-
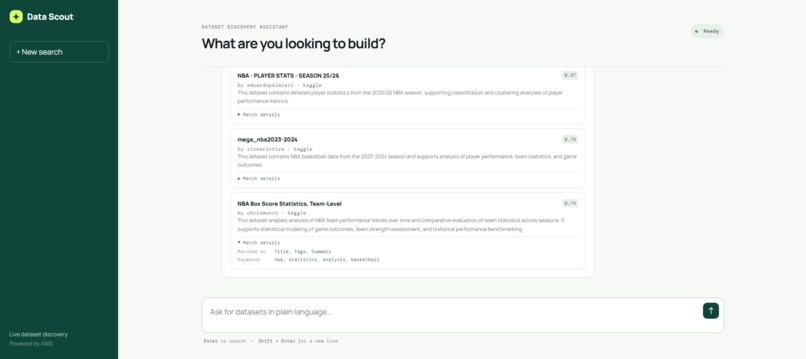
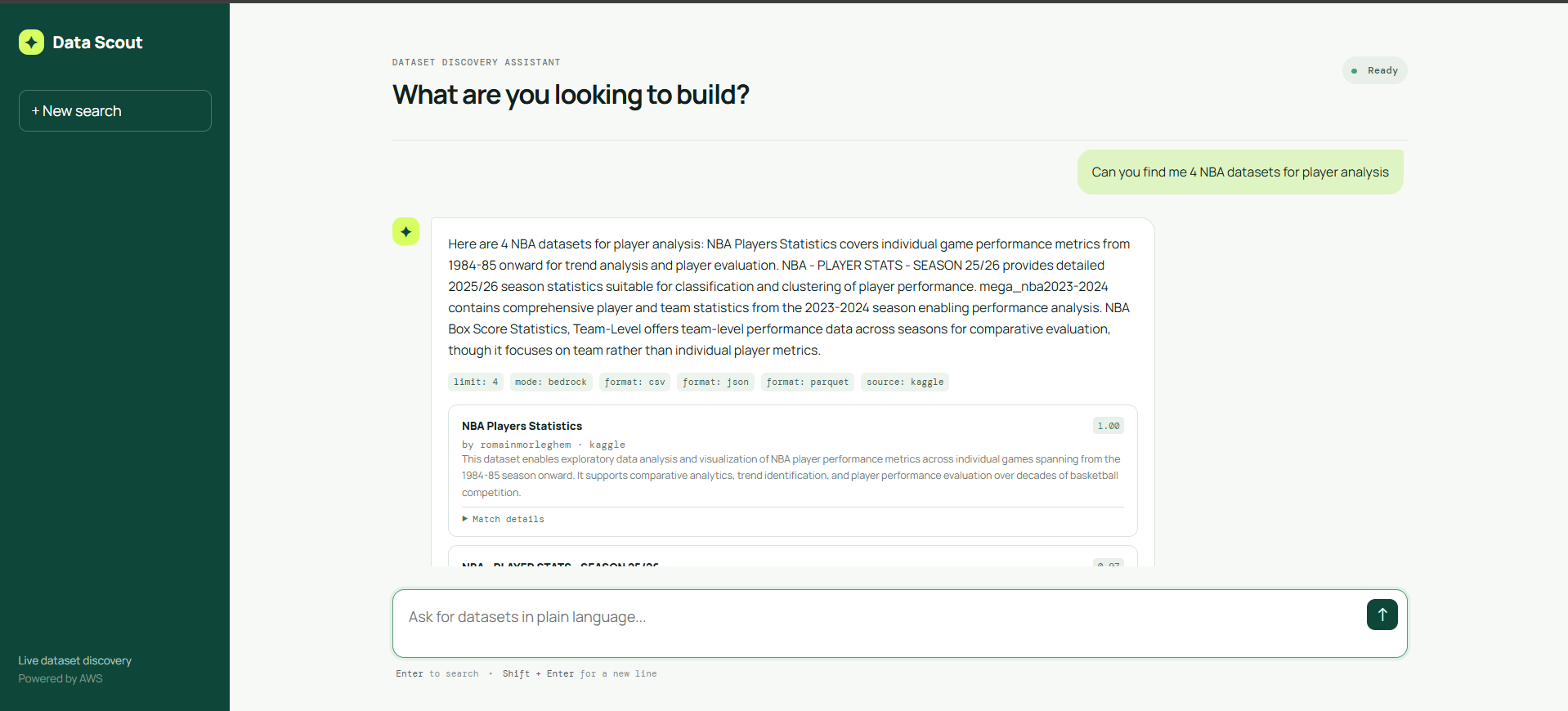
Extended screenshot of result view, and if you click on the name of dataset, it opens to the webpage of the dataset itself.
