
Inspiration
Data scientists spend hours hunting through fragmented data portals when they could focus on analysis. We wanted to turn that chore into a conversation by letting users simply ask what they need and receive precise dataset recommendations.
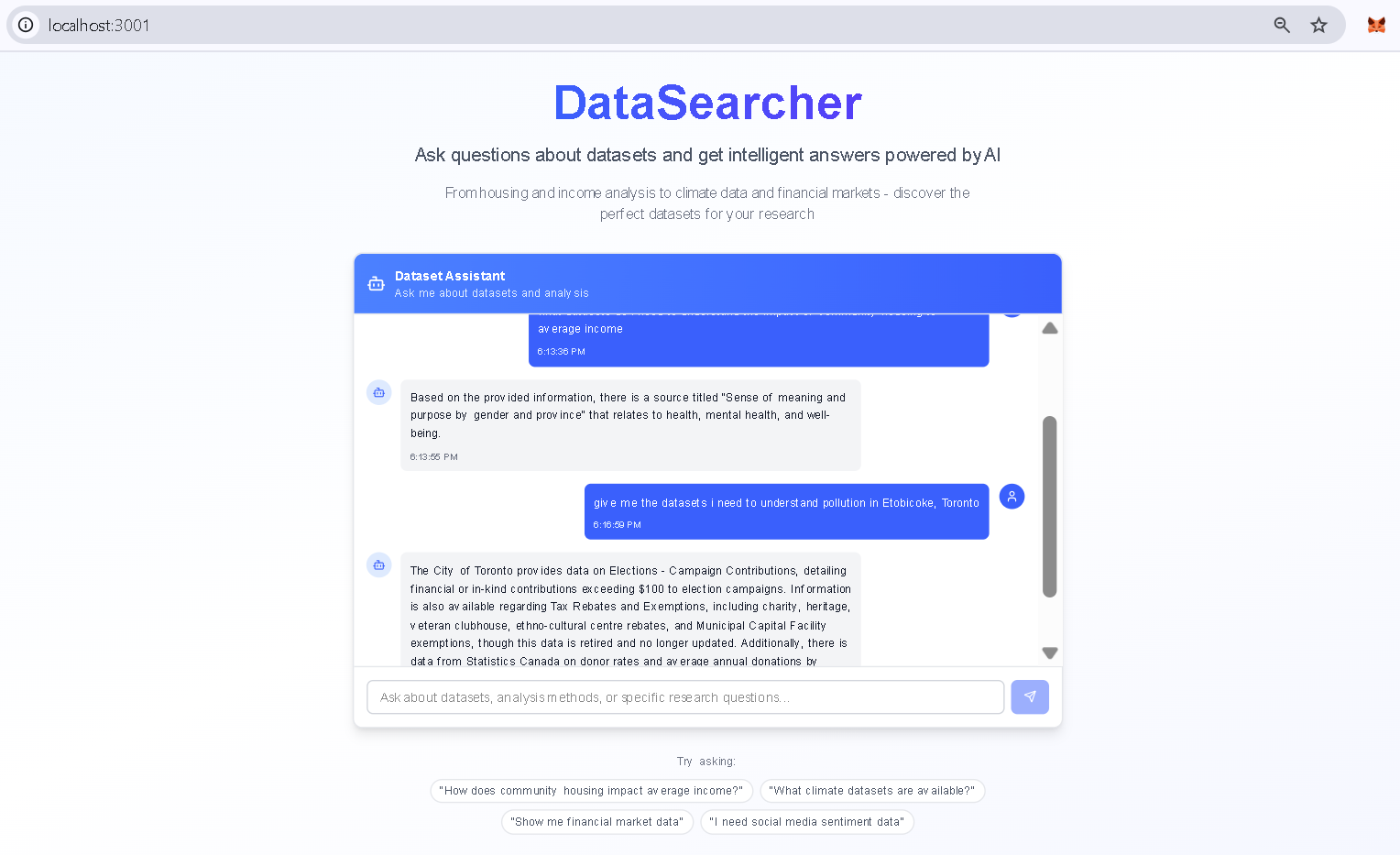
What it does
DataSearcher takes a business question in plain English and instantly returns ranked public datasets. CrewAI agents built on Langchain crawl portals like data.gov and Toronto Open Data to extract schema details and generate semantic embeddings. Those embeddings live in a Google Cloud Storage bucket and drive Google’s RAG Engine semantic search. Users see concise summaries, sample previews, coverage notes and update histories without leaving the app.
How we built it
We scaffolded a NextJS front end offering a single input box and results panel. CrewAI agents orchestrate Langchain pipelines that fetch dataset schemas, descriptions and update frequencies, then call OpenAI embeddings in batches. Metadata and embedding vectors are written to a Google Cloud Storage bucket. Google Cloud Retrieval Augmented Generation Engine serves similarity queries via a Node.js back end using the openai-node library.
Challenges we ran into
Crawling diverse portals meant handling inconsistent field names and rate limits. Generating embeddings at scale required tuning batch sizes to balance latency and cost. Configuring access controls for Cloud Storage and RAG Engine took careful IAM setup. Designing a minimal UI that still conveys rich metadata required iterative feedback.
Accomplishments that we're proud of
We indexed and enriched nearly 100,000 public datasets with AI-generated metadata. Queries now return results in under one second. We built an end-to-end MVP in five hours and recorded a two-minute demo that walks from question to detailed schema view.
What we learned
We discovered best practices for orchestrating AI agents to extract and embed metadata at scale. We deepened our understanding of Google Cloud RAG Engine configuration and cost management. We refined UI patterns for conversational discovery and improved error handling in both crawling and vector search.
What’s next for DataSearcher: AI-Powered Dataset Discovery
We will expand to more open data portals and add dynamic refresh of metadata. We plan to build a feedback loop so users can upvote relevance and retrain embeddings. We aim to introduce inline data previews and exportable result sets. Finally, we will open our code on GitHub and invite the community to contribute new portals and features.
Ask ChatGPT
Built With
- crewai
- gcp
- langchain
- nextjs
- ragengine


Log in or sign up for Devpost to join the conversation.