-
-
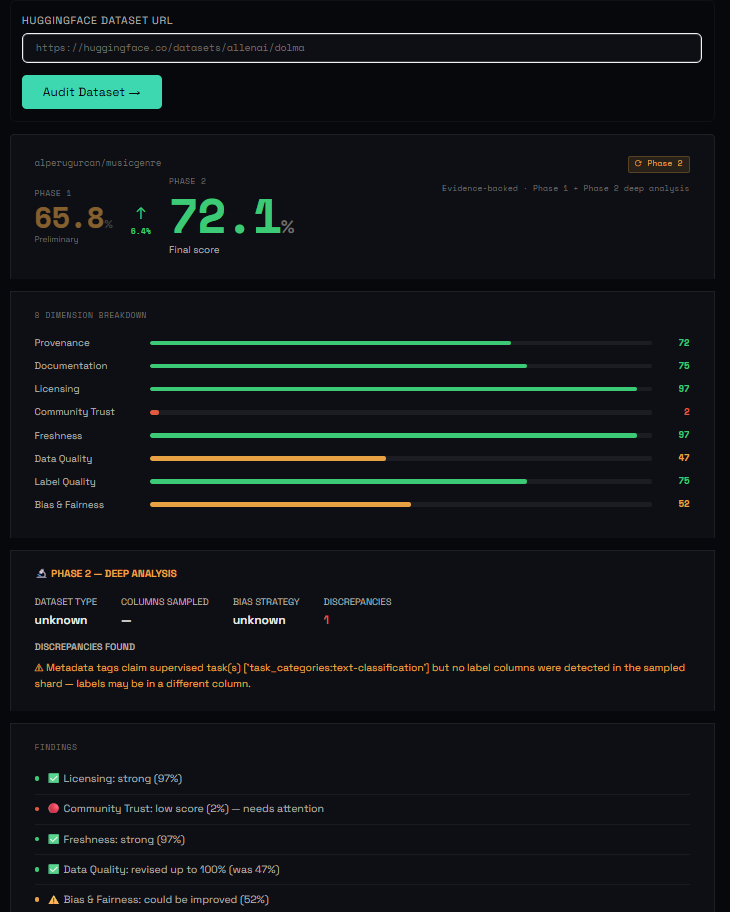
UI - Run an audit
-
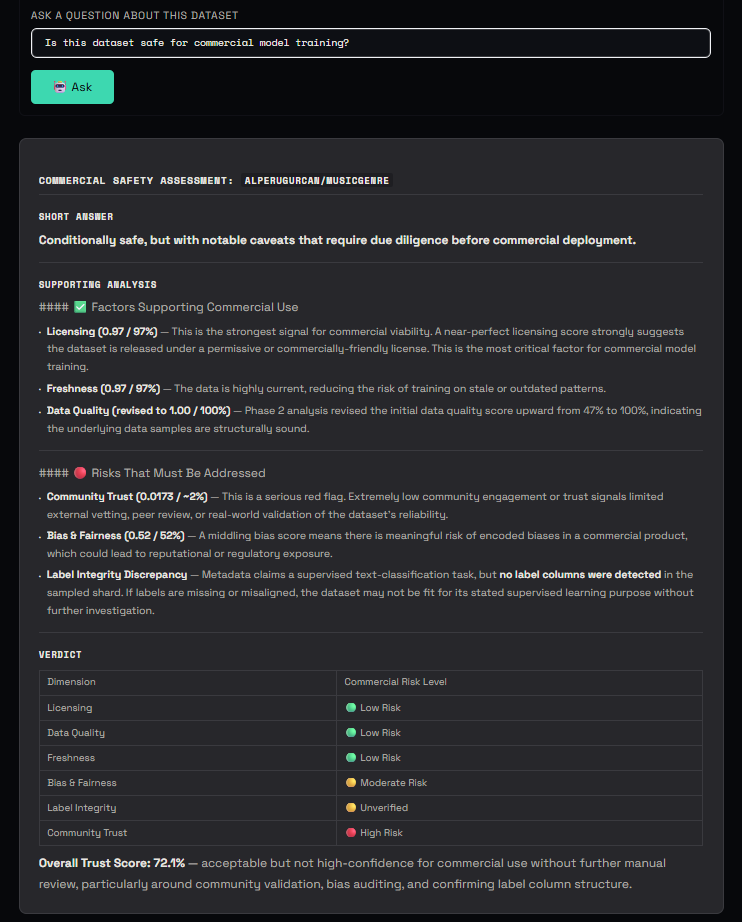
UI - Ask about this dataset
-
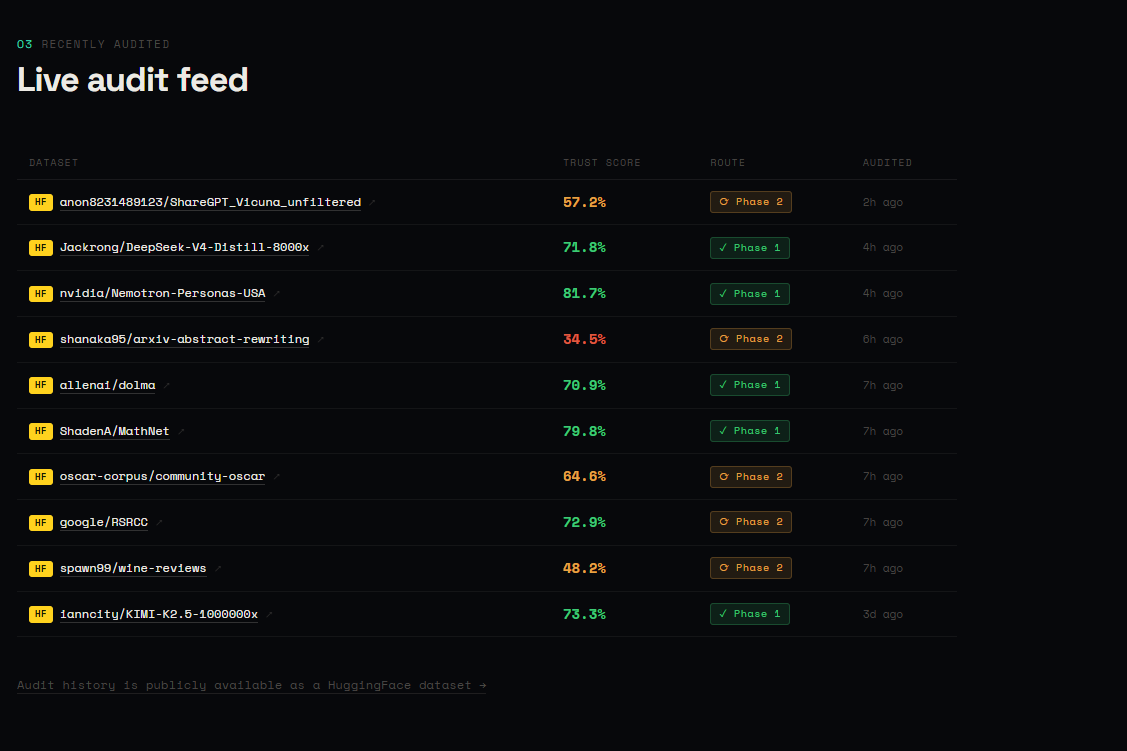
UI - Recently audited
-

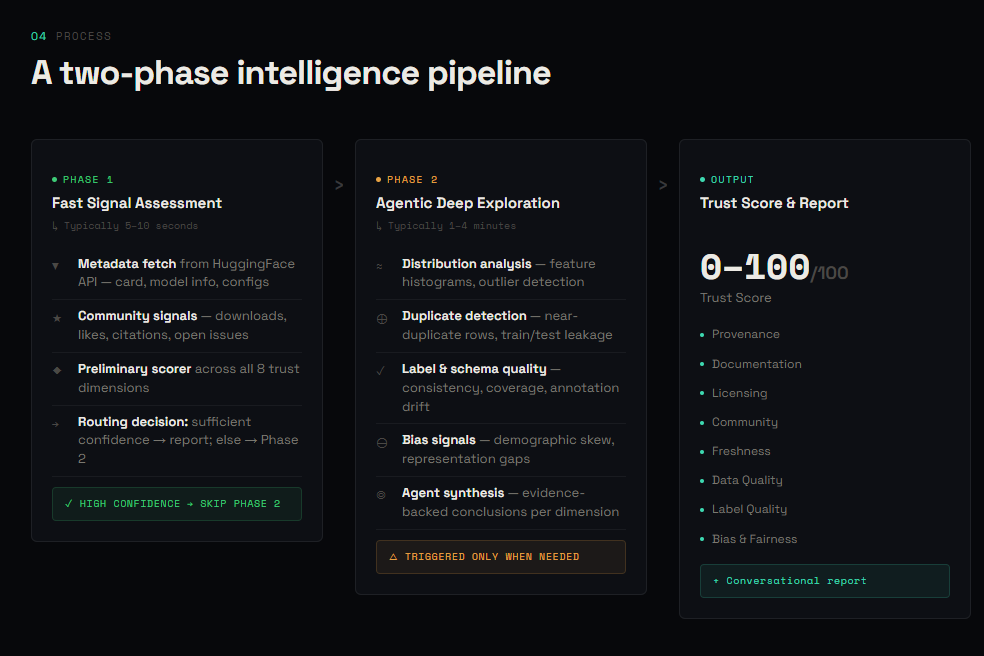
UI - Process overview
-

Zerve Cancas
-
Architecture

Dataset Trust Auditor — Hackathon Submission
Inspiration
HuggingFace hosts over 1 million datasets. Most teams consume them without knowing what they're actually getting — whether the license permits commercial use, whether the data card accurately describes the contents, whether there's class imbalance that will bias a model, or whether the dataset has any meaningful community validation at all.
