Problem Statement
AI systems are no longer just answering questions. They are quietly learning how we think, how we search, what we trust, what we ignore, how we verify, and how we decide.
Every prompt, correction, follow-up search, and browsing pattern becomes behavioral data. Over time, that data turns into a high-value memory layer: not just what you asked, but how you operate.
The problem is that this memory is usually captured inside closed AI platforms.
- Users do not truly see what is being inferred about them.
- Users do not control how that behavioral memory is stored.
- Users cannot easily move that memory to another provider.
- Switching providers means losing the compounding value of learned context.
So the real problem is not only model lock-in. It is behavioral lock-in.
Why This Matters
This is important because behavioral data is becoming the new moat.
In older software platforms, lock-in came from files, messages, or customer records. In AI systems, lock-in is moving one layer deeper:
the learned model of how a person works
That includes things like:
- which sources they trust
- whether they verify before trusting an answer
- whether they prefer technical docs or summaries
- how they compare products before buying
- how they learn new topics
- when an AI answer is "good enough" versus when they keep searching
That memory becomes more valuable every day it is accumulated. And if it stays trapped inside one provider, the user loses leverage.
This matters now because AI platforms are consolidating fast. If users do not get ownership over this behavioral layer early, the default future is one where:
- platforms accumulate lifelong behavioral memory
- users cannot audit it clearly
- users cannot port it cleanly
- the cost of leaving becomes too high
Core Thesis
Behavioral memory should belong to the user.
Not to a single model vendor.
Not to a hidden proprietary memory store.
Not to a platform that can infer endlessly without portability.
Users should be able to:
- capture behavioral signals locally
- structure them into portable memory
- inspect what is being learned
- carry that memory across providers
That is the problem we are addressing.
Inspiration
We were inspired by a simple shift in how AI products are evolving.
The first generation of AI products competed on model quality: better benchmarks, bigger context windows, faster answers. But the next layer of competition is not just the model. It is the memory around the model.
As people work with AI more often, the system starts learning patterns:
- what kinds of sources they trust
- what kind of answers they verify
- how they research
- how they shop
- how they learn
- what they ignore and what they care about
That memory compounds. It becomes the real value. And right now, most users have almost no visibility into it, no ownership over it, and no portability if they want to switch providers.
That felt like an important problem to prototype against right now. We wanted to build an early version of infrastructure that says: if behavioral memory is being created, it should be captured in a form the user can own, inspect, and move.
What it does
DataSelf captures behavioral interaction data locally and structures it into portable memory layers.
At a high level, the system:
- Collects browser telemetry from real user activity.
- Groups that activity into task-oriented human + agent sessions.
- Derives higher-level behavioral memory from those sessions.
- Exports that memory into open JSON files that another provider or agent can reuse.
Instead of treating memory as a black box inside one model vendor, DataSelf breaks it into a hierarchy:
- raw telemetry
- sessions
- patterns
- preferences
- trust profile
- persona profile
This makes the memory legible and portable.
For the demo, we focused on three user behaviors:
- research intent
- shopping preference
- learning style
The system can capture signals from those workflows, infer patterns over time, and visualize them in a dashboard.
How we built it
We built DataSelf as a local-first Node.js system with a lightweight but explicit memory pipeline.
1. Telemetry collection
We launch or connect to a real Chrome session using Playwright over CDP and observe browser activity:
- navigation events
- search queries
- scroll depth
- dwell time
- clicks
- network request activity
Those events are grouped into prompt-action pairs and written into a local SQLite database.
2. Human + agent session capture
We then built a session layer on top of raw telemetry.
Instead of only storing explicit thumbs-up or thumbs-down feedback, the system records:
- behavior before an agent answer
- the agent answer itself
- behavior after the answer
- implicit outcome signals
This was important because in the real world, users do not rate every answer. What they do is continue searching, verify, refine, compare, or stop. That behavior is the actual signal.
