-
-

Logo
-

Fully responsive
-

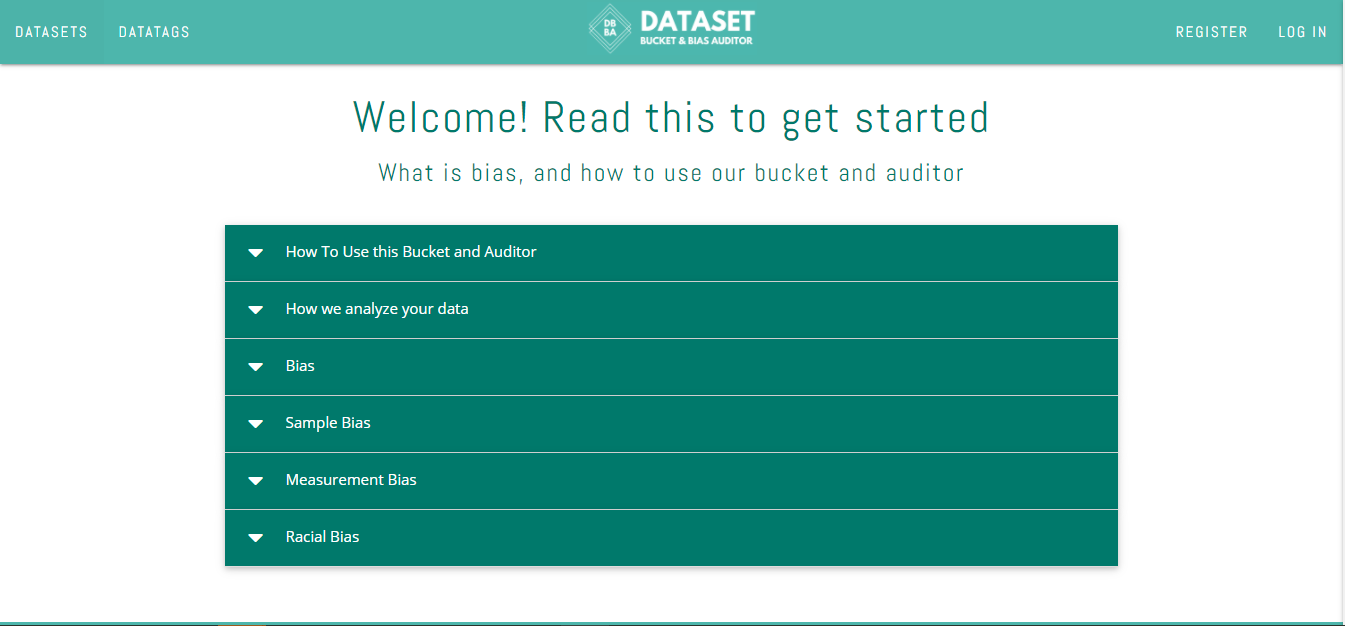
Home page, with about section
-

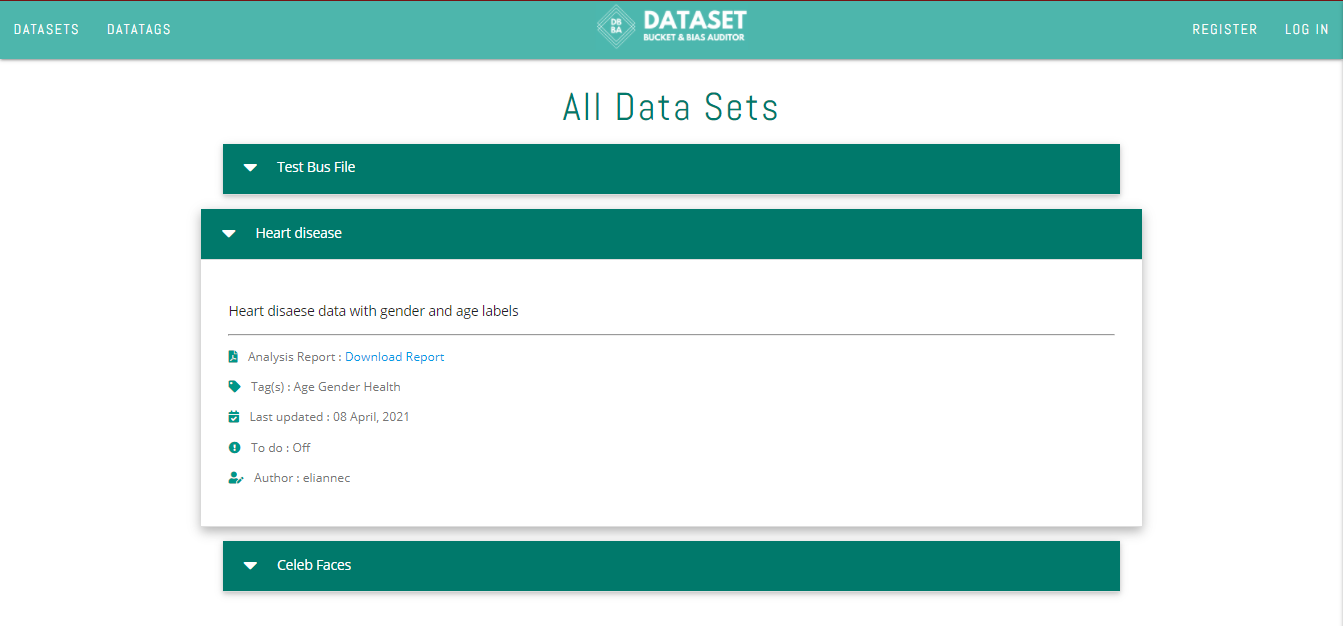
All datasets
-

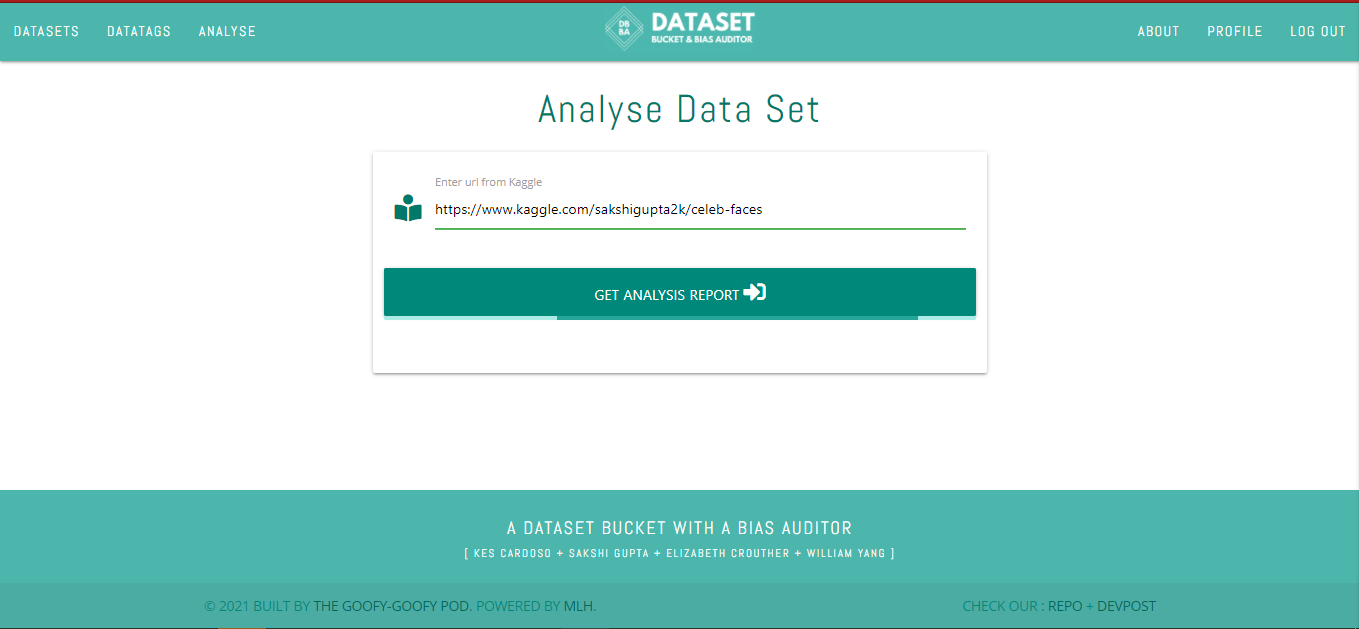
Analyse a dataset from Kaggle
-

Skin tone generated report
-

Numeric report
-

Tags
-

Query datasets by tags
-

Register new user







DATASET BUCKET & BIAS AUDITOR

Check out our project on Heroku!
About
A dataset bucket and a machine learning bias auditor 📈, fully responsive web-app built on Python, with Flask, the MaterializeCSS UI grid system and the Kaggle API.
Based on a CRUD (Create, Read, Update and Delete) database system to generate, store and display dataset structures.
You will be able to find and read reports from a wiki styled list of information about data containing population and demographic subjects.
👩 👳🏾♂️ 👱🏻♀️ 🧔🏾 👩🏼🦰 👨🏿🦳
Motivation
The whole world is data-driven.
However, data can often be misleading, inaccurate, or unrepresentative. When this biased data used in analytics or ML models, it not only produces inaccurate results but also results in disastrous implications for minority groups and classes.
To confront this dangerous problem, we built a web app that analyzes a dataset for bias, and also suggests possible changes you can make to improve the quality of your dataset. 📊
Technologies used
- MongoDB - a document database (stores data in JSON-like documents) with a horizontal, scale-out architecture that can support huge volumes of both data and traffic.
