-
-
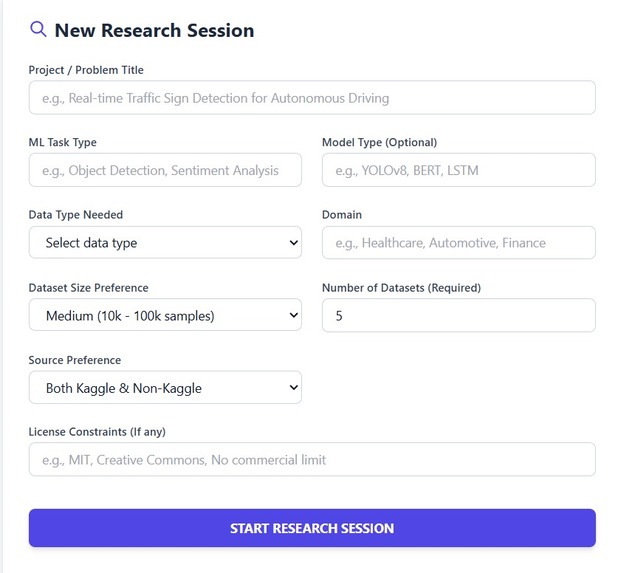
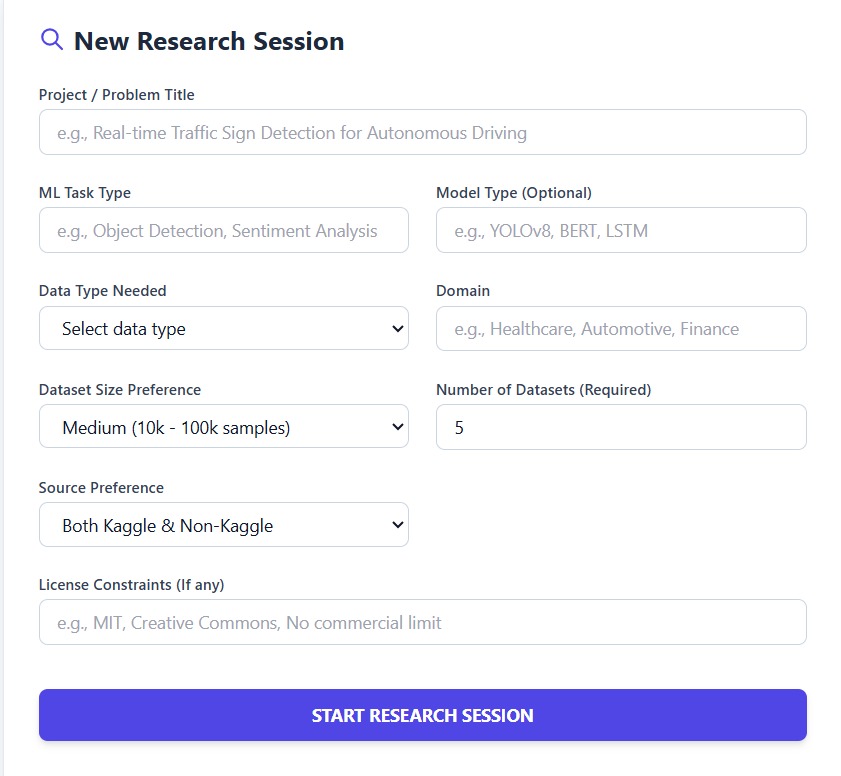
User Input Form
-
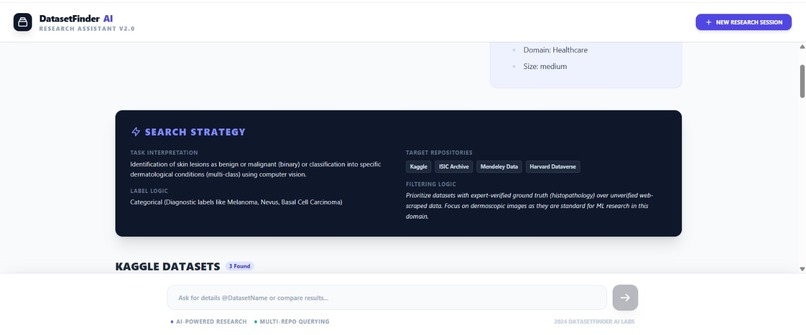
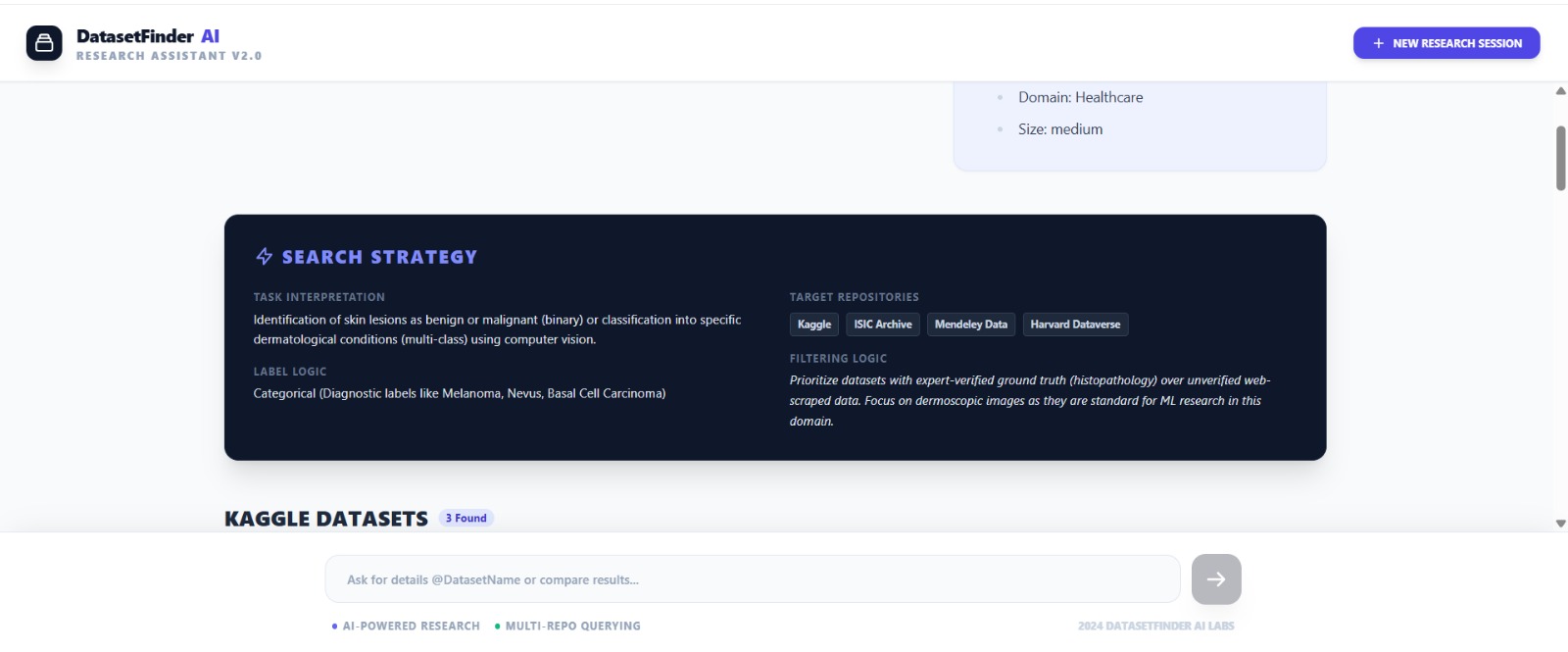
Search Strategy-Interface
-
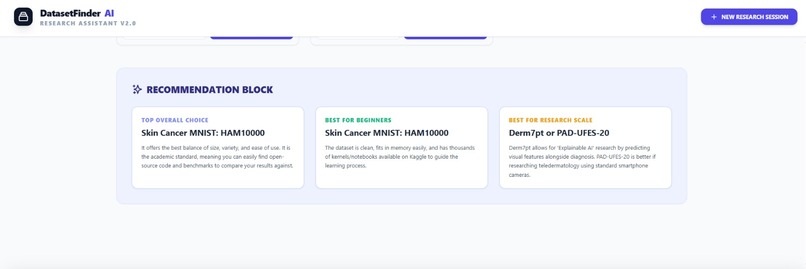
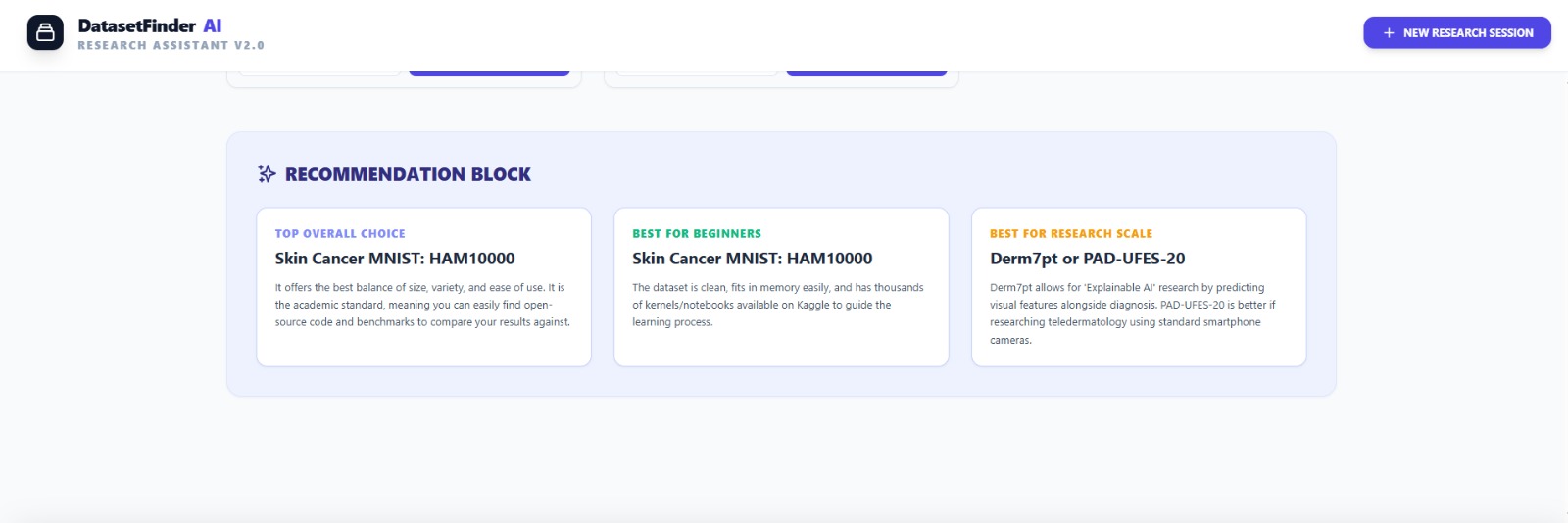
Recommendation Block
-
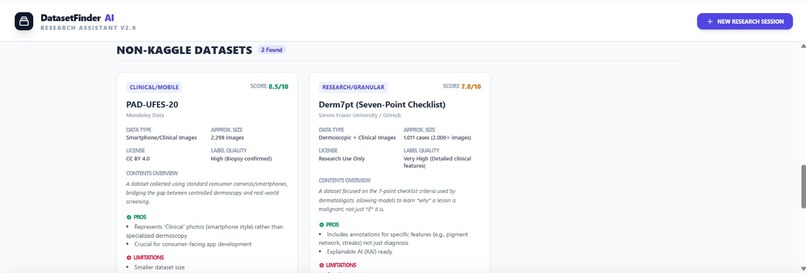
Other category of datasets output
-
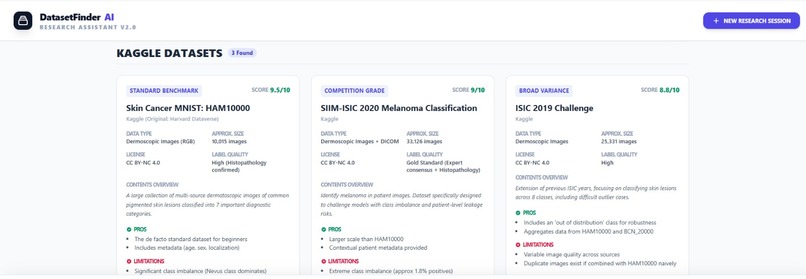
Datasets Results
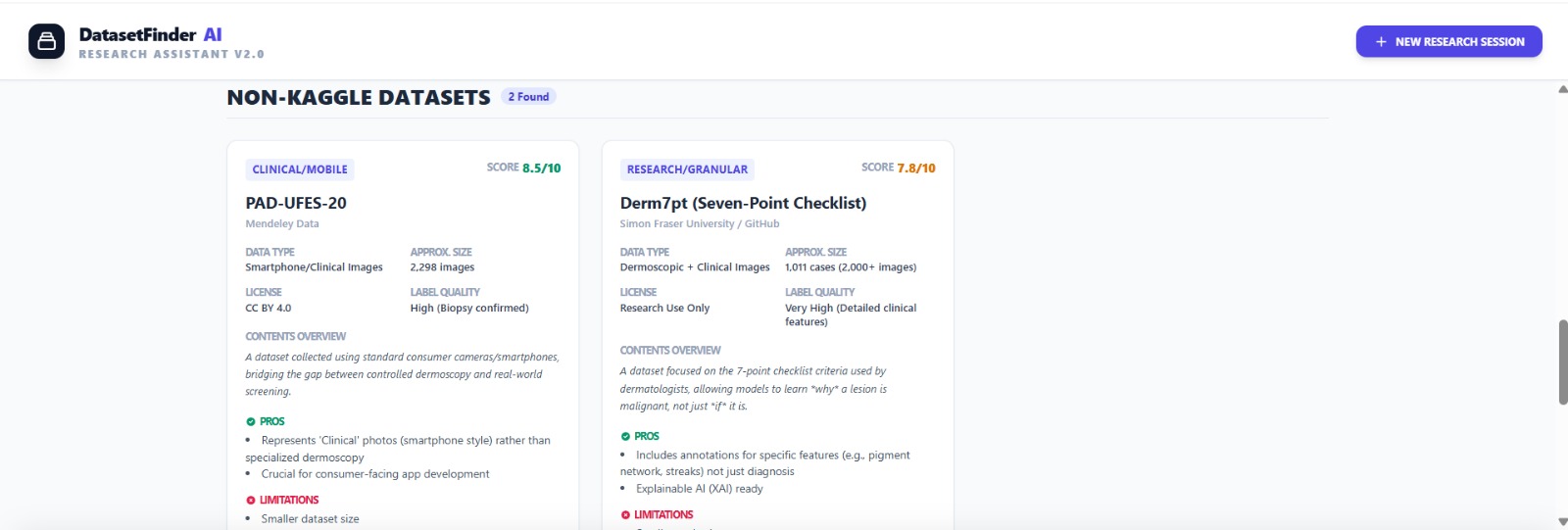
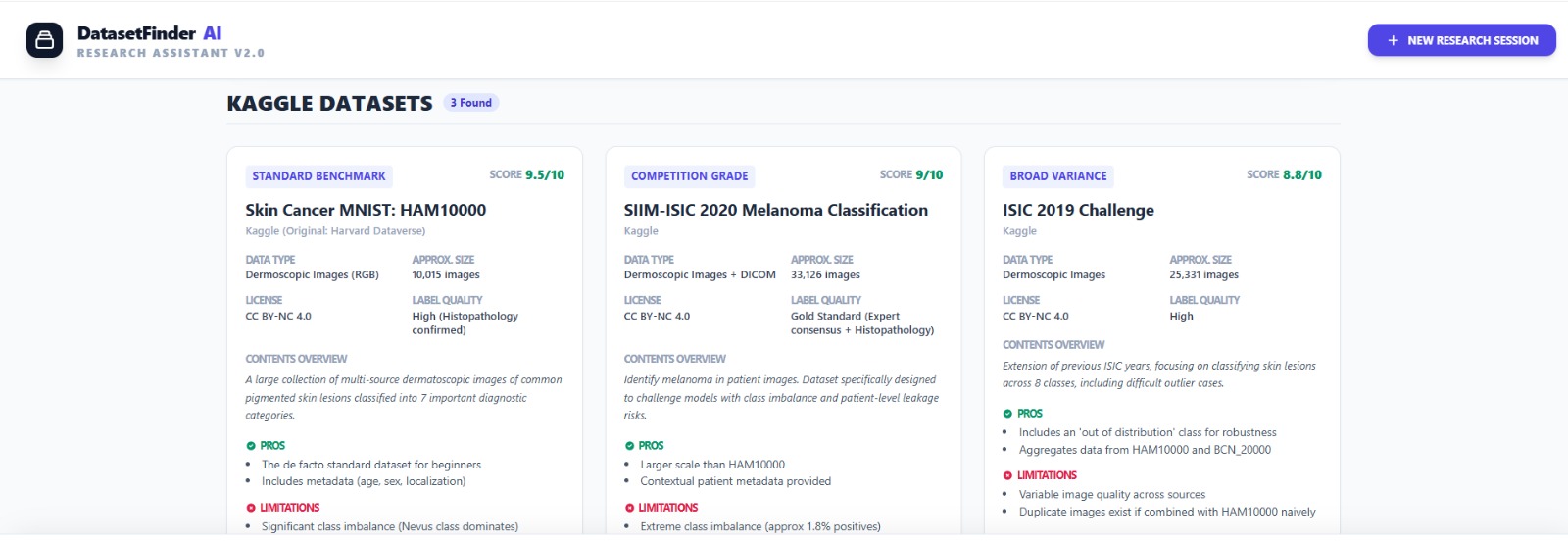
Inspiration
Students and Researchers often find difficult in finding datasets to train various Machine Learning models. These datasets will be spread in various platforms and sometimes users find difficult to search with the correct keywords. Finding of the dataset is the most important and crucial step for training any type of model.
What it does