3. Memory hierarchy builder
We added a rule-based memory builder that reads the SQLite store and generates exportable memory layers:
sessions.jsonpatterns.jsonpreferences.jsontrust_profile.jsonpersona_profile.jsonmemory_bundle.json
The memory builder translates repeated sessions into patterns, patterns into preferences, and preferences into a more compact persona-style summary.
4. Visualizer
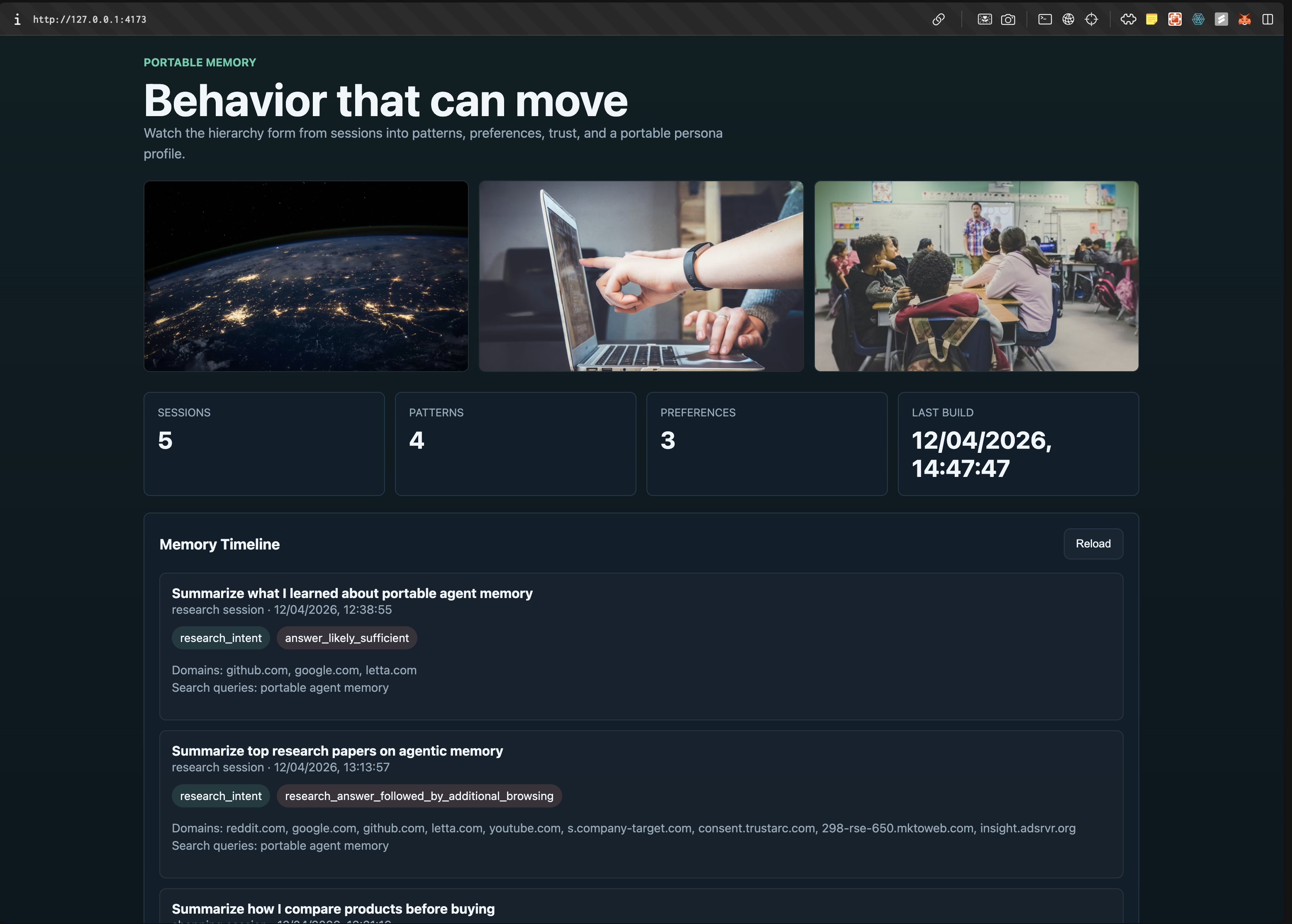
Finally, we built a local visualizer to make the memory hierarchy visible over time. The dashboard shows:
- memory timeline
- extracted patterns
- inferred preferences
- trust profile
- persona profile
- session drill-down
This gives us a concrete way to show that portable behavioral memory is not just an abstract idea. It can be inspected and carried.