- Materialize - a modern front-end framework (responsive and mobile-first, similar to Bootstrap) that helps developers build a stylish and responsive application.
- Python - an interpreted, high-level and general-purpose programming language, great for database structured projects.
- Pip - a package manager for Python, that allows developers to install and manage additional libraries and dependencies that are not distributed as part of the standard library.
- Flask - a Python framework that depends on the Jinja template engine and the Werkzeug WSGI toolkit.
- Heroku - used for app deployment, Heroku is a platform as a service (PaaS) that enables developers to build, run, and operate applications entirely in the cloud.
- Git - a version control system for source code management; it allows tracking file changes and coordinating work on those files among multiple people and machines.
- GitHub - a open-source code hosting platform for version control and collaboration. It lets developers work remotely and together on projects from anywhere.
We used a lot of python libraries for building this project. Know more about them from LIBRARIES.md.
App Walkthrough

1. OPEN THE APP
Head on to our app deployed on Heroku.

You will see a WELCOME screen, it has the same basic instructions to get started and what you can expect from the app.
2. DATATAGS
In the data tags tab, you can find various tags associated with the reports uploaded on the app.

By clicking the view button on any of the available tags, you can see the dataset, analytical reports, and other information about the TAG.

3. DATASETS
The datasets tab has the list of all the datasets, to which an analytical report was generated. It is presented in the form of an accordion collapsable styled list, so you can click on any dataset you wish to explore and all the information related to that particular dataset will be displayed.

You can view the author, the development status, tags associated, and an option to download the analytical report.
4. REGISTER / LOG IN
Using the register tab you will land on the registration page, where you can create an account on this app.

If you are already a user of our app, head on the log in page.
💟 By being a registered user of our app, you will have access to upload new datasets to the app and generate reports for those.
5. ANALYSE
After logging into the app go to the * analyze* tab. You will see a menu to enter the kaggle URL. After adding a valid Kaggle dataset URL. Click on GET ANALYSIS REPORT.

Currently we are accepting .json, .csv, .png, .jpeg and .jpg files for ananlysis.
You will see a progress bar till the report gets generated. Once it stops, the report gets downloaded automatically by the name of report.pdf.
IMAGES: .png, .jpeg, .jpg

CSV FILES: .csv
The following report is generated when we insert this dataset from Kaggle to analyze: https://www.kaggle.com/ronitf/heart-disease-uci