We've seen what happens when teams train on datasets they don't understand: models that are biased, brittle, or legally exposed. The tooling to assess dataset trust before training simply doesn't exist in a form that's fast, accessible, and evidence-backed.
The Dataset Trust Auditor was built to close that gap.
What it does
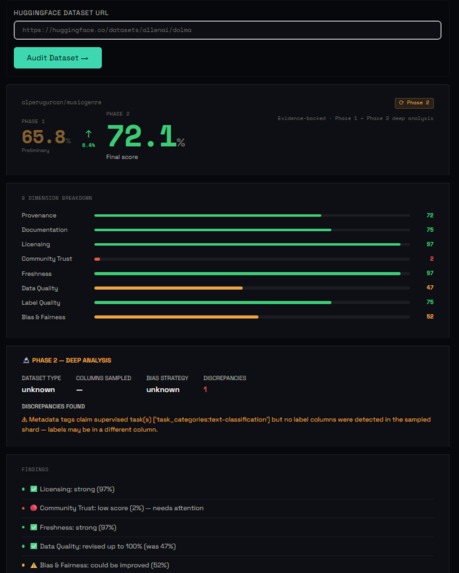
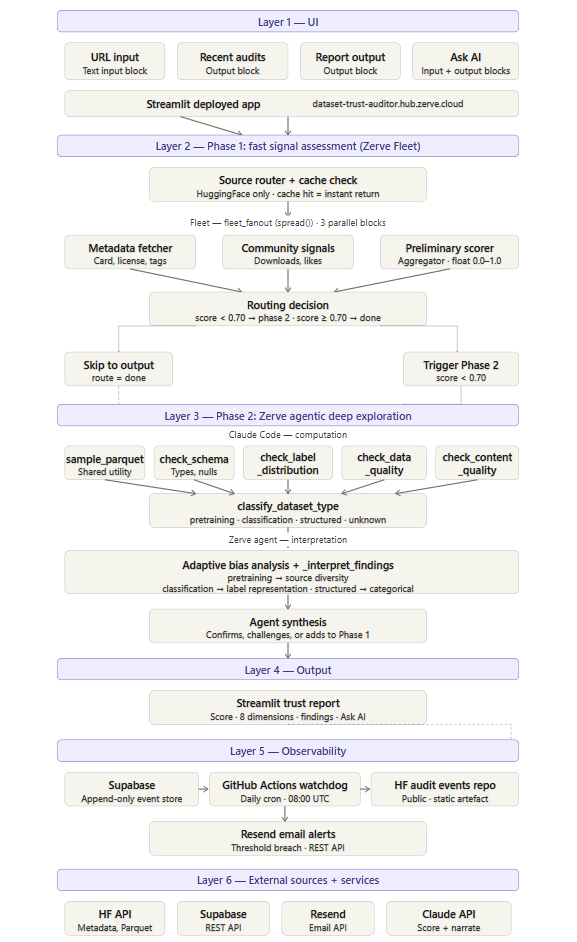
Dataset Trust Auditor is a two-phase AI pipeline that audits any HuggingFace dataset and produces a trust score across 8 dimensions: Provenance, Documentation, Licensing, Community Trust, Freshness, Data Quality, Label Quality, and Bias & Fairness.