-
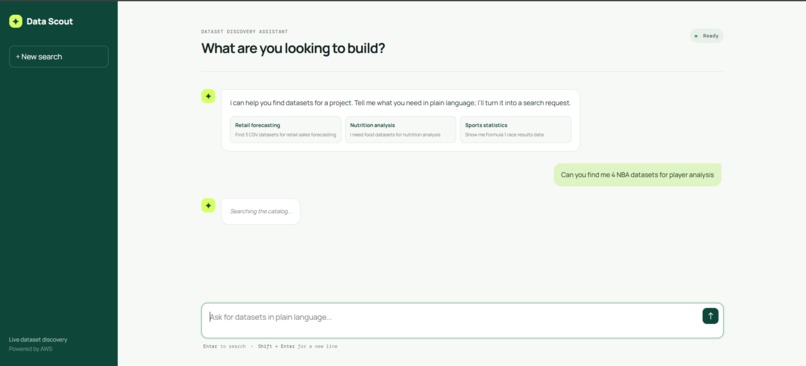
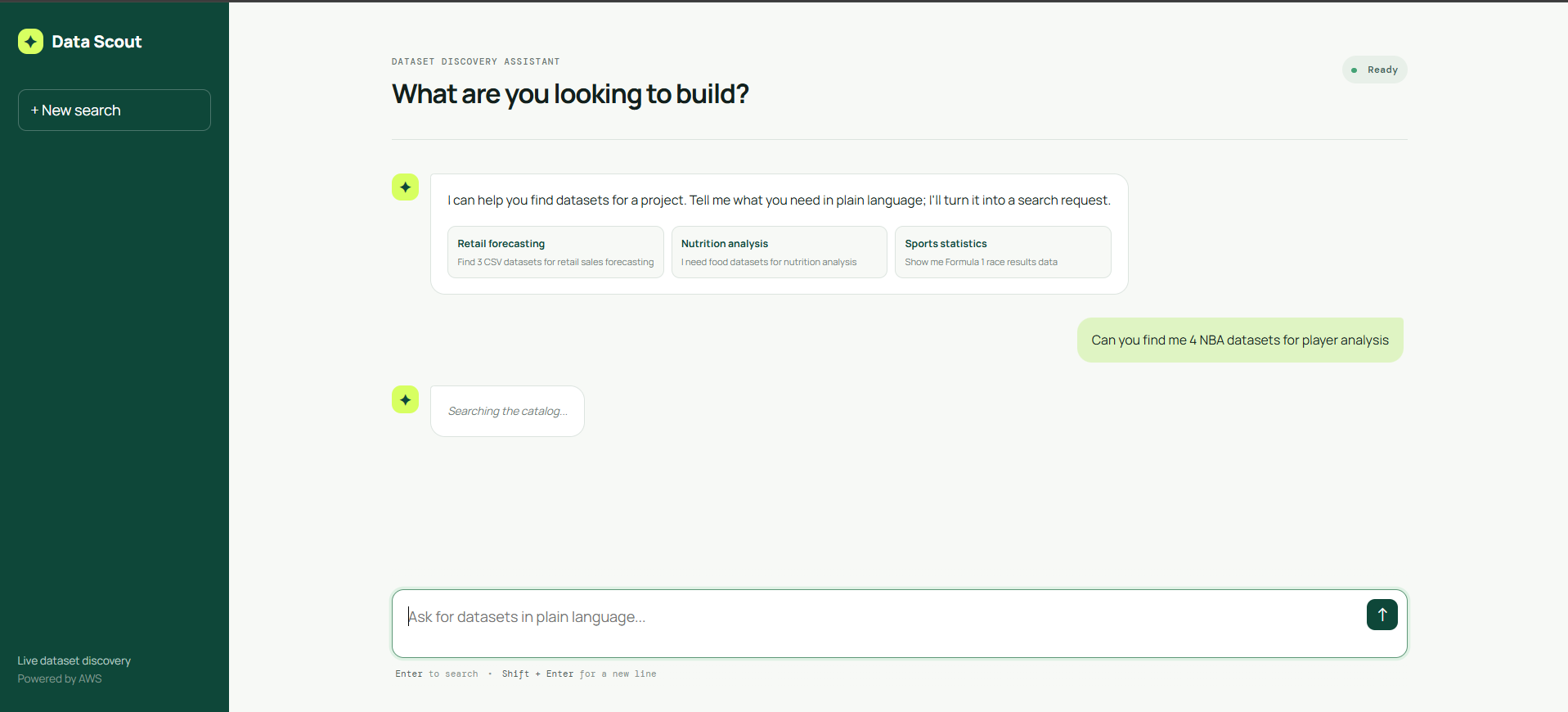
Prompt any type of dataset you want (and any amount/type)
-
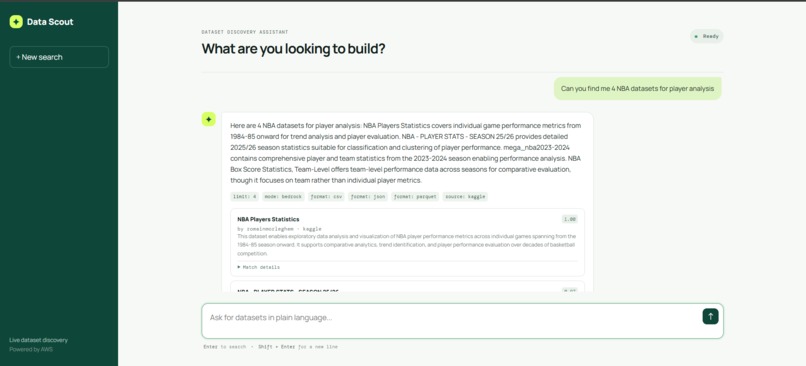