User gives project/problem title, ML task type, data type needed, dataset size preference, number of datasets(required), then system searches whole internet and lists the datasets (kaggle and non-kaggle) along with details of it, pros and cons of it, with a rating of the dataset as well. It uses gemini for doing this. It also attaches source links for each dataset as well.
How we built it
We built DatasetFinder AI using Google AI Studio and the Gemini model as the core reasoning engine. The system prompt was carefully designed to make Gemini act as a dataset discovery expert that understands ML tasks, model types, and data requirements. We created a structured input flow where users provide project title, ML task type, dataset format, expected dataset size, and number of datasets required. Gemini then performs intelligent search-style reasoning to identify suitable datasets from Kaggle and non-Kaggle sources. We also implemented conversational follow-up features such as “Next Search” and dataset clarification queries using dataset tagging (@datasetName). The output is structured into categorized results with dataset descriptions, strengths, weaknesses, augmentation notes, and suitability ratings.
Challenges we ran into
One major challenge was prompt engineering — getting Gemini to consistently return structured dataset results instead of generic answers. We refined the prompts multiple times to enforce output format, dataset categorization, and evaluation criteria. Another challenge was handling diverse ML task types and dataset formats while keeping results relevant. We also worked on making the interface conversational while preserving previous search results without overwriting them. Managing API limits and optimizing prompt length for reliable responses was also a key challenge.
Accomplishments that we're proud of