Phase 1 — Fast signal assessment (seconds) Metadata fetch and community signals run in parallel via Zerve Fleet. A preliminary scorer evaluates all 8 dimensions from the HuggingFace API response and produces a composite trust score with a confidence flag. High-confidence datasets (score ≥ 0.70) get an immediate report. Lower-confidence datasets trigger Phase 2.
Phase 2 — Agentic deep exploration (minutes) A Zerve agentic notebook samples up to 1,000 rows of actual Parquet data and runs six analysis functions: schema inspection, label distribution, data quality checks, content quality, dataset type classification, and adaptive bias analysis. The bias analysis adapts to the dataset type — a pretraining corpus gets source diversity and language distribution analysis; a classification dataset gets label representation checks. A Zerve agent synthesises all findings against Phase 1 scores, confirms or challenges the preliminary assessment, and produces a revised trust verdict with traceable evidence.
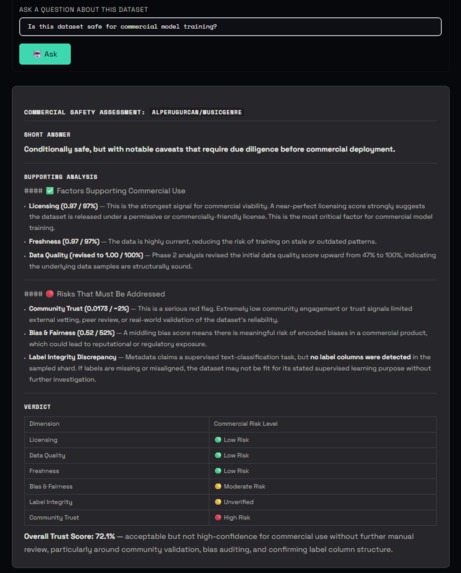
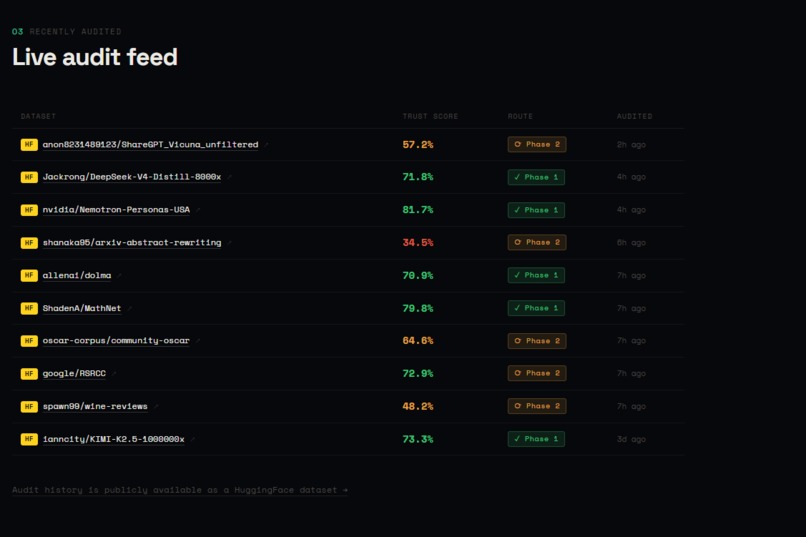
Output A trust score (0–100) with confidence label ("High confidence" or "Evidence-backed"), 8 dimension bars with colour-coded severity, a findings panel with green/amber/red signals, and an Ask AI sidebar grounded in the actual audit data. Every audit is logged to a public HuggingFace dataset and a Supabase observability store.