Challenges we ran into
The hardest challenge was deciding what kind of memory actually matters.
Raw browser telemetry is easy to collect, but raw events alone are not very meaningful. We had to figure out how to move from low-level signals like navigation and scroll events into something that actually represents user behavior.
Another challenge was avoiding a fake feedback loop. At first, we considered a system where the user explicitly rates every agent answer. That was too unrealistic. Most people are not going to do that in normal usage. So we shifted toward implicit behavioral evidence, which made the system much more believable but also harder to model.
We also had to think carefully about portability. A lot of memory systems are useful only because they remain internal and proprietary. We wanted a representation that was simple enough to export, structured enough to be useful, and explicit enough that another agent could load it later.
On the implementation side, there were practical issues too:
- browser instrumentation across real pages
- structuring event data cleanly
- defining session boundaries
- distinguishing before-answer and after-answer behavior
- making the hierarchy readable instead of noisy
And because this is a local-first prototype, we also had to build a workflow that is transparent enough for a demo while still feeling like it points toward a real product.
Accomplishments that we're proud of
The biggest thing we are proud of is that DataSelf does not stop at telemetry collection. It actually demonstrates the beginning of a portable behavioral memory system.
We are proud that we built:
- a working browser telemetry collector
- a human + agent session model
- an implicit-outcome based memory flow
- a multi-layer memory export pipeline
- a local dashboard to inspect what is being learned
We are also proud that the architecture reflects the thesis of the project. SQLite is the working memory store, but the real portability layer lives in exported JSON files. That separation matters because it reinforces the core product idea: user memory should not be trapped in a proprietary runtime.
And finally, we are proud that the system is opinionated. It is not trying to be a generic AI wrapper. It is trying to answer a specific question:
what would it look like if users actually owned the behavioral memory created by working with AI?
What we learned
We learned that behavioral memory is much more concrete than it first appears.
Once you start capturing sessions, you quickly see that meaningful patterns emerge from very ordinary activity:
- where a user goes first
- what they check after an answer
- which sources they return to
- when they stop
- when they refine
We also learned that the right abstraction is not just "chat history" or "saved prompts." The more useful abstraction is behavior around tasks.
That includes:
- user prompt
- agent answer
- pre-answer evidence
- post-answer evidence
- observed behavior
- inferred outcome
That structure feels much closer to how memory should work for portability.
We also learned that confidence matters. If the system only has one or two sessions, it should not pretend to know the user deeply. So even in the prototype, we started treating memory as something that should accumulate gradually and expose uncertainty.
What's next for DataSelf
The next step is to deepen the memory hierarchy and make it more useful across providers.
Short term, we want to:
- capture more sessions across research, shopping, and learning
- improve pattern extraction with better confidence scoring
- separate stable preferences from temporary behavior
- enrich trust profiling with stronger verification signals
- make the persona export easier for another agent to ingest directly
We also want to add a more explicit import story:
- export memory from DataSelf
- load it into a second agent environment
- continue the interaction without losing behavioral context
Longer term, we think DataSelf could evolve into user-sovereign infrastructure for AI memory:
- local behavioral audit trail
- provider-agnostic memory bundle
- portable schema for personal context
- policy and boundary layers for what should and should not be inferred
The big vision is simple:
AI systems are going to learn from us.
The question is whether that learning belongs to the platform or to the user.
We want to make the answer: the user.

Log in or sign up for Devpost to join the conversation.