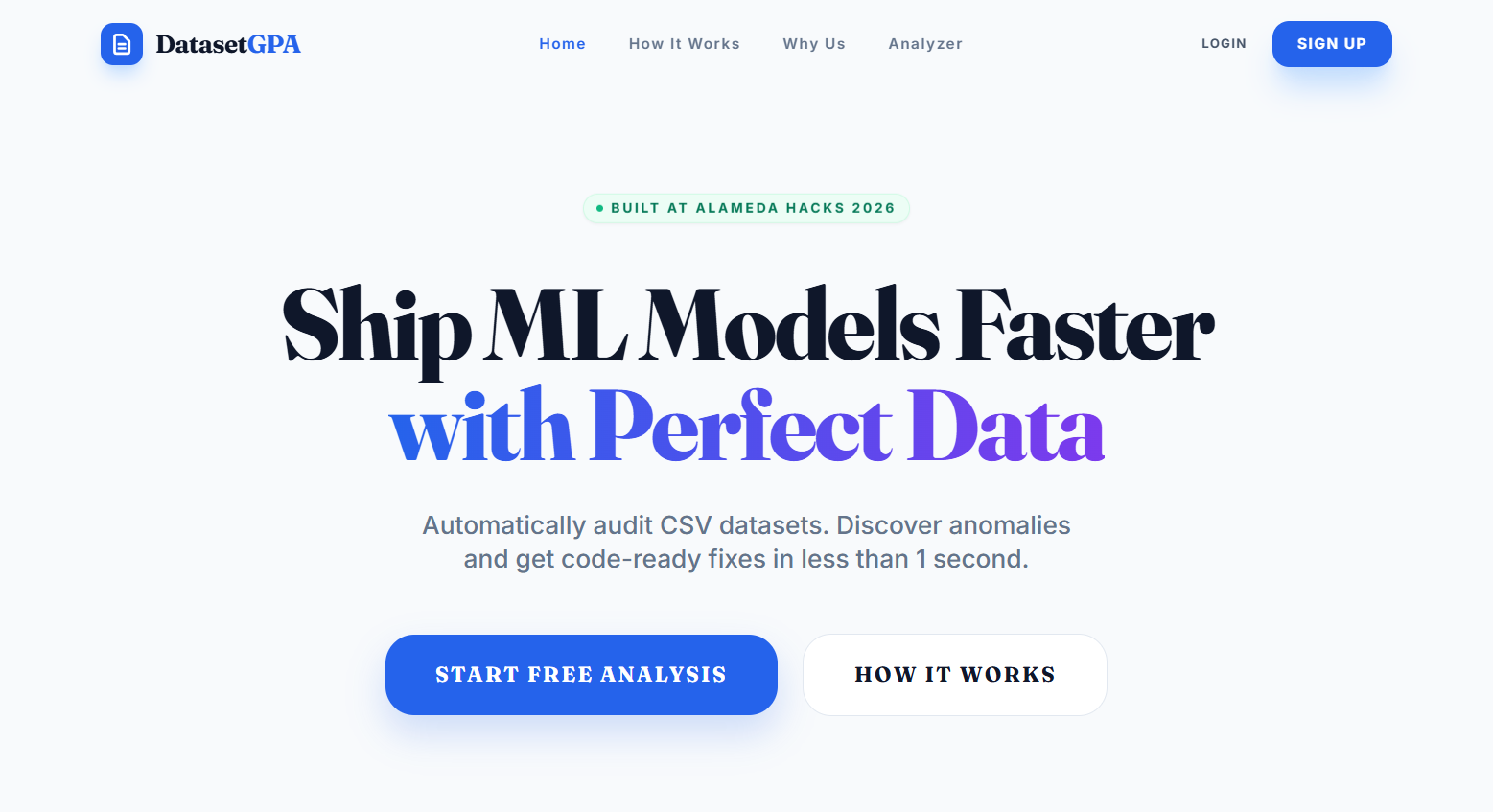
DatasetGPA landing page
-
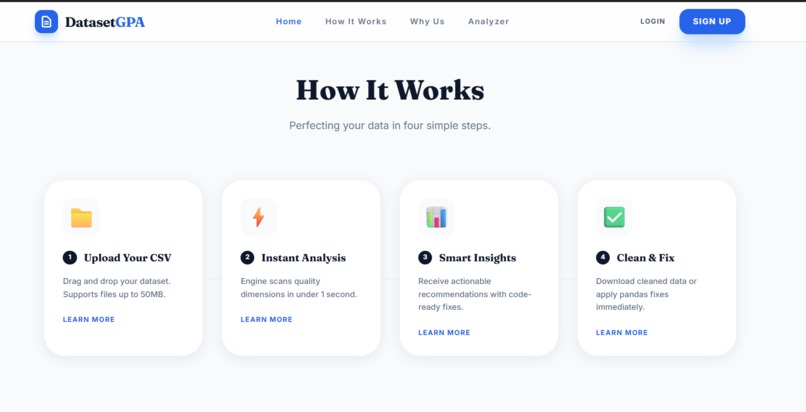
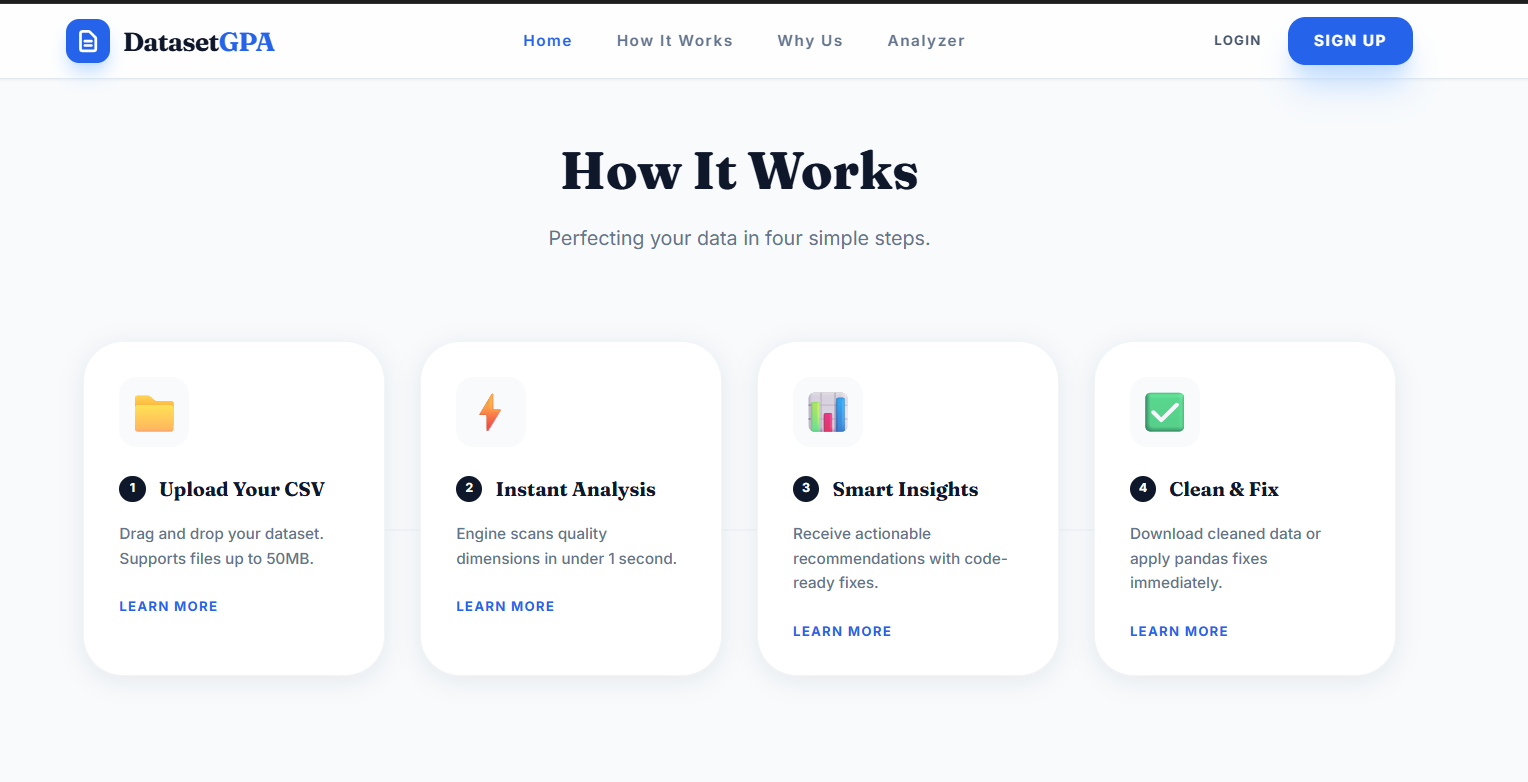
How It Works
-
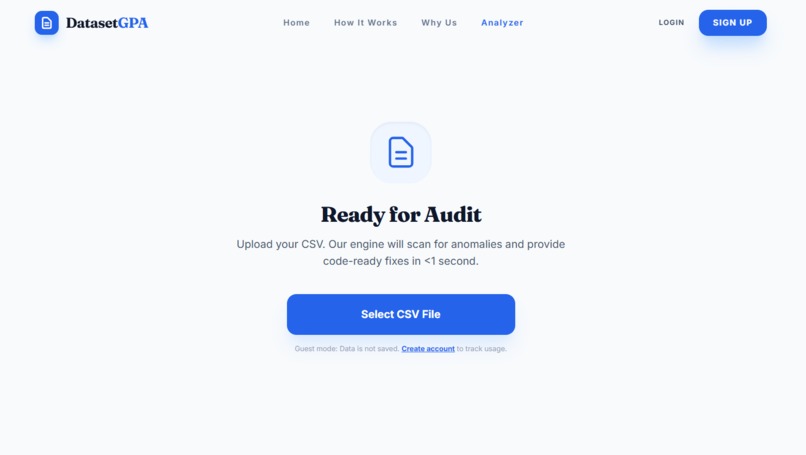
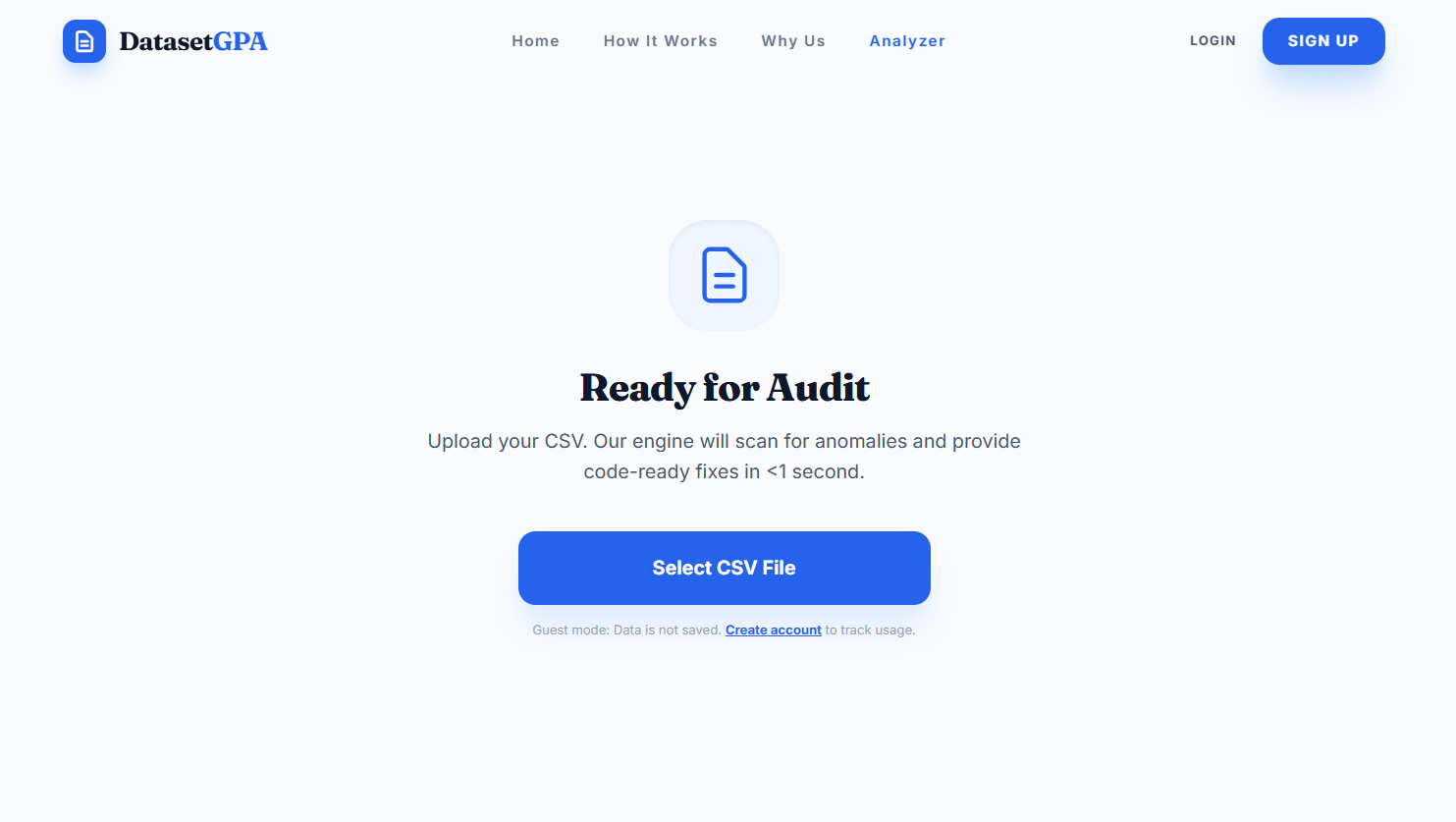
Dataset Upload Interface
-
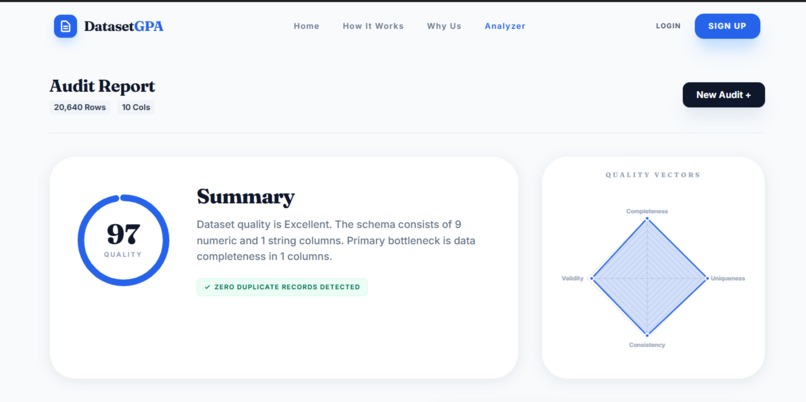
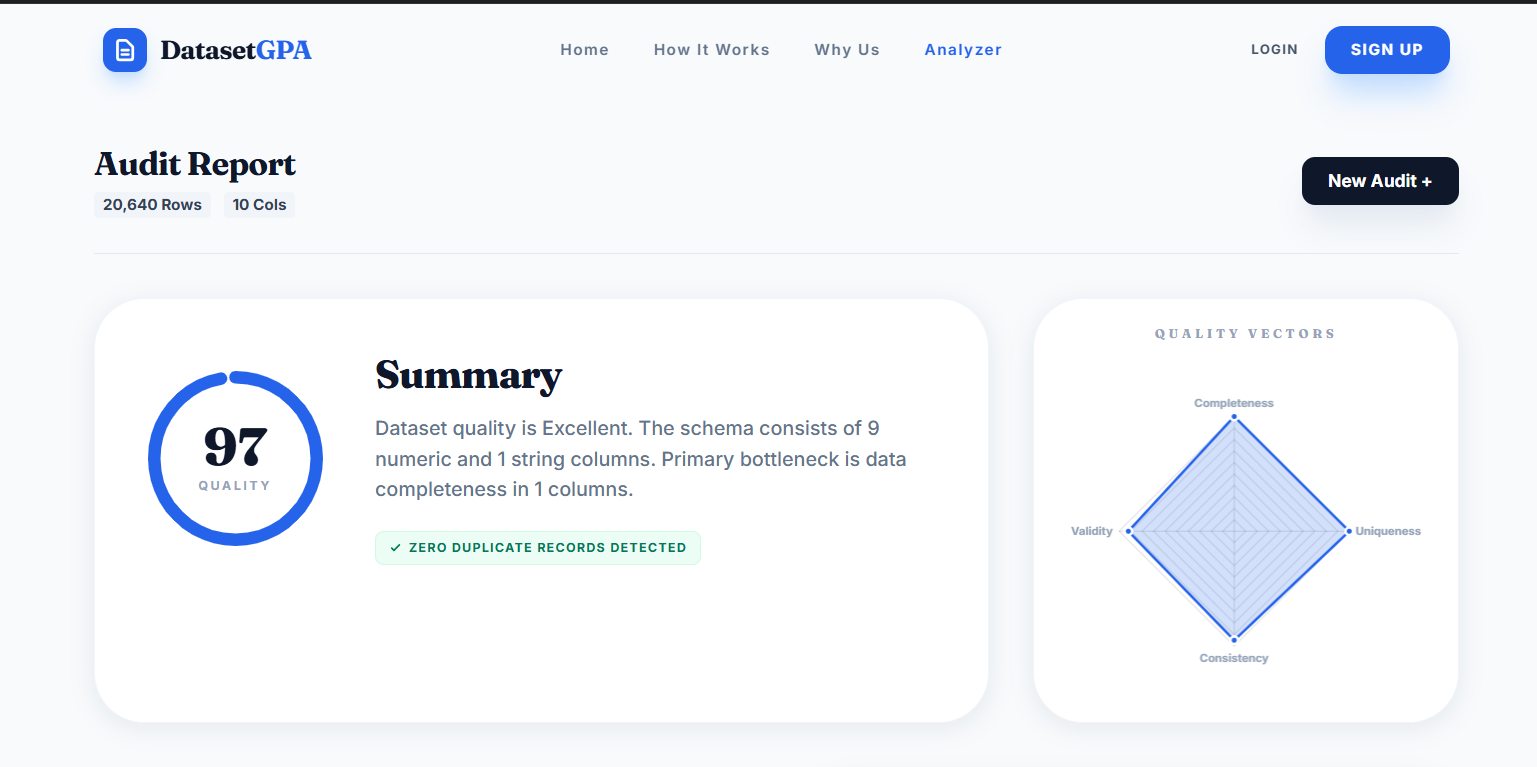
Analysis Results - Health Score
-
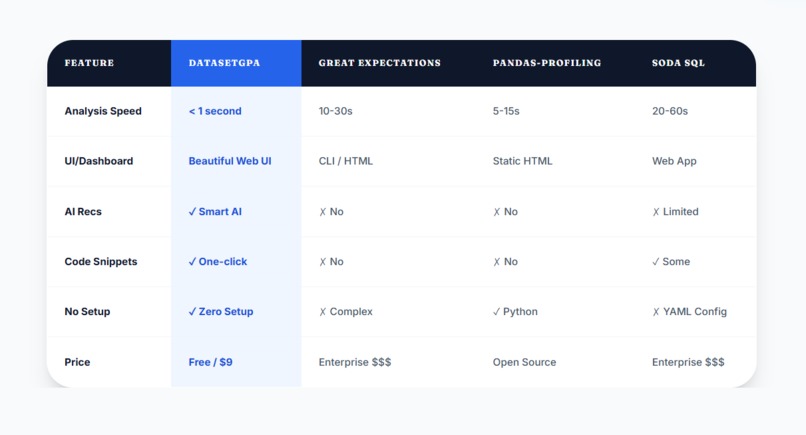
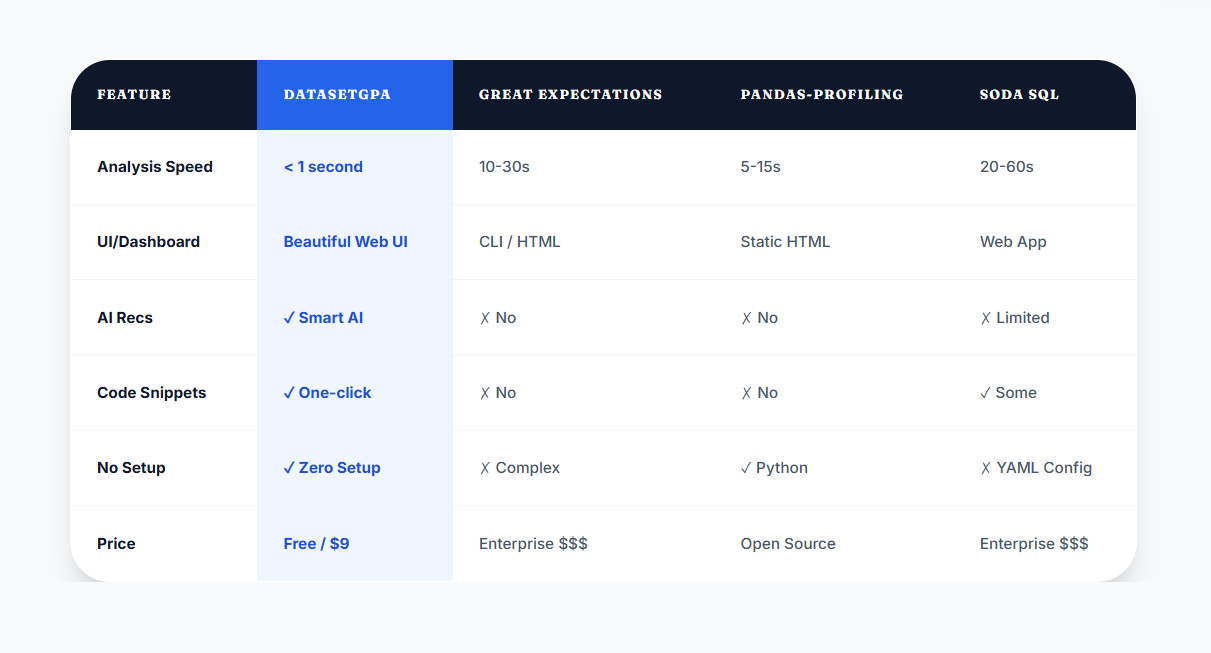