How we built it
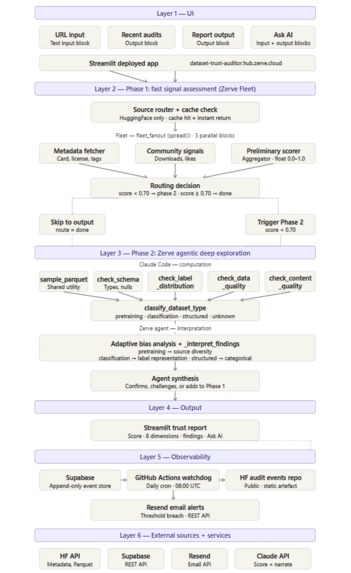
Architecture A 20-block Zerve canvas: 17 connected blocks + 3 standalone.
Core and UI pipeline (14 blocks):
dataset_url_input → url_router → cache_check → fleet_fanout → [metadata_fetcher ‖ community_signals] → preliminary_scorer (Aggregator) → routing_decision → [audit_event_writer ‖ phase2_notebook] → agent_synthesis → report_generator → dataset_trust_report → report_output
Ask AI branch (3 blocks): question_input → ask_ai_chatbot → response_output
Standalone blocks (3 blocks): app_home · watchdog · recent_audits_output
Build split We applied a deliberate principle throughout: Claude Code owns computation, Zerve agent owns interpretation. All Python logic blocks (URL routing, metadata fetching, scoring rules engine, cache, watchdog) were written in Claude Code and tested locally with pytest against saved HuggingFace API fixtures — zero Zerve credits spent on Python debugging. The Zerve agent handled canvas scaffolding, Fleet wiring, Phase 2 agentic analysis, agent synthesis, and the conversational report.
Tooling
- Zerve — canvas development, Fleet parallel execution, agentic notebooks, Streamlit deployment, hosting
- Claude Code — all deterministic Python block logic, local testing
- Claude — architecture decisions, prompt engineering, governance documentation
- HuggingFace Hub — dataset metadata API, Parquet streaming for Phase 2, public audit events artefact
- Supabase — append-only observability event store (error rates, latency, cache efficiency)
- GitHub Actions — daily watchdog cron for pipeline health monitoring
- Resend — watchdog email alerts
- pytest + pytest-mock — local unit testing with fixture-based HF API responses
- Claude Design - design of the application UI, export in HTML5/CSS3
Governance Every significant decision was documented in an ADR (Architecture Decision Record) log — 20 entries covering platform choices, build tool splits, storage pivots, and scope changes. An issue log captured 19 discoveries made during the build, from wrong interface contracts to credit overruns to Zerve platform constraints not covered in documentation. This governance discipline was not overhead — it was what kept a solo developer coherent across a multi-week build using two AI coding agents simultaneously.