It would have all the details related to your dataset and what all improvements are possible.
📩 Project Installation and Local Deployment
Prerequisites
Install python3 and pip3 in your machine
Create an account on Kaggle
Installation
Download or clone this project into your local workspace
Create a virtual environment using the command:
Python3 -m venv venvAfter running this command, the folders will be automatically set up on your workspace.
Activate your python interpretor using the command:
source venv/bin/activate: mac.\venv\Scripts\activate: windowsInstall Flask using the command:
pip3 install Flaskand all the required dependencies with:
pip3 install -r requirements.txt
Local Deployment
Create an
env.pyfile to keep your sensitive data secret.Open
env.pyand enter the following:import os os.environ.setdefault("SECRET_KEY", "secret_key_here") os.environ.setdefault("MONGO_URI", "value_from mongoDB_here") os.environ.setdefault("MONGO_DBNAME", "value_from mongoDB_here")Wire up Kaggle
Kaggle API allows the developer to download datasets directly from the terminal.
- Make sure you have a kaggle account
- Follow these steps to download
kaggle.jsonfiles, which helps to run the API:
- Go to the **Account** tab in your Kaggle profile and scroll to the **API** section. - Click **Create new API Token**. This will download the `kaggle.json` file, add it to the `/.kaggle` path. _For more complete and detailed instructions on how to use the Kaggle API, visit [Kaggle's documentation](https://www.kaggle.com/docs/api#getting-started-installation-&-authentication)._ _If you are on macOS/linux, and you need help getting to your ~/.kaggle/ folder, follow these instructions: [Kaggle installation on macOS/Linux](https://adityashrm21.github.io/Setting-Up-Kaggle/)_Wire up MongoDB and its functionalities with Flask, by installing
flask-pymongoanddnspython. Use:pip3 install flask-pymongopip3 install dnspythonRun the
app.pyin debug mode as a flask application or use the following command:python3 -m flask runto see the project in your locally deployed
httpaddress.You may need to install the following packages to enable all the commands and functionalities:
pip3 install reportlabpip3 install statisticspip3 install sklearn
Heroku Deployment
Fulfil all Heroku requirements by chequing and freezing your dependencies and by creating a Procfile:
You can run these two commands to fulfill the purpose:
pip3 freeze > requirements.txtecho web: python app.py > Procfile
You may need to install gunicorn. For a good tutorial, check this youtube tutorial
Commit and push your changes.
Create a new app from your Heroku dashboard.
Add your environmental variables to Heroku, by going to Settings, and then to Config Vars, and enter the sensitive information from your MongoDB and your
env.pyfile:import os os.environ.setdefault("SECRET_KEY", "your_secret_key_here") os.environ.setdefault("MONGO_URI", "value_from mongoDB_here") os.environ.setdefault("MONGO_DBNAME", "value_from mongoDB_here")From your Heroku dashboard, wire up your Heroku app to your git repository, by going to:
- **Deploy** > **Deployment Method** > click: **Connect to GitHub**
- Search your repo from the dropdown, and connect
- Choose a branch to deploy your changes
- Deploy your branch and view the app
References
🔸 If you want to test run the project on your local computer, follow the guidelines in installation guide.
🔸 If you wish to contribute to the existing project, follow the guidelines in CONTRIBUTION.md.
Challenges
- Encountering bugs when deploying on Heroku
- Accounting for different formatting of different datasets and types of files (JSON and CSV)
- Ensuring that the app works for both macOS and Windows
- Learning about lots of new technologies and languages for our team, including Python, Flask, HTML, CSS, Javascript, Matplot, file parsing, and data analysis
- Working in different time zones
Lessons / Takeaways
- Plan more in advance instead of diving into code headfirst
- Deploy on Heroku earlier
- Spend less time getting the program to run on different files, but do more analysis for one specific file
Accomplishments / Contributions
- Overall, we are proud to have completed a tough project and develop a functional web app that effectively parses files, handles multiple types of datasets, and generates PDFs!
- What are we proud to accomplish / what did we work on?
- "Gaining a better understanding of Python, and having a first real dive in data analytics — it changed how I see machine learning forever!" -Kes
- "Learning to use python better and parsing with pandas database, integrating back + front end, and deploying on Heroku!" -Elizabeth
- "Working with images and extracting useful info out of it to generate reports!" -Sakshi
- "Parsing files, generating histograms, and connecting the analysis to the PDFs was super exciting for me!" -Will
Next Steps
- Implement more advanced metrics and recommendations for dataset analysis
- Allow users to upload their own datasets in addition to datasets on Kaggle
- Work on getting more files accepted, like .txt, etc
Contributors
Navigate
Thank You! ✨
Built With
- bias
- css
- ethical-data
- flask
- html
- javascript
- machine-learning
- python
- social-good





Log in or sign up for Devpost to join the conversation.