Why Us Comparison Page
The Problem
As a machine learning engineer, I've wasted countless hours debugging datasets that should've been flagged immediately. Missing values, class imbalance, data leakage, outliers - these issues cause model failures and wasted compute. The real kicker? I often don't catch them until after training.
The Solution
DatasetGPA is a browser-based tool that instantly analyzes your CSV datasets and tells you exactly what's wrong - before you waste time training. It detects:
- Missing Values: Column-by-column missing data patterns
- Outliers: IQR-based outlier detection for numeric features
- Class Imbalance: Identifies severe class distribution problems
- Data Leakage: Flags suspicious column names and duplicate columns
- Health Score: 0-100 score showing overall dataset quality
The best part? It works 100% in your browser - just drag, drop, and analyze.
How I Built It
Tech Stack:
- React + Babel (from CDN)
- Papa Parse (CSV parsing)
- Tailwind CSS (beautiful UI)
- Claude API (AI-powered recommendations)
Key Features:
- Drag & drop CSV upload
- Real-time analysis engine
- Interactive health score display
- AI-generated actionable recommendations
- Export analysis as markdown
What I Learned
- Data quality is underestimated - Most ML failures trace back to dataset issues, not model architecture
- Browser-based tools are powerful - CDN libraries + client-side processing = instant results with zero backend
- Claude API is amazing - Transforming raw statistics into human-readable insights is game-changing
- UI matters - Even the best analysis is useless if people can't understand it
Impact
- Saves 2-5 hours per dataset by automating quality checks
- Prevents bad model training by catching issues early
- Works for any ML team - no installation, no backend setup
- 100% privacy - your data never leaves your browser
What's Next
- Correlation heatmaps for feature relationships
- Automatic fixing suggestions (handle missing values, balance classes)
- Integration with Weights & Biases for tracking quality over time
- Support for larger datasets (streaming, chunked processing)
This project proves that data quality automation can be both accessible and intelligent - no PhD required, just upload and analyze.
Built With
- babel
- claude-api
- html5
- javascript
- lucide-react
- papa-parse
- react
- tailwind-css

Log in or sign up for Devpost to join the conversation.