Deployed app A self-contained Streamlit app replicating the full Phase 1 + Phase 2 pipeline in Python, deployed via Zerve and accessible at dataset-trust-auditor.hub.zerve.cloud. The UI was designed with Claude Design to produce a modern, product-quality interface rather than a default Streamlit layout.
Challenges we ran into
Zerve credit consumption was higher than estimated A single Phase 3 wiring and debugging session consumed 22 credits in 6 minutes against an estimate of 15–25 credits for the entire phase. This forced an immediate strategy change: all Python logic moved to Claude Code (zero credits), the Zerve agent was reserved only for tasks where its canvas context awareness added genuine value, and every Zerve session was preceded by a fully-specified prompt and working prototype code.
Two AI agents sharing a codebase
Working with Claude Code and the Zerve agent simultaneously on the same canvas created unexpected conflicts. The Zerve agent modified blocks that Claude Code had written, sometimes reverting tested logic or introducing the dir() anti-pattern for variable access. The resolution was a strict protocol: Claude Code writes to files, Zerve agent writes to canvas YAML — with a Git sync checkpoint before every Zerve session and a mandatory diff review after.
Zerve has no native KV store
The original design assumed a REST-based KV store accessible via ZERVE_KV_URL. This didn't exist. Discovered mid-build when both cache_check and audit_event_writer silently returned skipped on every run. Resolved by pivoting to JSON files on the Zerve file system — and then again to HuggingFace Hub (for the deployed app's shared audit feed) and Supabase (for append-only observability events).
Zerve canvas and deployed app are isolated environments The canvas pipeline and the Streamlit deployment run in separate containers with separate filesystems. Variables set in one environment are not visible in the other. Canvas execution cannot be triggered from the deployed app. This required porting the full Phase 1 + Phase 2 pipeline to self-contained Python in the deployed app — the canvas remains the authoritative Zerve-native experience, the deployed app is an independent reimplementation of the same logic.
Ephemeral deployment filesystem
Every Stop + Deploy cycle wipes the Streamlit container filesystem, clearing audit_events.json and leaving the Recent Audits feed empty. Resolved by moving to HuggingFace Hub as the shared persistent store — reads are unauthenticated HTTP GET, writes use the Hub commit API with a write-scoped token.
Bias analysis on pretraining corpora
The initial check_bias_signals function used keyword presence (gender, race, age, religion) to detect demographic coverage. Testing against allenai/dolma revealed the fundamental flaw: web crawl text naturally contains these terms at high frequency, producing a misleading score of 0.80 that is indistinguishable from a dataset curated for demographic fairness. Resolved by replacing the fixed function with classify_dataset_type — a schema inspector that returns the dataset type, which the Zerve agent uses to run adaptive bias analysis appropriate to the dataset (source diversity for pretraining corpora, label representation for classification datasets).
Accomplishments that we're proud of
A genuinely useful tool that works on real datasets
The pipeline produces meaningful, differentiated trust scores for real HuggingFace datasets — allenai/dolma scores 87% (high confidence, Phase 1 only), cheungbh/EStreamVGGTDSEC scores 21% (evidence-backed, Phase 2 triggered, zero documentation and licensing). The scores are grounded in actual data signals, not hardcoded.
The computation / interpretation split The architectural principle that Claude Code owns computation and the Zerve agent owns interpretation turned out to be genuinely powerful — and generalisable. Every Phase 2 analysis function is deterministic, testable, and zero-cost to iterate. The agent's reasoning is applied once, at the most informed point in the pipeline, with access to all Phase 1 and Phase 2 signals simultaneously.
The audit events dataset is itself a HuggingFace dataset A tool that audits HuggingFace datasets produces its audit trail as a public HuggingFace dataset. Every audit run by anyone contributes to a shared, queryable record of dataset quality across the HuggingFace ecosystem. This recursive quality was not planned — it emerged from the storage constraints and turned out to be one of the most interesting properties of the system.