We successfully built a working AI assistant that can intelligently suggest datasets instead of just listing search results. The system not only finds datasets but evaluates them with pros, cons, suitability scores, and usage guidance. We are proud that the tool separates Kaggle and non-Kaggle datasets, supports multiple dataset requests, and allows follow-up clarification questions using dataset tags. The conversational search flow makes dataset discovery faster and more user-friendly for students and researchers
What we learned
We learned how to design structured prompts for large language models to produce consistent and useful outputs. We gained hands-on experience with Gemini AI Studio, prompt chaining, and conversational flow design. We also learned how AI can be guided to perform domain-specific reasoning, such as evaluating dataset quality and suitability for different ML models. This project showed us the importance of prompt structure, response formatting, and user interaction design in AI-powered tools.
What's next for DatasetFinder AI
Next, we plan to integrate real-time dataset APIs and automated dataset validation metrics such as class balance, annotation quality, and data leakage checks. We also plan to add dataset preview, sample visualization, and direct dataset comparison features. Future versions will include domain filters (medical, satellite, finance), dataset license checking, and automatic preprocessing suggestions based on the selected ML model. We also aim to deploy it as a public web app for students and researchers worldwide.
Built With
- conversational-ai-design
- gemini-api-(gemini-3-/-gemini-flash)
- google-ai-studio
- prompt-engineering
- structured-prompt-templates
- web-based-ui


Log in or sign up for Devpost to join the conversation.