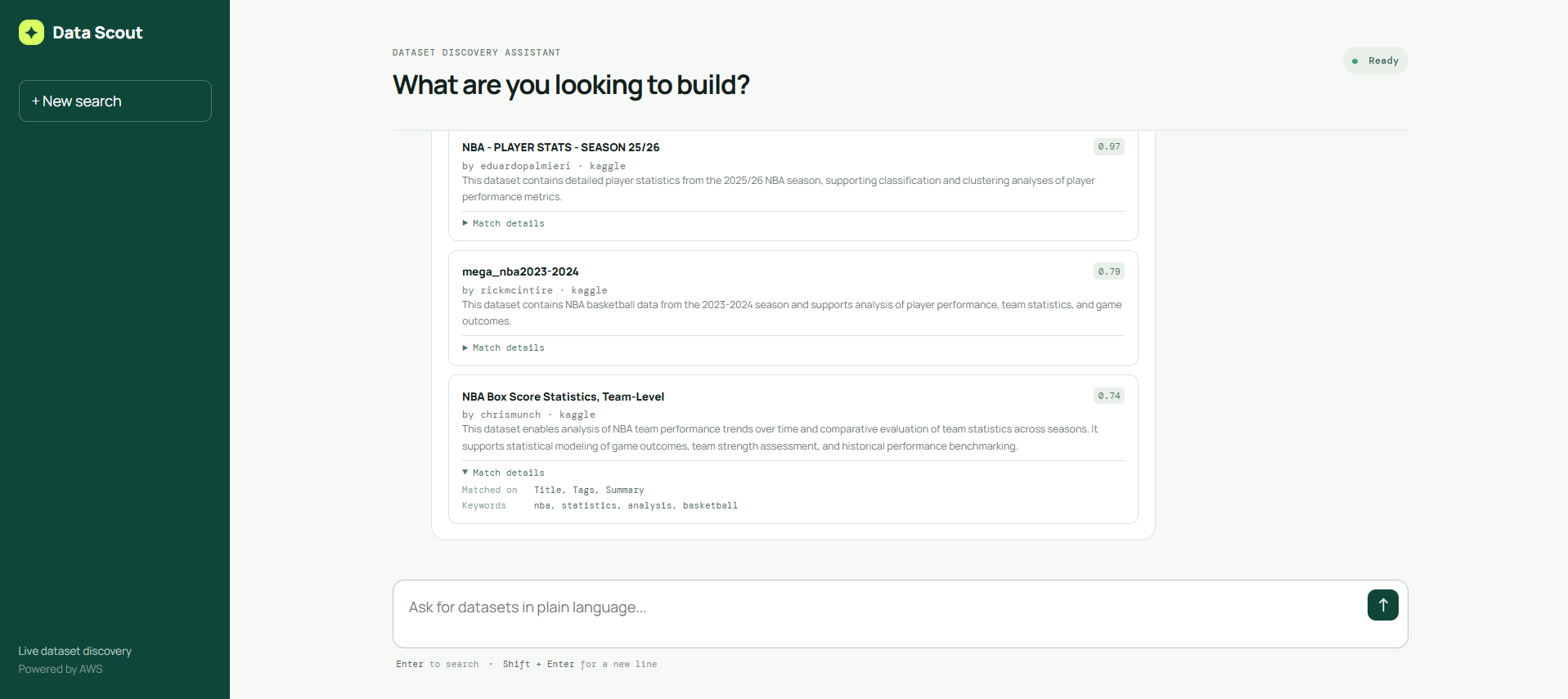
Returns a list view of results and summary of the datasets identifying match parameters and scoring, justifying the match.