20 ADRs and 22 issues documented in real time The governance documentation is not a retrospective — it was written during the build, capturing decisions and discoveries as they happened. The ADR log includes entries that directly contradict earlier decisions (ADR-016 superseded by ADR-017 within 24 hours), which makes it an honest record of how the architecture actually evolved rather than a sanitised post-hoc narrative.
Full pipeline in a solo, credit-constrained build Phase 1 + Phase 2 + deployed app + observability + watchdog + public audit dataset, delivered solo in a few weeks with a fixed credit budget. The credit constraint forced architectural discipline that produced a cleaner system than an unconstrained build might have.
What we learned
Agentic development requires explicit governance Working with two AI coding agents simultaneously (Claude Code for implementation, the Zerve agent for canvas work) on the same codebase without protocols leads to conflicts. The agents don't coordinate — they overwrite each other's work. The solution was not technical but procedural: strict tool boundaries, Git sync checkpoints, and prompt discipline that includes explicit constraints like "do not modify any Python files other than X."
Assumptions are more dangerous than bugs The most costly issues in the build were not code bugs — they were unverified assumptions: that Zerve had a native KV store, that the deployed app and canvas shared a filesystem, that Fleet blocks would infer parallelism without a dedicated fanout block. Each assumption cost at least one Zerve agent session to discover and resolve. The fix is not cleverness — it's verification before building.
Credit budgeting is a genuine architectural constraint A fixed Zerve credit budget forces the same trade-offs that production cost constraints do: what gets built versus what gets deferred, where agent reasoning is worth paying for versus where deterministic code suffices, when to iterate versus when to accept the current state. This constraint produced better architecture than an unconstrained build would have — every Zerve agent session had to earn its cost.
The computation / interpretation principle generalises The decision to separate deterministic computation (Claude Code, pytest, zero cost) from contextual interpretation (Zerve agent, credits, once per audit) turned out to be a reusable architectural principle applicable to any pipeline that mixes deterministic data processing with LLM reasoning. It is not specific to this project.
Documentation is load-bearing when context switches between tools
CONTEXT.md — the implementation reference that Claude Code reads at the start of every session — was the most important file in the project. When it drifted from reality (wrong block names, wrong interface contracts), Claude Code wrote code against wrong specifications. When it was accurate, sessions started immediately productive. In a multi-agent, multi-tool project, shared context documents are not documentation — they are infrastructure.
What's next for Dataset Trust Auditor
Multi-source routing
The pipeline architecture already supports multiple URL types via url_type routing — HuggingFace was the only source implemented for MVP. Kaggle, Zenodo, UCI, and government data portals are the natural next additions, each requiring a dedicated metadata fetcher and community signals block.
Scheduled dataset monitoring A dataset that scores 85% today may score 60% after a significant update. A watchdog that monitors saved datasets and alerts when trust scores drop materially — already partially built via GitHub Actions — would make the tool genuinely useful for teams with ongoing dataset dependencies.
REST API and CI/CD gate
A POST /audit?url= endpoint that returns a structured JSON trust report would allow Dataset Trust Auditor to be used as a gate in ML training pipelines — reject training runs if the dataset trust score falls below a configurable threshold.
Deeper bias analysis The current bias analysis is adaptive but shallow — source diversity and language distribution for pretraining corpora, label representation for classification datasets. A more sophisticated implementation would use demographic classifiers, cross-reference known bias benchmarks, and produce specific, actionable recommendations rather than signals.
Community trust signals beyond HuggingFace Downloads and likes are imperfect proxies for quality. Cross-referencing datasets against academic citations (papers that use this dataset), known benchmark appearances, and expert endorsements would produce a richer community trust signal.
The audit events dataset as a research resource
The public HuggingFace audit events dataset (nicolas-brieuc/dataset-trust-auditor-events) will grow with every audit run. At scale, it becomes a research resource — a queryable record of dataset quality trends across the HuggingFace ecosystem, useful for studying how dataset quality correlates with community adoption, licensing patterns, and domain coverage.
")

Log in or sign up for Devpost to join the conversation.