Inspiration
Finding the right dataset is often harder than building the model that uses it. Search portals can return hundreds of links, but they do not always explain whether a dataset fits a project, contains the needed fields, or is suitable for a particular analysis. We wanted to make dataset discovery feel conversational without making it ungrounded: users should be able to ask for “3 NBA datasets for basketball analysis” or “Formula 1 race strategy data,” then receive real, traceable dataset recommendations rather than AI-invented answers.
What it does
Data Scout is chat-based dataset discovery assistant.
A user describes what they need in plain language. The application: Interprets the request into a safe search plan using Claude Opus on Amazon Bedrock. Searches a live OpenSearch index of enriched Kaggle & Hugging Face metadata. Returns ranked dataset recommendations with canonical Kaggle & Hugging Face links, summaries, match details, files, schema fields when available, and an AI-generated summary of the result set. Falls back safely to deterministic keyword search if AI interpretation is unavailable or invalid. The catalog currently contains more than 1,600 indexed dataset records and updates automatically as the crawler adds or changes metadata.
How we built it
We built Data Scout as a serverless AWS application. A Python crawler collects public Kaggle & Hugging Face dataset metadata. Amazon Bedrock enriches metadata with structured domain/data-type labels and factual use-case summaries. DynamoDB stores the authoritative dataset records. DynamoDB Streams trigger an index worker that projects active records into an OpenSearch datasets-v1 index. API Gateway routes chat search requests to a Python Lambda. Claude Opus converts user text into a strictly validated search plan: keywords, suggested result count, formats, sources, licenses, required fields, and recency. Lambda builds a bounded OpenSearch query, returns only public result fields, and uses IAM-signed requests. A local static chat UI displays results, match details, schema/file metadata, and a short AI summary of the returned datasets.
Chat UI → API Gateway → Query Lambda → Bedrock search plan ↘ OpenSearch → ranked datasets Crawler → DynamoDB → Stream → Index worker → OpenSearch
Challenges we ran into
The biggest challenge was balancing natural-language flexibility with trustworthy retrieval. Broad queries such as “housing prices” can accidentally match unrelated crypto or stock datasets because words like “price” are common. We built a read-only ranking evaluation harness to compare candidate ranking strategies before changing production behavior. We also encountered sparse metadata: not every dataset has populated file formats or schema fields, so treating AI-suggested formats as hard filters could hide otherwise useful results. We therefore keep model suggestions as soft ranking signals while preserving explicit user filters as hard constraints. Other challenges included handling pagination safely, keeping DynamoDB and OpenSearch synchronized, configuring signed OpenSearch access, avoiding leaked internal search details, and making the chat UI readable as result lists grow.
Accomplishments that we're proud of
Built an end-to-end, live pipeline from crawler to DynamoDB to OpenSearch to chat UI. Indexed more than 1,600 dataset records. Made the AI grounded: Claude interprets and summarizes, while OpenSearch retrieves real dataset records. Added safe fallback behavior when Bedrock fails or returns invalid output. Kept results explainable through canonical links, match details, schema/file data, and factual summaries. Created a ranking evaluation harness so retrieval changes can be tested before deployment. Built a polished chat experience with independent scrolling and compact dataset cards.
What we learned
We learned that AI is most useful here as an interpreter and assistant—not as an unbounded search engine. Claude is good at turning a vague request into structured intent and explaining a set of real results. OpenSearch is good at fast retrieval over known metadata. Combining the two gives a more reliable experience than asking a model to generate recommendations on its own. We also learned that retrieval quality depends as much on metadata quality and evaluation as it does on model prompts. More datasets improve coverage, but better enrichment, relevance tests, synonyms, and ranking logic are necessary to avoid noisy results.
What's next for Data Scout
Ingest more sources beyond Kaggle & HF . Improve metadata coverage for files, schemas, licenses, and tags. Use the ranking benchmark to test synonym-aware and phrase-aware retrieval improvements. Add richer filtering controls while keeping chat as the primary interface. Host the frontend for a shareable public demo. Add budget alarms, operational dashboards, and production CORS controls.
Built With
- amazon-api-gateway
- amazon-bedrock
- amazon-cloudwatch
- amazon-dynamodb
- amazon-opensearch-service
- amazon-web-services
- anthropic-claude
- aws-lambda
- bedrock
- css
- html
- javascript
- lambda
- python



Log in or sign up for Devpost to join the conversation.